【バグ管理の作法】バグ管理のノウハウ
第2回:紙か? Wordか? Excelか? BTSか?
著者:TIS 栗栖 義臣
公開日:2007/12/11(火)
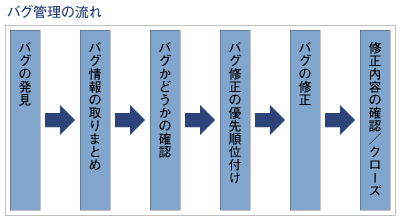
バグ管理の流れ
バグ管理全体の流れは図のようになる。
バグの発見 → バグ情報の取りまとめ
発見されたバグを取りまとめるフェーズである。
バグを発見するのは、テスト中であれば主にテスターであるし、運用中であればエンドユーザや顧客、あるいは運用担当者かもしれない。どこでバグが発見されても、きちんと情報を集約できるようにしておくことが重要である。
ここでのポイントは「取りまとめから漏れてしまうバグが存在しないようにすること」である。
よくあるのは、顧客から修正担当者に直接バグの連絡があり、情報として取りまとめる前に修正し、リリースしてしまう、というケースだ。このような事態が起きると、システム全体のバグ状況を把握できなくなる。加えてその修正によって発生したバグの原因を追跡するのに時間がかかってしまう。
当たり前のように感じるかもしれないが、システム開発の現場によっては、こうした情報整理がされていないことが往々にしてある。
バグの報告については、「バグの内容(具体的に)」「発見者名」「発見日時(アプリケーションにバージョン番号がある場合は、それも記載)」「(Webアプリケーションの場合は)Webブラウザ名、バージョン」が得られるようにすべきである。
バグかどうかの確認 → バグ修正の優先順位付け
報告されたバグが本当にバグであるのかを確認するフェーズである。
まずは、バグの再現性のチェックを行う。報告された状況が再現されることが確認できたら、それが本当にバグであるのかの確認を行う。仕様書に記載されている情報も手がかりになる。
バグであるかどうかの最終的な判断は、プロジェクトによって変化する。バグ管理者だけでなく、仕様を把握しているプロジェクトリーダやテスト管理者、運用管理者などだ。ここでバグと判断されたものについて、優先順位付けを行う。
この「再現性のチェックと優先順位付け」は重要なポイントだ。これについては次回の第3回で詳しく解説していこう。
バグの修正 → 修正内容の確認/クローズ
優先順位に従いバグ修正の担当者を決め、修正を行うフェーズである。
修正が終わったら、修正担当者のチェックはもちろんのこと、発見者もしくは第3者のチェックを入れて、修正内容に問題がなければバグをクローズする。
このとき修正担当者の申告は、修正されていなかったり、あるいは間違った修正を入れてしまったりする場合がある。開発者も人間であるため、間違いは起こすものである。注意して確認しておきたい。  次のページ
次のページ