| ||||||||||
| 1 2 次のページ | ||||||||||
| データ構造の違いをSybase IQで学ぶ | ||||||||||
今回は、Sybase IQに用いられている技術をもとに、データウェアハウスと一般的なRDBMSのデータ構造の違いをみていきます。まずはSybase IQの特徴を紹介し、それぞれの技術について深く掘り下げていきましょう。 | ||||||||||
| Sybase IQの特徴 | ||||||||||
Sybase IQの最も大きな特徴は、垂直パーティションと呼ばれるデータ構造にあります。垂直パーティショニングは、テーブルデータの保持方式とそこに対するアクセス方法を指しています。ここでは、生データがSybase IQデータベースに格納されるまでの3つのプロセスを追いながら説明していきます。 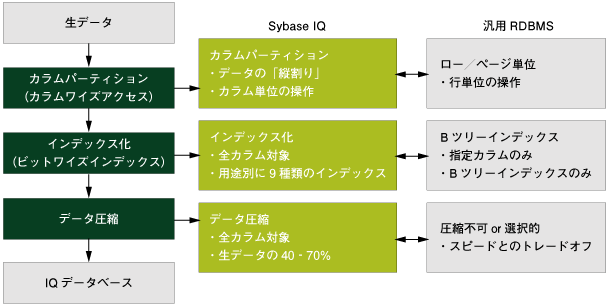 図1:垂直パーティショニングと一般的なRDBMSの違い (画像をクリックすると別ウィンドウに拡大図を表示します) | ||||||||||
| カラムパーティション(カラムワイズアクセス) | ||||||||||
最初のプロセスは、カラムパーティションという、ロー単位に管理されたデータ(Oracle、SQL ServerなどのテーブルデータやCSV形式のテキストファイルなど)を、いわゆる「縦切り」にしてカラム単位にまとめるプロセスです。カラムパーティションされたデータのアクセスをカラムワイズアクセスと呼んでいます。 | ||||||||||
| インデックス化(ビットワイズインデックス) | ||||||||||
次にカラムパーティションされた各カラムの固まりは、Sybase IQ固有のインデックスに変換されます。インデックスは用途別に9種類用意されており、データは最低1つ以上のインデックスに置き換えられます。つまり、Sybase IQにおいてはすべてのデータがインデックスだけで構成されることになります。このインデックス技術はサイベースの特許技術から構成されており、ビットワイズインデックスとも呼ばれています。 | ||||||||||
| データ圧縮 | ||||||||||
インデックス化されたデータは、最後にすべて圧縮されてハードディスクへと書き込まれます。圧縮は読み書きの単位、一般的なRDBMSでいうところのページ(またはブロック)に対して行われます。 それでは、それぞれについてより詳しくみていきましょう。 | ||||||||||
| 1 2 次のページ | ||||||||||
技術ホワイトペーパ「情報分析用高速クエリエンジンSybase IQ」 本連載はサイベースが提供している技術ホワイトペーパ「情報分析用高速クエリエンジンSybase IQ」の転載となります。Sybase IQのより詳細な内容については以下のページを参照してください。 http://www.sybase.jp/products/informationmanagement/sybaseIQ_moreInfo.html | ||||||||||
| ||||||||||
| ||||||||||
| ||||||||||
-
人気記事ランキング
-
-
連載

