| ||||||||||||
| 前のページ 1 2 3 4 次のページ | ||||||||||||
| データベースレプリケーションの方式 | ||||||||||||
データベースレプリケーションには、RAIDなどOSやハードウェアで行う以外に、大きく分けて次の2つの方式があります。
| ||||||||||||
| 非同期マスタスレーブ | ||||||||||||
SQLの処理を行うマスターサーバは1つです。マスターでなされたデータの変更部分を、別のサーバ(スレーブ)に転送してデータベースのコピーを作ります。実装例として、Slony-Iなどがあります(図3)。 Slony-I GBorg -- The Development website http://gborg.postgresql.org/project/slony1/projdisplay.php | ||||||||||||
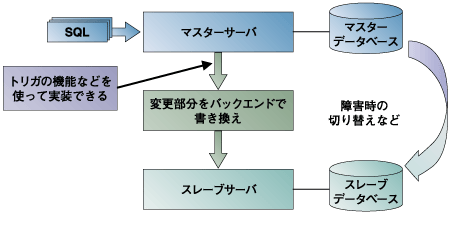 図3:非同期マスタースレーブ方式のレプリケーション | ||||||||||||
| 同期マルチマスター | ||||||||||||
SQLの処理を行うマスターサーバが複数あり、それぞれのマスターがデータベースの複製を持ちます(図4)。各マスターは別々にSQLを処理し、データの変更は即時にすべてのマスターのデータにも繁栄されます。実装例として、PostgresForestやPGClusterなどがあります。 PostgresForest NTT DATA - サービス&プロダクト http://www.nttdata.co.jp/services/postgresforest/index.html | ||||||||||||
PGCluster PGClusterトップ http://pgcluster.projects.postgresql.org/jp/index.html | ||||||||||||
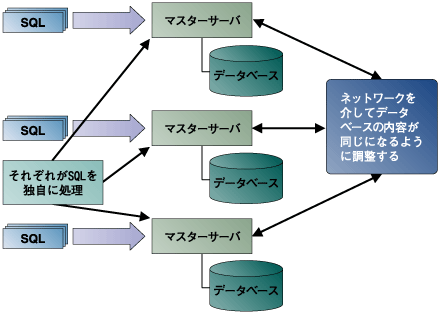 図4:同期マルチマスターでのデータベースレプリケーション | ||||||||||||
| データベースの複製は難しい | ||||||||||||
データベースの複製の方式が2つあるのは、データベースの複製を作ることがそれほど簡単ではないからです。その理由について解説します。 上で示したどの方法でも、SQLを使ってデータベースのレプリケーションを行います。簡単に図5の例で説明しましょう。 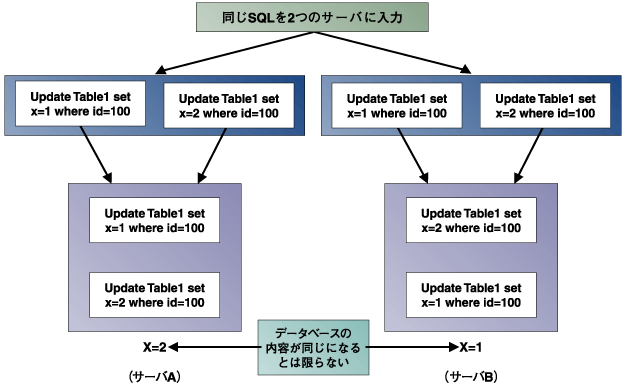 図5:データベースの複製は難しい (画像をクリックすると別ウィンドウに拡大図を表示します) 図5では、2つのアプリケーションが同時に、同じデータを書き換えています。この実行順序は、それぞれのサーバで実行しているOSのスケジューラで決まってしまいます。 同じSQLを2つのレプリケーションサーバに渡しただけでは、図5のサーバA、サーバBの2つの結果のどちらになるかは実行してみなければわからず、結果として2つのレプリケーションサーバのデータは違うものになってしまい、レプリケーションになりません。 SQLの実行順序を同じにしたとしても、データベース内部でのデータの書き換えの順序まで同じになるようにしなければなりません。これがデータベースレプリケーションでもっとも難しいことなのです。 | ||||||||||||
| 前のページ 1 2 3 4 次のページ | ||||||||||||
| ||||||||||||
| ||||||||||||
| ||||||||||||
-
人気記事ランキング
-
-
連載


新着記事
「Proxmox VE」とは? 製品群の全体像と仮想化基盤として注目される理由 7月31日 6:30 LFがOSSの脆弱性協調対応イニシアティブ「Akrites」を発足、CRA準備状況レポートは改善どころか悪化、ほか 7月31日 6:20 NVIDIAら37社が「Open Secure AI Alliance」設立――AIエージェントのセキュリティは重みの非公開では守れない 7月30日 6:20 【クラウドネイティブ会議】厳格な統制と開発者体験を両立する、Wiz Baseにおけるゴールデンパスの実践 7月30日 6:00 その「ソーシャルログイン」は大丈夫? OAuth/OIDC実装の3つの落とし穴 7月29日 6:30