導入しやすい工数見積もり手法とは
協調フィルタリング技術を用いた工数見積もり
重回帰分析よるモデル構築においても、欠損値を補完したり、欠損値を含まないデータセットを作成したりする方法は開発されている。しかし、それらはあくまでも少数のデータ欠損を想定したものであり、欠損率が高いソフトウエア開発データに適用しようとするところに無理がある。よってデータは欠損しているものとして、それでも(それなりに)見積もりが行える方法を検討する方が現実的である。
協調フィルタリング(Collaborative Filtering)は、amazon.comなどで用いられている「推薦システム」の基盤技術の1つである。これは多数存在する書籍、楽曲、記事、Webページなどの中から、ユーザー間の類似性に基づいて、ユーザーごとにその好みに合うと推定されるアイテムを選び出す技術である。
「ある書籍に対して同様の評価を与えているユーザー同士は、ほかの書籍に対しても同様の評価を与えるであろう」と仮定して、対象ユーザーが評価を与えた(複数の)書籍に対して同様の評価を与えているほかユーザー(類似ユーザー)を探し、その類似ユーザーが、高い評価を与えている別の書籍を対象ユーザーに推薦する、というものである。
ただし、ユーザーに評価を与えてもらうと言っても、その対象となる書籍は、販売されている書籍のごく一部にすぎない。評価値を実績データとするならば、ほとんどの書籍には評価が与えられていない、つまり、欠損値だらけということになる。
ここではそれを、ソフトウエア開発の工数見積もりに応用することを考える。すなわち、開発プロジェクトをさまざまな好みを持つユーザーとみなし、プロジェクト特性値をユーザーによって評価が分かれる書籍のようなアイテムとみなす。その上で、プロジェクト間の類似性を、それらプロジェクト特性値の実績データの差異に基づいて評価し、見積もり対象プロジェクトにおいてまだ評価が与えられていない「開発工数」というアイテム(特性)に対する評価値を推定する、というものである。
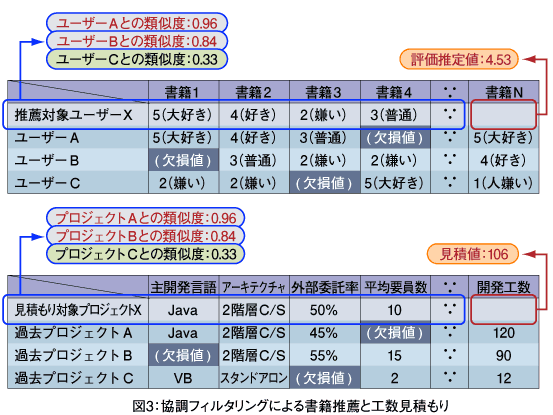
導入しやすい見積もり手法
この手法の最大の特徴は、モデルが構築されることはなく、対象プロジェクトと類似したプロジェクトを探し出し、そこでの実績データを利用するということである。モデルを構築しないという特徴ゆえに、今回冒頭で指摘した1つ目の問題「見積もりモデルの適用可能範囲が狭い」を回避することになる。
このアプローチは、多くのプロジェクトリーダーが、直観的な見積もりや問題解決において行っている手法に近い。プロジェクトリーダーは、どのようなプロジェクトにも適用可能なオールマイティーなモデルや解決策を持っているわけではなく、過去に担当したプロジェクトでの経験や実績データをうまく利用している場合が多い。有能なプロジェクトリーダーほど、経験や実績データを豊富に持っており、見積もり対象プロジェクト向けにそれらをうまくアレンジすることができる、と言ってよいのかもしれない。
エンタープライズ系ソフトウエア開発の見積もりは、「類似プロジェクトからの類推」が32%、「プロジェクトリーダーや担当者の経験」が32%である。協調フィルタリングによる見積もりは、多くのプロジェクトで行われている類似プロジェクトからの類推を系統的に行い、プロジェクトリーダーや担当者の経験を実績データという形で見積もりにうまく利用する一手法と位置付けることができる。プロジェクトリーダー(や見積もり担当者)からすると違和感が少なく、開発現場へのスムーズな導入が期待される。
協調フィルタリングによる見積もりのもう1つの特徴は、データ欠損に非常に強いということである。具体的な適用事例は、次回に詳しく紹介するが、データ欠損率が60%と非常に高い場合でも、重回帰分析などで構築されたモデルよりもはるかに高い見積もり精度を実現することが可能である。しかも、欠損率が高くなっていっても、見積もり誤差が大きく変動することはなく非常に安定している。
これは「見積もりモデルがデータ欠損に脆弱である」という2つ目の問題を回避することになる。一貫したデータ収集体制を整える必要は必ずしもなく、時間とコストを先行投資する必要もない。データ欠損率が60%以上とならないように注意しながら、さまざまなプロジェクトデータをどんどん集積し、また、見積もりに利用していけばよい。
実際の協調フィルタリングによる見積もりでは、名義尺度で表されている説明変数のダミー変数化や、説明変数の値域をそろえるための標準化などが必要であるが、詳細については、紙面の都合で省略するので、文献(http://se.naist.jp/achieve/pdf/157.pdf)を参照されたい。
次回は、協調フィルタリングを用いた工数見積もりの具体的な事例をいくつか紹介する。
なお、本稿の執筆にあたって、以下を参考にした。
Kromrey, J., and Hines, C.: 「Non-randomly missing data in multiple regression: An empirical comparison of common missing-data treatments」『Educational and Psychological Measurement, 54, 3』(1994)
大杉 直樹,角田 雅照,門田 暁人,松村 知子,松本 健一,菊地 奈穂美,「企業横断的収集データに基づくソフトウェア開発プロジェクトの工数見積もり」『SEC journal,5』(2006)
Strike, K., El Eman, K., and Madhavji, N. 「Software Cost Estimation with Incomplete Data」『IEEE Trans. on Software Engineering, 27, 10』(2001)