| ||||||||||
| 1 2 3 次のページ | ||||||||||
| データウェアハウスと汎用RDBMSの違い? | ||||||||||
企業のデータを格納する場合、データベースとして汎用RDBMS(リレーショナルデータベースマネジメントシステム)を思い浮かべる方が多いでしょう。データを活用するという視点から見ると、DWH(データウェアハウス)というシステムが注目されています。汎用RDBMSとデータウェアハウスは、異なるシステムではありますが、「その違いは?」と聞かれると、意外と答えにくいのではないでしょうか。 本連載では、汎用RDBMSとデータウェアハウスの構造的な違いについて、データの分析エンジン「Sybase IQ」を題材に解説し、理解を深めていきます。 | ||||||||||
| データウェアハウスの特性と汎用RDBMSとのミスマッチ | ||||||||||
まず、データウェアハウスと基幹系システムの違いを考えてみましょう。当たり前の話ですが、データウェアハウスの場合、ある1つのクエリが扱う件数が基幹系に比べて圧倒的に多いということがいえます。 ここで注目してほしい点は、汎用RDBMSはロー単位(正確にいえば、ロー全体を格納したページ単位)でしか入出力ができないということです。この方式で大量データを読み込む場合を考えてみます。 図1は、クレジットカードの利用履歴明細をイメージしたテーブルで、カード番号、利用日、店番号、金額の4カラムを持っています。そして、このテーブルに対して、「利用日別の金額合計はいくらか?」というクエリを実行するとします。 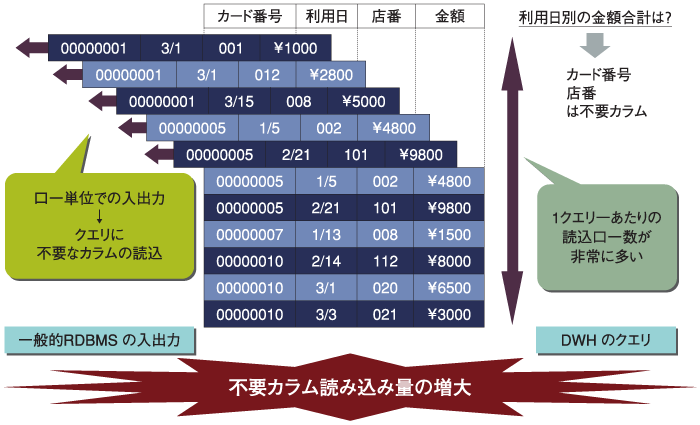 図1:テーブルのイメージ (画像をクリックすると別ウィンドウに拡大図を表示します) この処理は、利用日をキーにしてソート後、利用日が等しい間各ローの金額を足しこむ、という処理になります。逆のいい方をすると、カード番号、店番号は処理には一切必要ないということになります。 しかしながら、ロー単位の入出力であるために、ユーザが好むと好まざるとにかかわらず、これらの不要カラムがメモリ上に読み込まれてしまいます。しかも使用されることはありません。データウェアハウスの場合、1クエリが読み込むローの数は莫大ですから、不要カラムの読み込みも膨大です。 ストレージは使用しないカラムの読み込みに多くの時間をかけ、メモリは必要データ量の何倍もの量を実装する必要があります。そしてCPUは処理能力の多くを必要データ/不要データの選別に消費することになり、実際のシステムでは非常に多くのCPUを必要とします。 結果として、汎用的なRDBMSを使用した場合、多くのリソース(CPU、メモリ、ストレージ)を要する高価なシステムになってしまう割に、性能が得られないという状況を招いてしまします。これがデータウェアハウスを構築運用する上で、パフォーマンス問題の本質的な原因の1つとなります。 では図2でより具体的に説明しましょう。 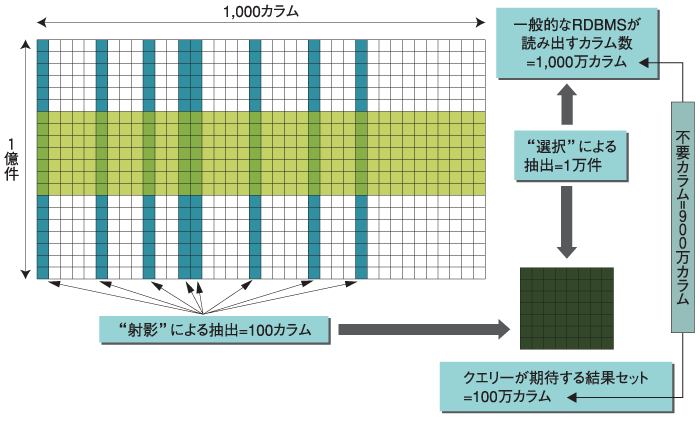 図2:データウェアハウスのイメージ (画像をクリックすると別ウィンドウに拡大図を表示します) ここでは以下のような条件を想定します。
表1:想定条件 このとき、ユーザが期待する結果は、テーブルの中の選択対象ロー(黄色の部分)と、射影対象カラム(青色の部分)の「AND」である緑色の部分となります。この部分のデータ量は、図2の右下に示すように100カラム×1万カラムでのべ100万カラムとなります。 しかしながら、ロー単位の入出力を行う汎用RDBMSでは、1万ロー全体(テーブルの黄色の部分)をハードディスクからメモリ上に読み込むため、実際の読み込みデータ量は、図2の右上に示すように「1000カラム×1万件」で、のべ1000万カラムとなってしまいます。 両者の差である、900万カラムにおよぶ不要カラムの量が与える影響は、以下の通りとなります。
表2:不要カラムが与える影響 このようなことを考えると非常に大きな問題点であることがわかります。大量の不要カラムの読み出し、これが汎用RDBMSを使用する上での問題点の1つです。 次、に別の角度からデータウェアハウスと汎用RDBMSの相性をみてみます。 | ||||||||||
| 1 2 3 次のページ | ||||||||||
技術ホワイトペーパ「情報分析用高速クエリエンジンSybase IQ」 本連載はサイベースが提供している技術ホワイトペーパ「情報分析用高速クエリエンジンSybase IQ」の転載となります。Sybase IQのより詳細な内容については以下のページを参照してください。 http://www.sybase.jp/products/informationmanagement/sybaseIQ_moreInfo.html | ||||||||||
| ||||||||||
| ||||||||||
| ||||||||||
-
人気記事ランキング
-
-
連載

