レスポンスタイムのモニタ ITサービスのパフォーマンス管理の第一歩は、レスポンスタイムをモニタすることである。レスポンスタイムは、前回説明したpingとポート監視で測定できる。pingは、ICMPのエコーによる応答確認でTCP/IPレベル接続確認を行う。 この時に、リクエスト送信から応答受信までの時間を測定することで、TCP/IPレベルのレスポンスタイムを測定できる。これはpingコマンドで表示される応答時間である。ICMPの通信はOSに近いレベルで処理されるため、サーバの負荷やアプリケーションの性能の影響をあまり受けない。したがって、pingによるレスポンスタイムの測定値は、ネットワークレベルのパフォーマンスを表していると言える。 よって、経路上のネットワーク機器に対して順番にpingによるレスポンスタイムの測定を行うことで、ネットワークレベルでのボトルネックを検出することができる。 pingで送信するICMPパケットのサイズを変えることにより、経路上の最低速度の回線を予測することができる。これは、パケットサイズにより回線の転送時間が変化するという原理を利用して測定する。ただし、最近はほとんどの回線が高速になってきており、pingで送信できるパケットのサイズでは測定が難しくなっている。 さらに、ポート監視で説明したアプリケーションプロトコルレベルでの応答確認でレスポンスタイムを測定することで、ITサービス自体のパフォーマンスを調べることができる。このレスポンスタイムには、ITサービスを提供するすべての要素の処理時間が含まれる。 例えば、Webサービスの場合、あるページのリクエストを送信して、そのページのデータが返されるまでの時間を測定する時、Webサーバまでのネットワークの通信時間、Webサーバ自体のリクエストの処理時間、さらに、Webサーバがデータベースサーバと連携して応答を返す場合には、その処理時間まで含まれている。この時間がITサービスの利用者が体感するサービスのパフォーマンスを最も表した値だ。 このようなレスポンスタイムの測定は「第2回:構成を把握し、障害に対応する!」の障害管理で紹介したネットワーク監視ツールを定期的に利用することで、平常時とパフォーマンス低下時の状態を検知できる。 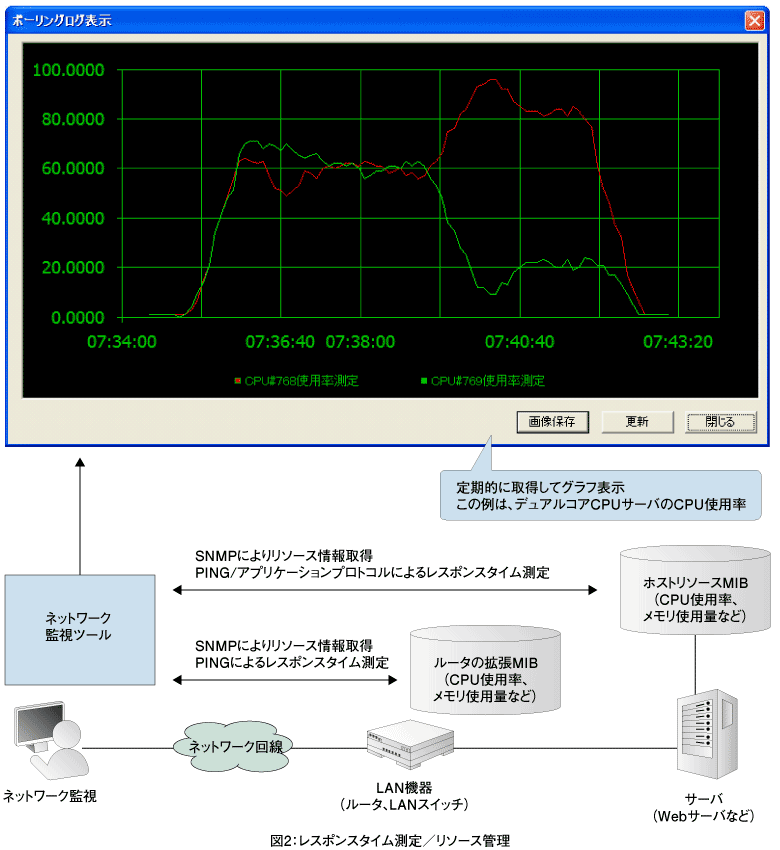 (画像をクリックすると別ウィンドウに拡大図を表示します) リソース管理 ITシステムのパフォーマンス低下の原因が、サーバや経路上のルータの性能に起因するものか判断するためには、これらのリソースをモニタする必要がある。この方法にはいくつかの技術があるが、OSや機器の種類に依存しないSNMP(Simple Network Management Protocol)の利用が有効である。 SNMPの標準MIB(Management Information Base)には、サーバなどのCPU使用率、メモリの搭載量、使用量、プロセスごとのCPU使用率などをモニタするための、ホストリソースMIBが定義(RFC1514)されている。ルータに関しても、シスコなどはベンダー拡張MIBによってCPU使用率などのリソース情報をSNMPでモニタできる。 これらのリソース情報と先に説明したレスポンスタイムを同時にモニタリングし、その因果関係を解析することで、サービスのパフォーマンス低下の原因究明を行う。例えば、WebサーバのCPU使用率が高い状態で動作している時に、Webサーバからのレスポンスタイムが長くなるという関係が分かれば、サーバの性能アップにより改善できる可能性があるということだ。 | ||||||||||
| ||||||||||
| ||||||||||
| ||||||||||
| ||||||||||
-
-
連載


新着記事
焦りは禁物?「特化」の前に「汎用」を。エクサウィザーズが語る東海製造業における生成AI成功の秘訣 6:30 SUSE、インフラのレジリエンスとオープンソースAIで日本のDXを加速——ベンダーロックインからの脱却を支援 6:20 「HAMi」でKubernetes上のGPUメモリ分離の仕組みを理解し、共有を試してみよう 7月15日 6:30 「C/C++」の「RayLib」でコンソールゲーム「Color」を開発してみよう 7月15日 6:30 Gartner、エージェント型AIによってエンタープライズ・アプリケーション向け支出の2,340億ドルがリスクにさらされるとの見解を発表 7月14日 6:30