| ||||||||||||||
| 前のページ 1 2 3 4 次のページ | ||||||||||||||
| 中間一致用索引の生成 | ||||||||||||||
検索対象が6万4千件まではExcelでも検索ができます。しかし対象が30万件、50万件と大きくなると書名などの長い文字列から一部の文字を持っているものを検索するのは大変な作業になります。 一般にデータベースではフィールドに索引を作ります。索引では入力されている文字列を先頭文字から順に判断してアルファベット順や漢字コード順に並べておきます。実際に検索するときは元のデータを見るのではなく、あらかじめ作っておいた漢字コード順の書名索引を見に行けば書名順に並んだところから検索できるのとてもはやく見つけることができます。 ところが書名の途中の文字を探すときはこうした索引では見つけることができません。結局すべての書名を見て、それぞれの書名に検索する文字列が含まれているかを見ていかなければいけません。実際の図書館で使われるコンピュータシステムではこうしたデータベースの機能だけに頼らず、様々な工夫を凝らして、書名の一部からでも素早い検索ができるようにしています。 ところがFileMaker Proでは何も工夫しなくても入力された文字列から検索用に単語単位で索引を作ってくれます。英文だけでなく、日本語の文字列に対しても熟語単位で索引を作ってくれます(図6)。 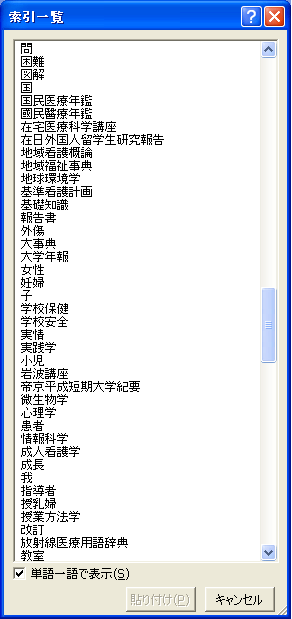 図6:自動作成される索引の確認表示画面 このような中間一致検索用の索引を自動生成してくれるデータベースは私が知る限り世界中にFileMaker Proしかありません。 検索するときは1つのフィールドに複数の検索語を入力できます。例えば書名フィールドに「医学 外国人 留学生」のようにスペース(半角でも全角でも可)で分けて入力します。そのまま「検索」ボタンを押せば一瞬でこの3つの文字列が使われている書名を持った資料が検索できるのです(図7)。  図7:検索語をスペース区切りで複数設定し、AND検索ができます (画像をクリックすると別ウィンドウに拡大図を表示します) | ||||||||||||||
| 前のページ 1 2 3 4 次のページ | ||||||||||||||
| ||||||||||||||
| ||||||||||||||
| ||||||||||||||
-
人気記事ランキング
-
-
連載


新着記事
焦りは禁物?「特化」の前に「汎用」を。エクサウィザーズが語る東海製造業における生成AI成功の秘訣 7月16日 6:30 SUSE、インフラのレジリエンスとオープンソースAIで日本のDXを加速——ベンダーロックインからの脱却を支援 7月16日 6:20 「HAMi」でKubernetes上のGPUメモリ分離の仕組みを理解し、共有を試してみよう 7月15日 6:30 「C/C++」の「RayLib」でコンソールゲーム「Color」を開発してみよう 7月15日 6:30 Gartner、エージェント型AIによってエンタープライズ・アプリケーション向け支出の2,340億ドルがリスクにさらされるとの見解を発表 7月14日 6:30