正確に、確実に情報を検索する!
すべての検索処理を1つの検索エンジンで実現
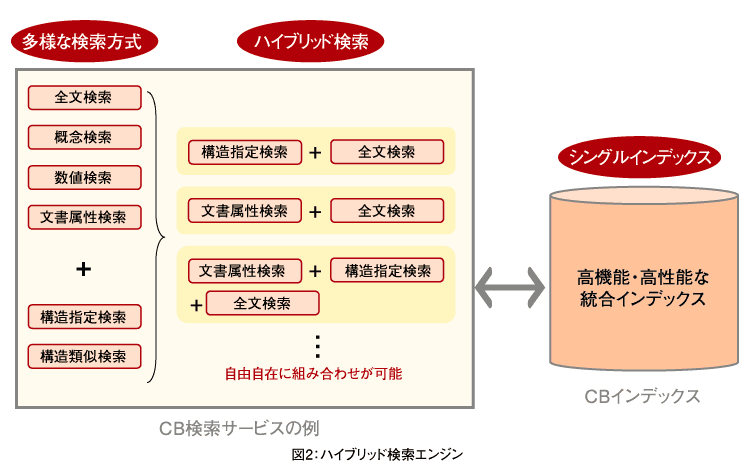
ファイルサーバー検索に適したCBESの特徴は大きく2つあります。「検索のかしこさ」と「システムの拡張性」で、最大のポイントは、多彩な検索処理を1つのインデックスで実現できる「ハイブリッド検索エンジン」(図2)を搭載していることです。
このハイブリッド検索エンジンは、全文検索や概念検索、数値検索、文書属性検索などに加えて、「構造指定検索」および「構造類似検索」と呼ばれる2つの技術を活用しています。
構造指定検索とは、例えばExcelで作成した文書の「日付」という構造を利用して、「2008/1/8」という値が入ったデータを検索する仕組みです。一方、構造類似検索では、例えばExcelで作成した顧客一覧と類似した構造の情報を検索するためのもので、名刺情報や社員名簿など、「氏名」「住所」「電話番号」などの構造が類似している情報を検索するための技術です。
ATOKの日本語処理技術を活用
「漏れがない」「ノイズが少ない」検索を実現するためには高度な日本語処理技術が必要になります。CBESでは、日本語ワードプロセッサ「一太郎」や日本語入力システム「ATOK」の技術を利用することでより高い精度の検索を実現しています。
例えば表記ゆれの統制として「売上げ/売上/売り上げ」や「コンピュータ/コンピューター」、全角/半角などの違いなどを吸収しています。また、「補填/穴埋め/補充」などの同義語や「走る/走れ/走ろう」などの用語の活用による語尾変化、「着色していない/無着色」などの肯定表現と否定表現の区別などがあります。
また「ランキングコントロール」を利用した「かしこい検索」も特長の1つです。ランキングコントロールでは、最新性/オフィシャル度、人気度/便利度、重要度/緊急性、ビジネス価値/業務ルールなどのルールを事前に設定しておくことで、「ベストな情報を推奨する」ことが可能です。1つの検索エンジンで検索ランキングを自由にコントロールすることができます。
こうした高度な日本語処理を実現する技術としてCBESでは、N(V)gram処理と自然言語処理(NLP:Natural Language Processing)の2つの技術を採用しています。
N(V)gram処理では、検索対象を1~n文字ずつに区切りインデックスを作成するNgram処理と文字種ごとに最適なn数を決定するVgram処理を連携した技術を搭載しています。一方、NLPは文書から語句を抽出する高度な形態素解析で、正規化や表記ゆれの吸収、用語の活用形、否定語の区別などを実現しています。