システムトラブルを招く3つの原因とその対策を考える
2013年3月21日(木)

障害追求のための基本的な考え方
運用管理に性能監視を追加する理由は、障害の発生をいち早く察知することにある。発生してしまった障害の原因を迅速につかみ、短時間で解決するのはもちろん、場合によっては障害が顕在化する前にその兆候をつかみ、トラブルを未然に食い止めることが可能になる場合もある。ただし、それには適切な情報を収集し、その情報を正しく分析することが不可欠だ。ここでは、トラブルの原因追及の際の基本的な考え方を整理しておこう。
まず、トラブルをその性格から3種に分類してみよう。ここでは、「一般障害」「サイレント障害」「不定期に発生する一時的な障害」に分けて考える。
- 一般障害
- 一般障害はハードウェアの故障や通信回線の断絶など、一般的な“障害”のイメージに当たるものだ。この検出は、実のところ死活監視でも十分対応可能なことが多い。一般的な監視サービスでも、通常は一般障害の確実な検出を目標として提供されている例がよく見られる。
- サイレント障害
- サイレント障害は、疎通や生死といったレベルでは正常と言えるものの、なんらかの問題が発生している状態を指す。パフォーマンスやレスポンスの悪化など、サービスレベル/サービスの品質が低下した状態と言い換えることもできる。これは死活監視ではなかなか発見できず、ユーザーからのクレームによって初めて気づくことが多い障害だ。サイレント障害を迅速に発見するには、リアルタイムの性能監視が不可欠となる。
- 不定期に発生する一時的な障害
- 最後の不定期に発生する一時的な障害は、検出も困難だし、再現性がないことから原因究明も難しい、運用担当者を悩ませることが多い障害だ。迅速に発見することも難しいが、対策としては長期にわたる性能データの収集が役立つことが多い。
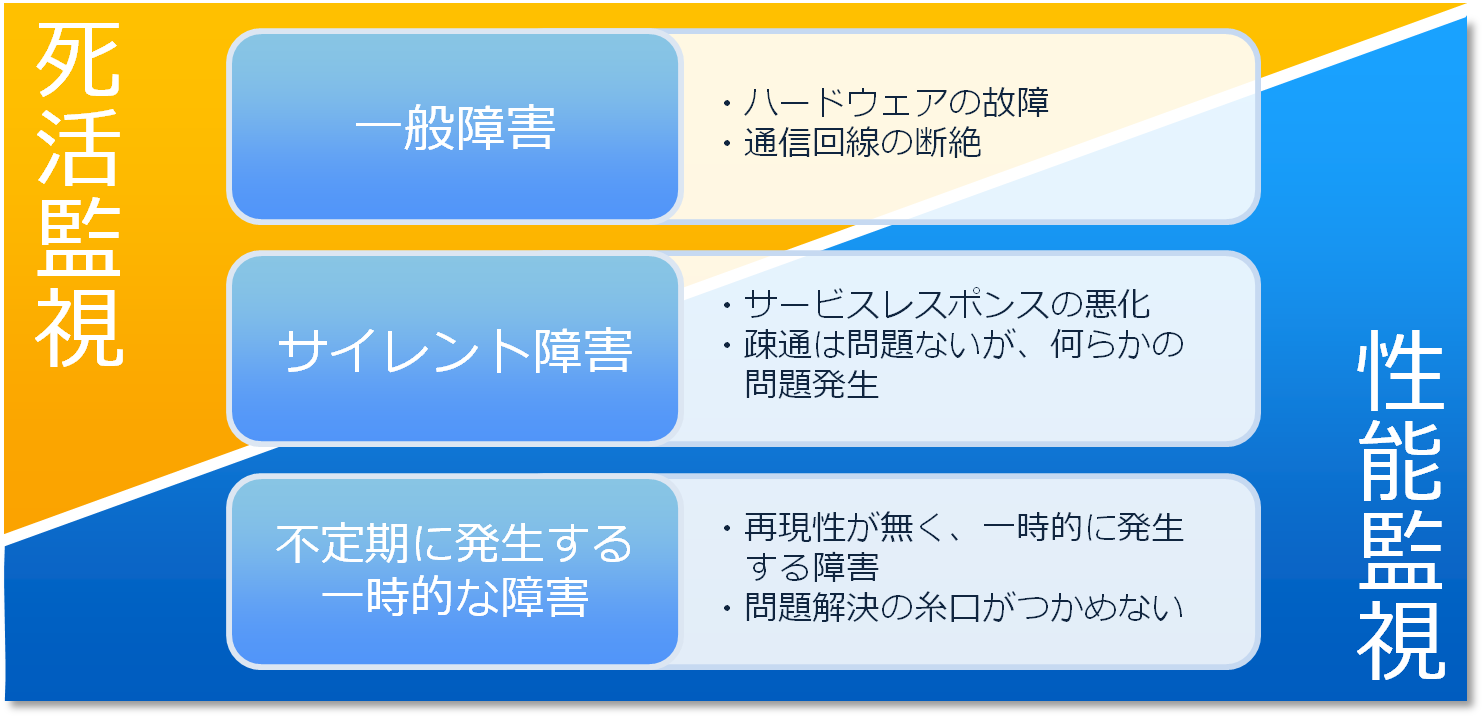
図1:トラブル分類での死活・性能監視の対応領域(クリックで拡大)
前述の通り、一般的な運用監視サービスでは、主に一般障害の発見を目標としており、サイレント障害や不定期に発生する一時的な障害に対しては対応が後手に回ってしまうことが珍しくなかった。しかし、これらの障害もシステムのサービス品質の低下を引き起こし、ユーザーに悪影響を及ぼすことに変わりはないため、迅速な解決が求められる。死活監視では「完全にサービスが停止しないと検知できない」のだが、性能監視では実は「常時正常な状況を見続ける」ことになる点に価値がある。この“正常な状況”に関するデータを踏まえ、そこからの変化として「障害」「性能劣化」「サービス品質の悪化」の兆候を捉えることができるのである。
ここからは、具体的な障害発見の手順に沿って、具体的にどのようなアプローチによって問題の根本原因に迫ることができるのかを見ていこう。実際の作業手順は使用するツールがどのような機能を実装しているのかによって変わってくるのだが、ここでは当社の「System Answer G2」の使用例に基づいて紹介していく。



連載バックナンバー



Think ITメルマガ会員登録受付中
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。





