| ||||||||||||||
| 前のページ 1 2 3 4 | ||||||||||||||
| MySQL+MyISAMエンジンのテーブルの特徴 | ||||||||||||||
MySQL+MyISAMエンジンのテーブルには、3種類のデータ構造があります。その中には、レコードデータのサイズが固定長のものと可変長のものがあり、MySQLが自動で選択します。固定長構造は、テーブルを構成するカラムのデータ型にVARCHAR、TEXT、BLOBを含んでいない場合に選択されます。 固定長構造の最大の利点は、レコードの削除が行われた場合でも削除されたデータ領域を再利用することが容易なことです。よって固定長構造のテーブルファイルは、再利用できないデータ領域が残ってしまう「データのフラグメンテーション」が発生しない特徴を持っています。 データのフラグメンテーションとは、利用できない無駄なデータ領域が虫食いのように残ってしまうことをいいます。また固定長構造のテーブルには、レコードデータに「row number」と呼ぶレコードを一意に識別する値が付けられ、MySQLはこの値を利用して高速に該当レコードを探し当てる仕組みを持っています。 可変長構造は、テーブルを構成するカラムのデータ型にVARCHAR、TEXT、BLOBを含んでいる場合に選択されます。可変長構造のテーブルファイルは固定長構造と異なり、レコードを削除した場合のデータ領域の再利用が難しいため、データのフラグメンテーションが発生する可能性を持っています。 データのフラグメンテーションが発生すると、ディスクの利用効率が低下するため、検索性能が劣化してしまいます。そのため、可変長構造のテーブルの場合は、一定周期にて、このデータのフラグメンテーションを取り除く処理を実施する必要があります。 またもう1つの構造は、圧縮テーブルと呼ぶ読み取り専用のものです。この構造は自動で選択されるものではなく、オプションツール(myisampack)を用いてユーザが作成するものです。固定長構造、可変長構造ともに、圧縮テーブル構造に変更することが可能です。 | ||||||||||||||
| MySQL+InnoDBエンジンのテーブルの特徴 | ||||||||||||||
MySQL+InnoDBエンジンのテーブルはクラスタードインデックスと呼ばれる、特別なインデックスを備えた構造にてテーブルスペースの中に格納されます。クラスタードインデックスとは次に示すように、リーフと呼ぶインデックスの最下位レベルの部分がテーブルのレコードそのものになっている構成のインデックスです。 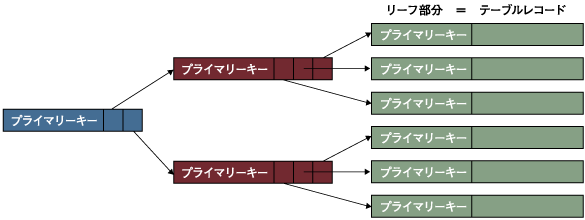 図3:MySQL+InnoDBのクラスタードインデックス (画像をクリックすると別ウィンドウに拡大図を表示します) よって、テーブル内のレコードはインデックス値の順に並んでいるといった特徴を持ちます。Oracleでは、この構成を索引構成表と呼び、通常のテーブルと区別して提供しています。 InnoDBエンジンのクラスタードインデックスの値は、プライマリーキーが使用されるため、プライマリーキーの値順にレコードが並んだ構成のテーブルとなります。プライマリーキーが定義されていないテーブルの場合は、InnoDBが自動的に6ByteのローIDと呼ぶフィールドをレコードに追加し、このローIDを用いてクラスタードインデックスを構成します。 クラスタードインデックスは、構造上1テーブルに1つしか作成できません。そこで、セカンダリーインデックスとして、非クラスタードインデックスが作成できます。非クラスタードインデックスのリーフ部分には、プライマリーキー値もしくは、ローIDが使用され、最終的にはクラスタードインデックスを通して、対象のレコードが選択されます。 | ||||||||||||||
| 前のページ 1 2 3 4 | ||||||||||||||
| ||||||||||||||
| ||||||||||||||
| ||||||||||||||
-
人気記事ランキング
-
-
連載


新着記事
NVIDIAら37社が「Open Secure AI Alliance」設立――AIエージェントのセキュリティは重みの非公開では守れない 6:20 【クラウドネイティブ会議】厳格な統制と開発者体験を両立する、Wiz Baseにおけるゴールデンパスの実践 6:00 その「ソーシャルログイン」は大丈夫? OAuth/OIDC実装の3つの落とし穴 7月29日 6:30 KubeCon Europe 2026、新興のオブザーバビリティ企業Hygroundの製品責任者にインタビュー。生成AIの使用を前提にした新世代オブザーバビリティとは 7月29日 6:00 障害発生時でも継続運用を実現する「MySQL」と「PostgreSQL」の「高可用性構成」を理解する 7月28日 6:30