サービスの安定稼働を阻むサイレント障害
サイレント障害の課題 ~原因分析の長期化~
障害回復までが長期化する理由の2つ目は、サイレント障害においては、原因の究明に時間がかかるという点です。
サイレント障害はエラー・メッセージというかたちで障害個所が通知されないため、どこに原因があるのかを絞り込むことができません。このため、システムを構成するサーバーやネットワークなどのコンポーネントごとの管理者/専門家が集まり、発生している障害の内容から原因個所を大まかに推測して、サーバーのCPU使用率やネットワーク負荷などの性能情報を調べます。原因個所が推測できない場合や推測が外れた場合には、さらに時間をかけてすべての性能情報を調べることになります。
具合的にどのように性能情報を調べるのか、先の事例をベースに説明します。
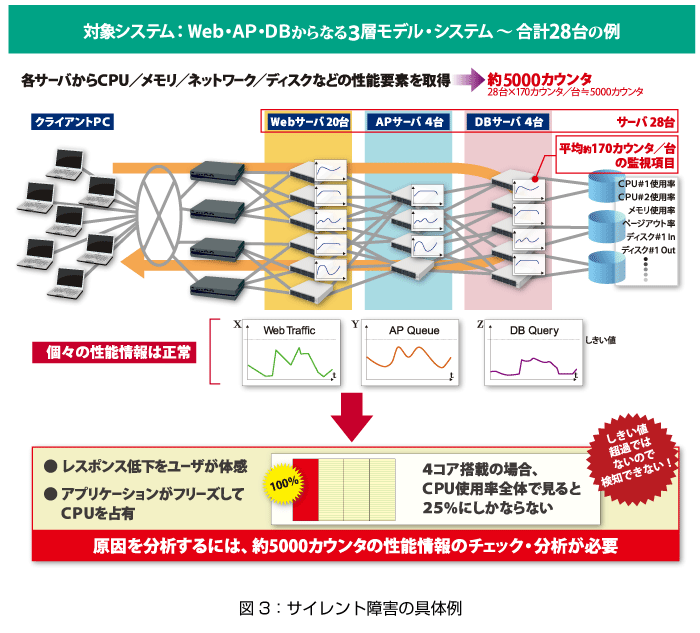
先の事例では、Web、AP、DBの3階層モデルは、それぞれ20台、4台、4台の合計28台から構成されています。このシステムでは、障害を検知するため、もしくは障害の発生時に原因個所の分析を行うために、システム監視ソフトを利用してCPUの使用率やネットワークの負荷などの性能情報を1台あたり平均170項目ほど取得していました。
サイレント障害の原因を分析するため、各コンポーネントの専門家を集めて、各性能情報の時系列の推移(トレンド)や性能情報間の関係性などを分析することになりました。しかし、1台あたり平均170もの性能項目を取得するとなると、全体を分析するためには170項目×28台で約5000個の性能情報を取得し、その中から原因を探すことになります。
項目数を見ただけで分析が長期化することが容易に想像できますが、グラフ化などのテクニックを駆使しても、人手での分析には限界があります。高スキルな技術者がいたとしても、膨大な情報量となるため、時間をかけざるを得ません。これが、原因の究明に時間かかる原因となっています。
サイレント障害の課題解決に向けて
このように、サイレント障害では、障害発生の把握が遅れるという危険性とともに原因分析に多大な時間と労力を要します。この結果、障害回復までの期間が長期化し、運用管理コストを大きく引き上げる原因となっています。
また、検知が遅れれば遅れるほどサービス・レベルは低下し、原因分析に時間がかかって短期間での回復が難しいことから、クラウド・サービスの耐障害性を保証するにあたっては大きな課題となるでしょう。
サイレント障害は、決して珍しいケースではありません。現状では障害全体の2割程度に過ぎませんが、システムの複雑さに起因する障害のため、マルチベンダー/マルチプラットフォーム/仮想化などの要因によって複雑化するクラウド指向データセンターでは、今後その割合は増加していくことが予想されます。
一方、クラウド指向データセンターは企業活動にとって重要となるITシステム基盤なので、これまでと同等以上のミッション・クリティカル性が求められます。つまり、クラウド指向データセンター上で提供されるサービスのサービス・レベルの維持には、安定運用を維持するための、従来以上の仕組みの構築が必要になってきます。
NECでは、従来のシステム監視ソフトでは実現できなかった「サイレント障害」を、独自の「インバリアント分析技術」によって自動で検知/分析できる仕組みとして、システム性能分析ソフト「WebSAM Invariant Analyzer」を提供しています。
次回は、この分析技術の仕組みと「WebSAM Invariant Analyzer」による具体的な分析方法・導入効果について解説します。






