| ||||||||||
| 前のページ 1 2 3 次のページ | ||||||||||
| 形態素解析とN-gram | ||||||||||
前述の通り、転置索引の表は単語で引けるようになっているため、転置索引の作成や検索のためには、検索対象の文書や検索文字列から「単語」を切り出さなければならない。しかしながら日本語の文章は英語などの文章と異なり、スペースで区切って書かれていないので、単語の区切りを明確に定めることが難しい。 現在、テキスト文字列から単語を抽出する方法としては「形態素解析」と「N-gram」の各方式が主流となっている(両方式を組み合わせる方式もあるがここでは省略する)。 「形態素解析」は辞書を用いてテキストから単語を抽出する方式で、フリーで利用可能なものとしては、「MeCab」などのOSSやYahoo!デベロッパーネットワーク提供のWebサービスである「日本語形態素解析Webサービス」などがある。 MeCab http://mecab.sourceforge.net/ Yahoo!デベロッパーネットワーク日本語形態素解析Webサービス http://developer.yahoo.co.jp/jlp/MAService/V1/parse.html 「N-gram方式」は抽出する単語の長さで1-gram、2-gram、3-gram、…などと具体的に呼ばれるものの総称である(Nが1〜3の場合はそれぞれuni-gram、bi-gram、tri-gramなどとも呼ばれる)。 「形態素解析方式」では辞書に載っていない単語をうまく抽出できないという欠点がある。このため、流行語や新語に対応するには、辞書のメンテナンスが欠かせない。 一方、「N-gram方式」では辞書を持たずに機械的にテキストから単語を区切るため、辞書のメンテナンスなどのわずらわしさがない。その反面、文書中の単語がたまたまN-gramで抽出された単語とヒットしてしまい、思わぬ文書が検索結果に含まれてしまうという「ノイズ」が増える欠点がある。 例えば、「東京都」というテキストを2-gramで分割すると「東京」と「京都」に分割されるため、「京都」という単語で「東京都」がヒットしてしまうのである。 このように「形態素解析」と「N-gram」は一長一短があるが、LuceneではAnalyzer抽象クラスを拡張した各種Analyzerが提供されており、フィールドごとに「形態素解析」と「N-gram」の各方式を使い分けることが可能となっている。 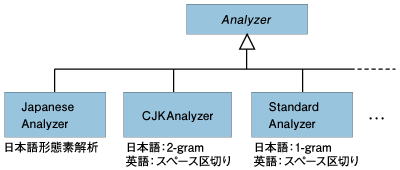 図2:各種Analyzer | ||||||||||
| Luceneの多彩な検索機能 | ||||||||||
Luceneは単語の検索はもちろん、成句(複数単語の連結。フレーズともいう)、ワイルドカード、正規表現、あいまい、範囲、フィルタリングなどの基本的な検索機能を提供している。さらに、これらを「AND/OR/NOTや()」の演算子を使って組み合わせた複雑な検索式を構成して高速に検索することができる。 次はLuceneの検索式の一例で、書籍を検索する条件を表現している。 PUB_DATE:[200701 TO 200706] AND CAT:コンピュータ|プログラミング|*Luceneの標準検索式の要素は「フィールド名:検索式」という書式になる。よってこの検索式は「出版日(PUB_DATE)が2007年1月から6月で『コンピュータ|プログラミング』のカテゴリ(CAT)に属する書籍」を検索する検索式である。 | ||||||||||
| Luceneの「ランキング」と「ソート」 | ||||||||||
「ランキング」と「ソート」は、どちらも検索結果表示ページにおける文書の表示順に関連する用語である。 「ランキング」は、検索にヒットした文書の表示順のことであり、検索式と文書の関連度合い(スコア)が高いものから並べられる。「ソート」はこのような関連度合いとは異なる文書の表示順を実現する機能を指す。 「ランキング」と「ソート」はユーザのカスタマイズ要求が最も集中する項目の1つだが、Luceneは「ランキング」と「ソート」へのカスタマイズの自由度が非常に高い検索エンジンである。以下は、Luceneで実現可能なカスタマイズ例である。
表1:Luceneで実現可能なカスタマイズ例 | ||||||||||
| 前のページ 1 2 3 次のページ | ||||||||||
| ||||||||||
| ||||||||||
| ||||||||||
| ||||||||||
-
-
連載


新着記事
焦りは禁物?「特化」の前に「汎用」を。エクサウィザーズが語る東海製造業における生成AI成功の秘訣 6:30 SUSE、インフラのレジリエンスとオープンソースAIで日本のDXを加速——ベンダーロックインからの脱却を支援 6:20 「HAMi」でKubernetes上のGPUメモリ分離の仕組みを理解し、共有を試してみよう 7月15日 6:30 「C/C++」の「RayLib」でコンソールゲーム「Color」を開発してみよう 7月15日 6:30 Gartner、エージェント型AIによってエンタープライズ・アプリケーション向け支出の2,340億ドルがリスクにさらされるとの見解を発表 7月14日 6:30