| ||||||||||||||||||||||||
| 前のページ 1 2 3 4 次のページ | ||||||||||||||||||||||||
| CPUビジー型の考察 | ||||||||||||||||||||||||
アドレス0xc0160de8の命令が最も頻度が高い結果となった。ソースコードとの突き合わせを行った結果、この処理はdo_generic_file_write()の中で呼ばれている__copy_from_user()であり、__copy_user_zeroing()にマクロ展開される。 | ||||||||||||||||||||||||
ssize_t | ||||||||||||||||||||||||
| ||||||||||||||||||||||||
__copy_from_user()は、ファイルに書き込もうとしているユーザ空間のデータをカーネル空間のページキャッシュに書き込む(コピーする)処理である。 このコピーはI/Oの書き込み処理の中でも最も中心といえる処理であり、これがプロファイリングのトップにあるということは書き込み処理に効率よくCPUが費やされていることを表している。厳密な意味では、この__copy_from_user()が呼ばれる回数自体に無駄がないかどうかなど、さらなる追及の余地があるが今回の評価ではそこまでは及ばなかった。 OProfileの実行結果より、CPUビジー型の場合は容易に実行ボトルネックを発見できることがわかる。 | ||||||||||||||||||||||||
| CPUアイドル型(I/Oビジー型) | ||||||||||||||||||||||||
CPUアイドル型については、パターンID 1を取り上げる。 プロファイリング結果より、CPUはhlt命令による休止状態にあることが多かった。これは、I/Oリクエストが処理されるスピードよりも、CPUを使ったデータコピー処理のスピードのほうが速かったため、I/Oリクエストが累積してCPU側が待たされていた状態にあったと考えられる(I/Oがビジーであると言える)。 そこで、実際にどれだけのI/Oリクエストの蓄積があったのかをLKSTによって調査した。マスクセットとしてbufferとblkqueueを使用して測定し、CPUアイドル型(I/Oビジー型)パターンとCPUビジー型パターンとの比較を行った。 頻度を回数から割合に変換してグラフ化すると図3のようになる。CPUアイドル(I/Oビジー)であるパターン1はCPUビジーであるパターン9に比べて所要時間のオーダが1近く長いことがわかる。それだけI/Oリクエストの処理が相対的に遅かったことが見てとれる。 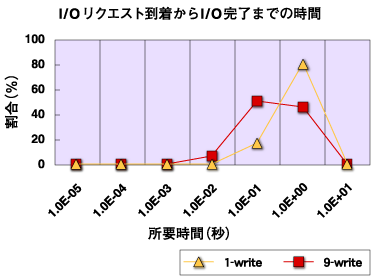 図3:I/Oリクエスト到着からI/O完了までの時間(buffer) パターン1(CPUアイドル型)はディスクが1台のI/O、パターン9(CPUビジー型)はディスクが4台のI/Oである。パターン1の平均値が非常に高く、常にI/Oリクエストがほぼ上限(512)近くまで溜まっていたことが見てとれる。これはデバイスドライバのルーチンによるI/Oリクエストの処理が飽和状態にあったことを表しており、一般的にデバイス側の処理限界に突き当たっていることが多い。 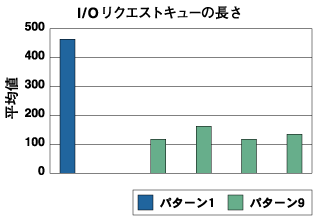 図4:I/O要求が来た時のリクエストキューの長さ(blkqueue) | ||||||||||||||||||||||||
| ロック競合型 | ||||||||||||||||||||||||
誌面の関係で詳細は省略するが、LKSTを利用することによって、ロックを待つ場所(busywait)とロックの時間(spinlock)を測定することができた。その分析結果より性能上問題となるグローバルなカーネルロックを発見した。 グローバルなカーネルロックは、これまでにカーネルの改良によってその数を減らしてきたが、MIRACLE LINUX V3.0にもまだある程度残っている。カーネル2.6.10と比較すると、さらにいくつかのグローバルロックが削除されている。これらについてMIRACLE LINUXでも削除を検討することが可能と考えられるため、今後の課題のひとつとしたい。 | ||||||||||||||||||||||||
表7:グローバルなカーネルロック | ||||||||||||||||||||||||
| 前のページ 1 2 3 4 次のページ | ||||||||||||||||||||||||
| ||||||||||||||||||||||||
| ||||||||||||||||||||||||
| ||||||||||||||||||||||||
-
人気記事ランキング
-
-
連載


新着記事
KubeCon Europe 2026、膨大なSBOMを可視化するGUACの創始者KusariのTim Miller氏にインタビュー 7月13日 6:01 「Unity IAP 5.4」リリース、Scaniverse フィジカルAI向けUSDZ書き出し機能を追加 ほか 7月13日 6:00 LegalOn Technologiesの長内毅志さん 7月10日 6:30 物体検出のYOLOと新興AIハードウェアAxelera AIがツールとハードウェアの最適化を発表。最適化されたモデルと推論を実行できるソリューションを解説 7月10日 6:00 【AIに何を任せ、どこで止めるか】Loop Engineeringから考える仕事の設計 7月9日 6:30