GPUを活用してデータベースを爆速化する「PG-Strom」の仕組み

- 1 はじめに
- 2 従来のデータベース性能向上方法の限界
- 2.1 スケールアップ型アプローチの限界
- 2.2 インメモリデータベースの限界
- 2.3 スケールアウト型アプローチの限界
- 2.4 インデックスの限界
- 2.5 パーティショニングの限界
- 3 PG-Stromの概要
- 4 PG-Stromの高速化手法
- 4.1 GPUの大量のコアを活用した超並列処理
- 4.2 GPUDirect Storageによるデータ読み込みの高速化
- 4.3 Apache Arrow形式の列指向データの利用
- 5 PG-Stromが得意な検索・集計処理
- 5.1 インデックスが効かないフルスキャン検索
- 5.2 ビッグデータの集計処理の超並列化
- 6 地理空間情報処理への応用
- 6.1 PG-StromのPostGIS対応
- 6.2 高速化されるPostGIS関数の例
- 7 PG-StromのOSS版と商用版の違い
- 7.1 GPUの制限
- 7.2 NVMe SSDの制限
- 7.3 その他の違い
- 8 おわりに
はじめに
前回は、データベースの性能を向上させる方法について解説しました。今回は、GPUを活用してデータベースの性能を爆速化する「PG-Strom」の仕組みについて解説します。
従来のデータベース性能向上方法の限界
前回で様々なデータベースの性能を向上させる方法を解説しましたが、それらは万能というわけではなく、それぞれに限界があります。まず、どのような限界があるのかを見て行きましょう。
スケールアップ型アプローチの限界
スケールアップは、CPUの高速化やコア数の増加、あるいはメモリの大容量化やディスクの高性能化などの手法です。手っ取り早い手法ですが、CPUのコア数上限やメモリ容量の上限、ディスクの性能上限といった物理的な限界があります(図1)。
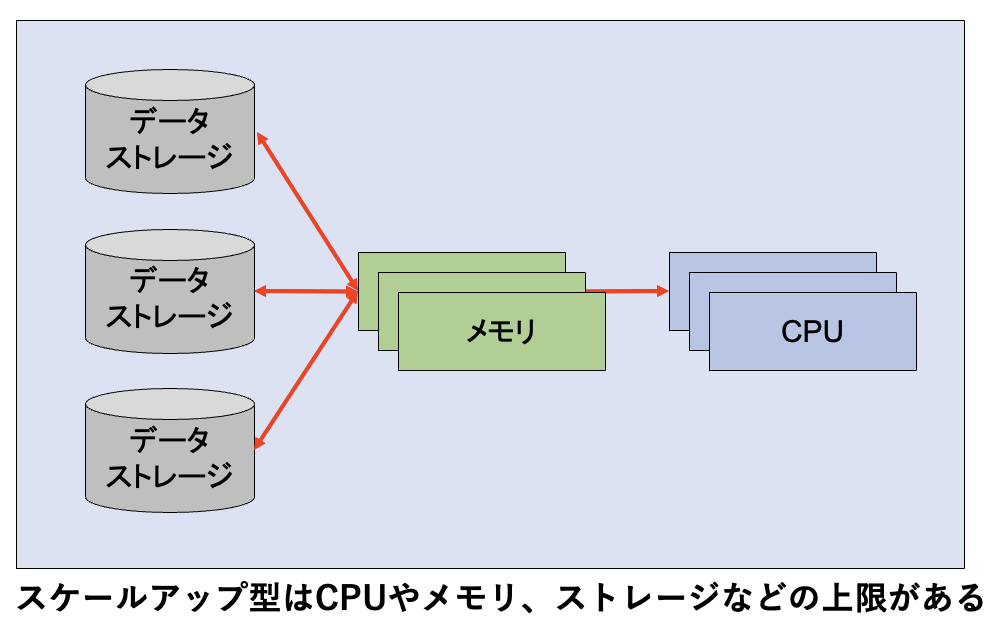
図1:スケールアップ型の限界
インメモリデータベースの限界
スケールアップの1つとして大容量のメモリを搭載し、あらかじめデータをすべてメモリに読み込んでおく「インメモリデータベース」という手法があります。商用製品ではSAP HANAなどがあります。
1台のマシンに搭載できるメモリには上限があり、かつ大容量メモリが搭載可能なマシンは大変高価です。また大容量にするには容量が大きいメモリモジュールを選ぶ必要があるため、メモリ容量単価も非常に高くなります。全体的に高コストなソリューションになってしまうのが大きな難点です。
スケールアウト型アプローチの限界
スケールアウトは、スケールアップの限界を解消するため、マシンを複数台並べて並列化を行います。この手法は台数が増えると管理が複雑になり、コストもアップするなどの限界があります(図2)。
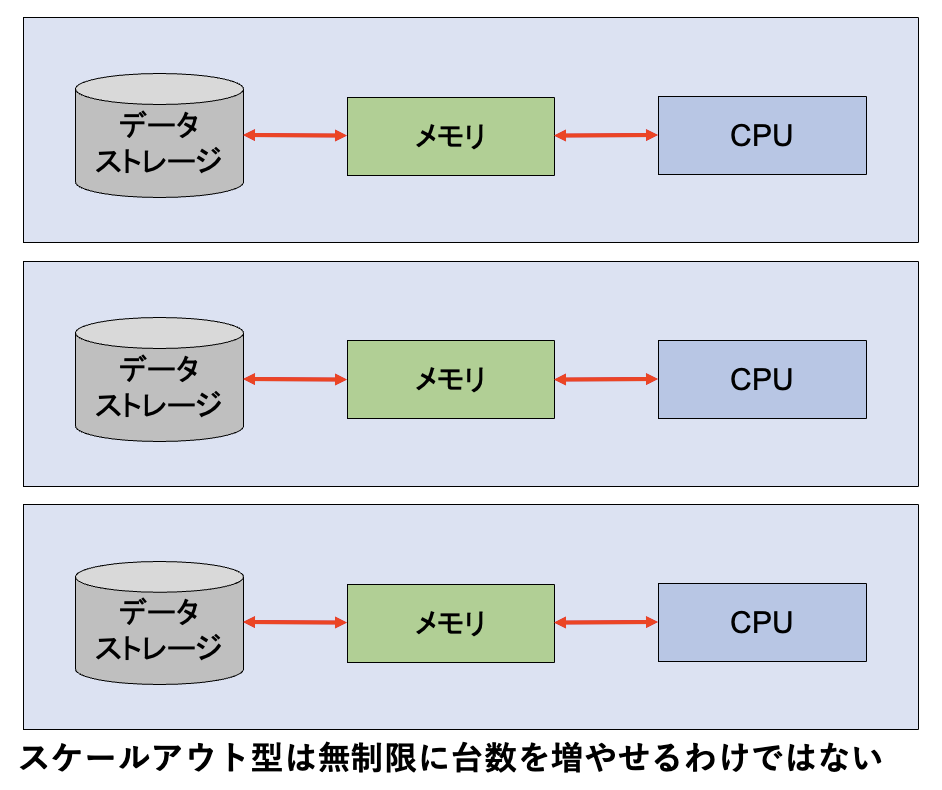
図2:スケールアウト型の限界
インデックスの限界
インデックスは特定のデータを見つけ出すのには向いていますが、大量のデータを集計する処理ではインデックスは使われず、すべてのデータを読み込む処理が必要になります。
パーティショニングの限界
パーティショニングは集計対象のデータを絞り込む効果はありますが、そこから先の処理はその他の高速化手法と同様の限界があります。
PG-Stromの概要
このような様々な性能の限界を解決するには、新しいアプローチが必要になります。その1つの解が、GPUを活用してデータベースの検索・集計処理を爆速化する「PG-Strom」です。
PG-Stromはオープンソースのデータベースとして人気のあるPostgreSQLを拡張し、ビッグデータの高速検索・集計処理を可能にしたソフトウェアです。ヘテロDB株式会社の海外 浩平氏が開発を行っている国産の技術です。様々な手法を組み合わせて高速化を行っているので、まずはそれらについて解説します。
PG-Stromの高速化手法
PG-Stromは、以下のようなアプローチを組み合わせることで検索・集計処理を爆速化しています。
- GPUの大量のコアを活用した超並列処理
- GPUDirect Storageによるデータ読み込みの高速化
- Apache Arrow形式の列指向データの利用
それぞれ、詳しく解説していきます。
GPUの大量のコアを活用した超並列処理
スケールアップする方法の限界の1つは、CPUが搭載できるコア数に限度があることに起因しています。それに対してGPUは大量のコアを搭載しています。CPUとGPUのコア数を比較してみましょう。
本稿を執筆した2024年3月現在、CPUコア数が一番多いプロセッサはAMD EPYC 9754の128コアです。一方、NVIDIAのデータセンター用GPUのA100は6912コア(INT32)、H100は7296コア(INT32)と50倍以上のコアを搭載しています。GPUにはこれらの大量のコアを使って超並列に処理が行えるという優位性があります(図3)。

図3:コア数の違いによるデータ処理の違い
GPUDirect Storageによるデータ読み込みの高速化
GPUに搭載されているメモリはHBM(High Bandwidth Memory)と呼ばれる仕様でプロセッサと接続されており、通常のコンピューターでメインメモリに使用されているDDR4接続よりも5倍から10倍の性能でデータを転送できます。このメモリ性能の優位性を活かすには、データをストレージからGPU上のメモリに高速に読み込む必要があります。
GPUDirect Storageは、NVMe(Non-Volatile Memory Express)で接続されたストレージから直接GPU上のメモリにデータを読み込む技術です(図4)。NVMeのストレージはPCI Expressを経由してGPUに接続されています。低速なメインメモリを介する必要がないので、高速に大容量のデータを読み込んで処理が行えます。インメモリのように高コストな大容量メモリを用意する必要もないので、大容量のデータを読み込む必要があるビッグデータの処理において非常に有効な手段と言えます。
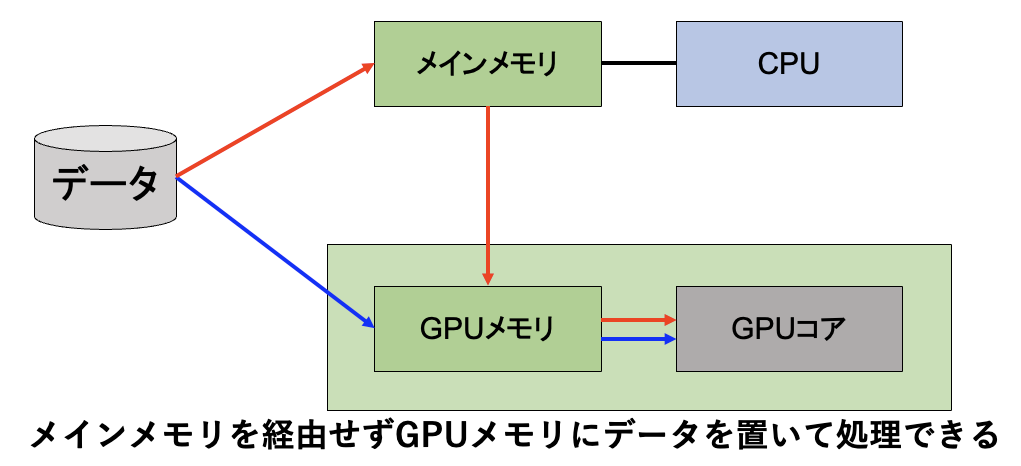
図4:GPUDirect Storageを使った場合のデータ経路
Apache Arrow形式の列指向データの利用
PG-StromはPostgreSQLの拡張機能なので、データは通常のPostgreSQLのデータベースとして格納しておき、検索・集計処理の対象にできます。ただし、この場合は通常の行指向データベースなのでデータの読み込みは行単位となり、検索・集計処理に必要ない列のデータも読み込む必要があるため非効率です(図5)。
例えば、行データが1行あたり1024バイトあるとして、集計処理に必要なデータは128バイトだとすると、残りの896バイトは読み込む必要の無かったデータということになります。1行だけ読むならば大したことはありませんが、何千万行も読み込む場合には大きな無駄となります。
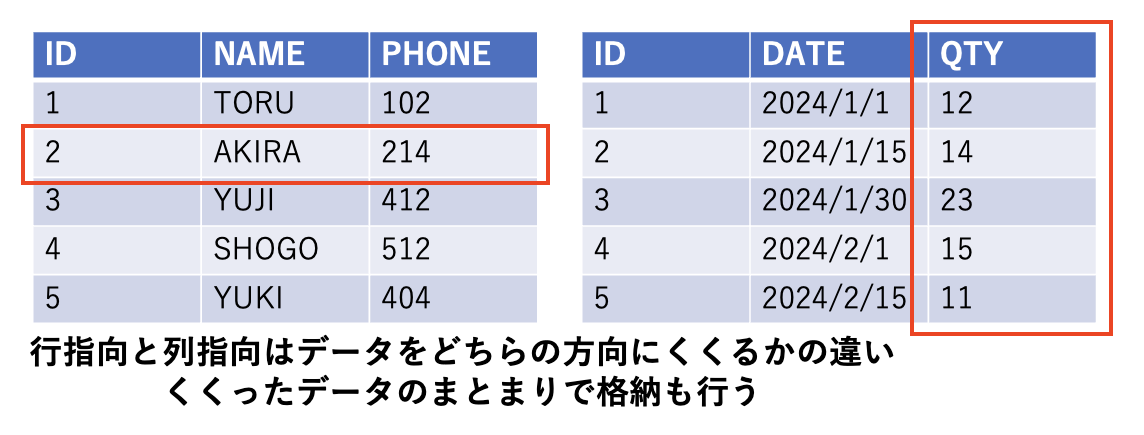
図5:行指向と列指向の違い
検索・集計処理に必要な列があらかじめ決まっている場合には、その列のデータだけを列指向型のデータ形式で格納することで効率良くデータを読み込むことができます。列指向型データ形式では列データ単位でまとめてデータを格納するため、保管されていても不要な列データは読み込まれません。
列指向データ形式には様々なものがありますが、汎用的に使えるものとしてApache Arrow形式がよく使われています。PostgreSQLには外部データにアクセスできるFDW(Foreign Data Wrapper)という拡張機能があります。PG-Stromでは、Apache Arrow形式のファイルにアクセスできるarrow_fdwモジュールを提供しています。
PG-Stromでは、PostgreSQLのデータベースをApache Arrow形式に変換するツールや、ログデータなどの収集によく使われているFluentdのデータをApache Arrow形式で保存するプラグインなどを提供しています。
PG-Stromが得意な検索・集計処理
それでは、PG-Stromのこれらの技術は、どのような検索・集計処理を爆速化してくれるのでしょうか。
インデックスが効かないフルスキャン検索
前述の通り、検索・集計処理にはインデックスが効きにくく、原則すべてのデータを読み込むフルスキャン処理になる場合が多くなります。パーティショニングが有効に働けば、ある程度スキャンするデータを減らすことができますが、そこから先はCPUやメモリ、ストレージの性能に左右されます。
PG-StromではGPUDirect Storageによる高速なデータ読み込みと、Apache Arrow形式のデータによる効率化の組み合わせでボトルネックを解消してフルスキャン処理を高速化しています。
ビッグデータの集計処理の超並列化
ビッグデータの集計処理は読み込んだデータに対して様々な計算を行う必要がありますが、GPUの持つ大量のコアを使って超並列処理を行えば、1回の単位計算時間で処理できるデータ量がCPUよりも多くなり、高速に集計処理を行えます。
地理空間情報処理への応用
ここまでの解説では、主にログデータなどの検索・集計処理を想定していましたが、今後需要が高まると予想されるのが地理空間情報の高速な処理です。いわゆるGIS(Geographic Information System:地理情報システム)と呼ばれるシステムへの応用です。今後、GPSを搭載した様々なデバイスが生成する位置データなどを大量に処理するシステムでの利用が可能です。
PG-Stromは、PostGISというPostgreSQLのGIS処理拡張に対応しています。
PG-StromのPostGIS対応
PG-StromのPostGIS対応は、よく使用されるPostGIS関数をPG-Stromの高速化手法を使って処理するように実装されています。PostGISでは地理空間情報をジオメトリ型として扱います。ジオメトリ型は、ある位置を示す点や線分、区画(ポリゴン)となります。このジオメトリ型を扱う関数をPostGISが提供しています。
高速化されるPostGIS関数の例
PG-Stromが高速化しているPostGIS関数として、例えばst_contains()関数があります。これは、ある点が区画の中に含まれるとTRUEを返す関数です。ある地域の中にある点のデータを抽出する、という処理に利用できます。
なお、区画が単純な四角であれば簡単に判定できますが、複雑な線分で囲われた区画の場合は判定のための計算量は非常に多くなるため、CPUよりもGPUの方が高速に処理が行えます。
PG-StromのOSS版と商用版の違い
PG-Stromは基本機能をオープンソースソフトウェアとして開発されており、誰でも試すことができます。ただし、いくつかの点で商用版と違いがあります。
GPUの制限
OSS版では、使用できるGPUは1基のみとなります。商用版では複数のGPUを同時並列に使うことができます。
NVMe SSDの制限
GPUDirect Storageを使って高速にデータを読み込むには、PCI Expressでローカル接続されたNVMe SSDや高速なネットワークで接続された外部ストレージを用意する必要があります。ローカル接続の場合、より高速にデータを読み込むためには複数台のNVMe SSDを並列で接続しますが、OSS版ではNVMe SSDは1台のみに制限されています。なお、GPUDirect Storageを使うにはデータセンター用途のGPUであるH100やA100などが必要です。ゲーム用途のGeForceでは使えません。
商用版では、PCI Expressのレーン数がx16レーンに対して、1台のNVMe SSDがx4レーン使用するため、4台のNVMe SSDを接続するのが最も高速な構成になります。
その他の違い
PostGISでの検索処理に効果を発揮するGiST(Generalized Search Tree)インデックスをGPUで利用する機能が有償版でのみのサポートになります。また、メールによる技術サポート等も提供されます。
おわりに
今回は、GPUを活用したビッグデータ処理の高速化手法であるPG-Stromについて解説しました。従来のデータベース基盤や高速化の手法はデータを確実に保管するOLTP(Online Transaction Processing)には強いですが、ビッグデータに対するOLAP(Online Analytical Processing)という大容量データ検索・集計には向いていませんでした。
データを大量に処理するという意味では、AIや機械学習を行うにはGPUが強いということと共通点を見出すことができます。これからの新しいビッグデータ基盤はGPUの活用が必須となるでしょう。ぜひ、この新しい技術に注目してみてください。
次回は、PG-Stromがどれぐらい高速なデータ検索・集計処理を行えるのか、ベンチマーク結果を示しながら解説します。


連載バックナンバー



Think ITメルマガ会員登録受付中
他にもこの記事が読まれています





全文検索エンジンによるおすすめ記事
- データベース性能の基本的な考え方
- データベースの性能を向上させるには
- 開発者必見! Windows Server&SQL Server 2016テクニカルガイド―IT提案セミナーレポート
- とんがったデータベースエンジニアになれ! db tech showcase 東京 2013レポート
- Oracle ExadataによるDWH高速化
- PostgreSQLの進化に迫る
- VMwareのSDSであるVMware vSANの概要
- Rubyでデータサイエンスするための3つのアプローチ、DataScience.rbで考察
- NVIDIA、大規模データ分析およびマシンラーニング向けGPUアクセラレーションプラットフォーム「RAPIDS」リリース
- NVIDIA、大規模データ分析およびマシンラーニング向けGPUアクセラレーションプラットフォーム「RAPIDS」リリース