プログラミング言語や標準APIへの対応
プログラミング言語や標準APIへの対応
"CUDA C"のプログラミング手法については、第1回で多少ふれましたが、ほかにもFortranやJavaといった言語についても同様にサポートしています。
また、CUDA Toolkitに含まれている、高速フーリエ変換(FFT)や倍精度汎用行列乗算(DGEMM)を含む基本線形代数サブプログラム(BLAS)をはじめ、それ以外の各種ライブラリやミドルウエアについてもCUDAへの対応が着実に進んでいます。
|
| 図3: CUDAの並列処理アーキテクチャ(クリックで拡大) |

OpenCLの推進
CUDA CがNVIDIAのGPU専用のプログラミング言語であるのに対し、同じくC言語をベースにしながら特定のアーキテクチャに依存せず、マルチコアCPUも含めた異種混合の並列コンピューティングのためのフレームワークとして、OpenCL 1.0の仕様が2008年12月にKhronos Groupから正式に発表されました。
NVIDIAは、CUDA環境の上でのOpenCL 1.0のサポートをいち早く発表し、2009年4月に業界初となるOpenCLドライバとSDKの提供を開始しました。
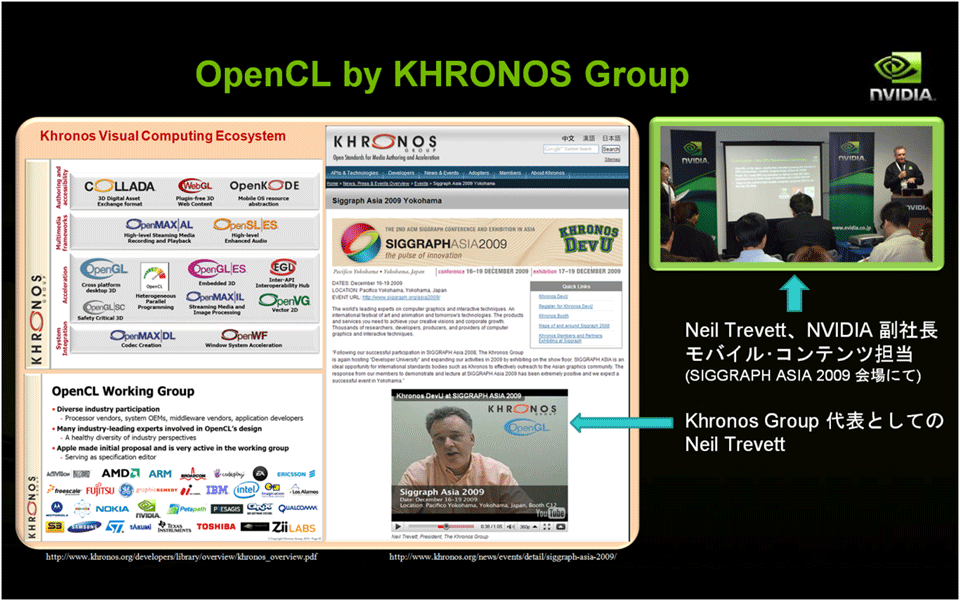
OpenCLの標準化は、OpenGLやその他のビジュアル・コンピューティングのプラットフォームとともに、Khronos Groupが業界を取りまとめていますが、その代表者であるNeil TrevettはNVIDIAのモバイル・コンテンツ担当の副社長であり、NVIDIAもグループのメンバーとして、業界の標準化に貢献しています。
2009年の12月に横浜で開催されたSIGGRAPH ASIA 2009に参加したNeil Trevettは、Khronos Groupの代表者として、またNVIDIAの副社長として、それぞれの立場で最新の技術に関するスピーチを行いました。
|
| 図4: OpenCL規格を定めているKhronos Group(クリックで拡大) |
OpenCLの登場によりCUDA Cの存在意義が無くなるのではないか、という質問をしばしば受けることがありますが、この2つの開発プラットフォームは使用者や使用目的が異なるため、NVIDIAとして、双方ともにCUDA開発環境への重要なエントリー・ポイントとしてサポートをしています。
CUDA Cは、最新のGPUの機能やアルゴリズムをいち早く取り入れ、パフォーマンスや使いやすさをタイムリに向上させるためのプラットフォームであるのに対し、OpenCLはプログラミングの標準化が主目的であり常に最新の機能がサポートされているというわけではありません。
CUDA CとOpenCLには、別々の前工程コンパイラがありますが、それぞれのコンパイラが目指しているのは、中間生成言語であるPTX(Parallel Thread eXecution)レベルでの最適化です。
特にOpenCLの場合は同じソースコードで他社GPUやマルチコアCPUとの競合がありますので、NVIDIAとしても当然パフォーマンスの最適化を目指しています。
いったんPTXまで落ちてしまえば、共通の後工程のコンパイラがすべてのPTXコードを処理しますのでソース言語の違いによる影響はありません。
ただし、一般的にOpenCLのコードがCUDA Cのコードよりも得られるパフォーマンスが低い場合があります。その理由を一言でいえば、標準化の足かせが原因ということになります。
新しく追加されたGPUの機能がOpenCL言語の標準化を待つために使えなかったり、あるいは特定のアーキテクチャ固有の機能であるためにOpenCLではサポートされないことがあるため、ある時点でCUDA Cでは可能なことがOpenCLではできず、別の手法をとらざるを得ないため、結果的にパフォーマンスの差ができてしまうということがあります。
|
| 図5: OpenCL(低レベルAPI)とCUDA C(高級言語)の関係(クリックで拡大) |

デバッグ環境の充実
Microsoft Visual Studio に並列コンピューティングを組み込んだ業界初の開発環境として、NVIDIA Parallel Nsightが2010年7月に正式にリリースされました。これにより、CPUとGPUのコードを同一のプラットフォームで同時に開発できる環境が整いました。
GPUのコードとしては、GPUコンピューティングだけではなく、DirectX 10やDirectX 11を使用したグラフィックス・プログラムの開発やデバッグ、最適化が可能になり、統合的な開発環境が整ったといえます。
また、Visual Profilerは、GPUのカーネルやメモリ・データ転送の監視、GPUごとの複数コンテキストのプロファイリング機能等を備え、従来からLinuxをはじめWindows やMacOSなど各種OSに対応しています。
cuda-gdb は、標準のGNUプロジェクト・デバッガーへの追加機能として、Linux環境でCPUとGPUの同時デバッグを可能にします。
|
| 図6: CUDA環境向けのデバッグ・ツール(クリックで拡大) |

ISVアプリケーションのCUDA化
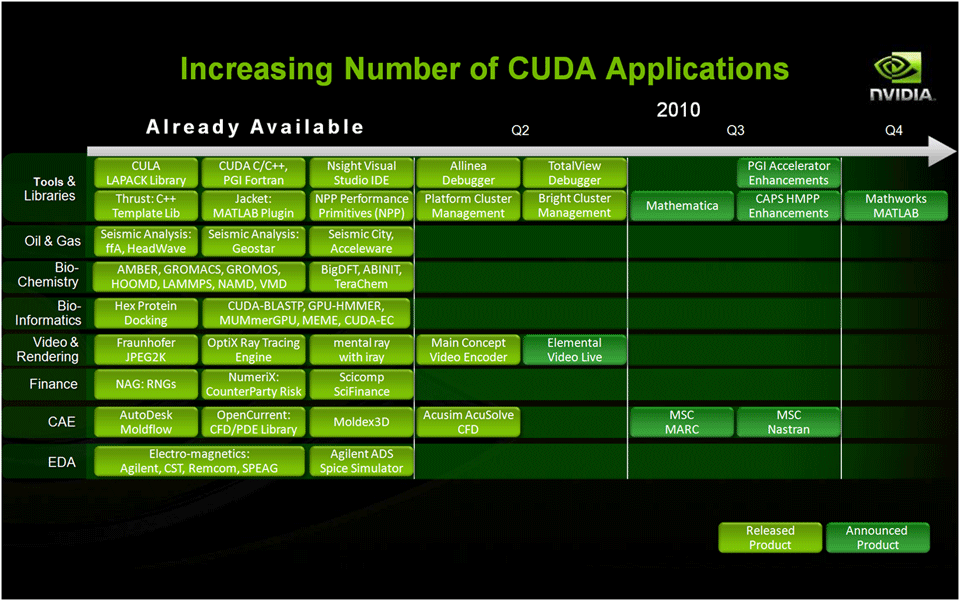
GPUコンピューティングの広がりを支えるもう1つの重要な側面は、さまざまな業界で利用されている主要ISVアプリケーションのCUDA対応です。
特に、生物化学系、生物情報科学系、映像・画像処理系、金融系、エンジニアリング系などの分野では、いくつかの主要アプリケーションについて、既にCUDA対応が発表されています。
まだ発表されていないCUDA化進行中のアプリケーションも数多くあり、今後の展開に期待が寄せられています。
|
| 図7: 増え続けるCUDA対応アプリケーション(クリックで拡大) |
- この記事のキーワード
この記事をシェアしてください
関連記事
バックナンバー
この記事の筆者

筆者の人気記事
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
