| ||||||||||||||||
| 前のページ 1 2 3 次のページ | ||||||||||||||||
| 普通の検索、全文検索 | ||||||||||||||||
企業内で管理されている膨大なテキストデータを活用するため検索しようとした場合、データベースはどういう検索が得意か理解しておくことが必要です。ここでは辞書を例に説明してみましょう。 辞書をデータベースと想定すると、辞書テーブルを構成する列は「単語」「よみ」「意味」「ページ」です。このデータベースを用いて、ある単語の意味を調べましょう。
表1:辞書テーブル この場合、意味を調べたい単語のよみから、五十音順に並べられた決まりに従い、意味を探すことになります。例えば、「筆勢」の意味を実際に辞書で引くときは、小口(背表紙の反対側)に記されたハ行の場所から、最初に開いたページに「振り子」が載っていれば少し前のページを、「左」が載っていれば後ろのページを探しながら「筆勢」のページにたどり着きます。このような仕組みとルールを知っていることで辞書はそれほど時間を要さずに意味を調べることができます。 データベースも同様の仕組みを有しています。これをインデックスといいます。インデックスの存在により、データベースは高速に記録を抽出することができるのです。 しかし、似たような意味の単語を調べようとして、意味欄に「筆」と「勢い」が含まれる単語を全部抽出し、その中から似たような意味の言葉を見つけ出そうとする場合、どうすればよいでしょうか。辞書には、そのような仕組みとルールが備わっていないので、すべての単語の意味欄をチェックすることとなり、膨大な時間を要してしまいます。 データベースでも同様です。全文検索の機能が備わっていないDBMS(注1)では、すべての記録をチェックして記録を抽出する必要があり、非常に時間がかかってしまいます。 ※注1:PostgreSQLやMySQLなど。ただし、欧米言語に対応した全文検索機能は有している。 | ||||||||||||||||
| 現状のDBMSの課題 | ||||||||||||||||
全文検索ニーズの高まりにつれ、DBMSにも全文検索機能が追加されはじめたのはここ5年ほどのことで、主要な商用のDBMSには高度な日本語全文検索機能がほぼ装備されました。しかしオープンソースのDBMSである、PostgreSQLおよびMySQLには日本語に対応した全文検索機能が装備されていません。 そのため、データベースに蓄積されたテキストデータを活用できないでいるか、データベースのテキスト情報をわざわざ取り出してテキストファイルにし、そこに既存の全文検索機能であるNamazuなどを用いて検索を行うという工夫をするかのどちらかでした。 しかしこのような工夫はシステムの複雑化を招きます。また、記録の不整合やセキュリティの問題など、様々な問題があることから望ましい実現方式であるとはいえません。 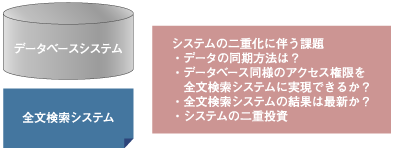 図1:既存のDBMSの課題 | ||||||||||||||||
| 前のページ 1 2 3 次のページ | ||||||||||||||||
| ||||||||||||||||
| ||||||||||||||||
| ||||||||||||||||
-
-
連載


新着記事
焦りは禁物?「特化」の前に「汎用」を。エクサウィザーズが語る東海製造業における生成AI成功の秘訣 6:30 SUSE、インフラのレジリエンスとオープンソースAIで日本のDXを加速——ベンダーロックインからの脱却を支援 6:20 「HAMi」でKubernetes上のGPUメモリ分離の仕組みを理解し、共有を試してみよう 7月15日 6:30 「C/C++」の「RayLib」でコンソールゲーム「Color」を開発してみよう 7月15日 6:30 Gartner、エージェント型AIによってエンタープライズ・アプリケーション向け支出の2,340億ドルがリスクにさらされるとの見解を発表 7月14日 6:30