| ||||||||||||||||
| 1 2 3 次のページ | ||||||||||||||||
| 今回の内容 | ||||||||||||||||
第1回では、昨今のビジネスシーンにおいて、既存のデータを徹底活用するためのツールとして全文検索機能の重要性を説明し、その実現手段の1つとしてLudiaの概要を解説しました。 第2回では、まず全文検索機能に要求される事項と考慮すべきトレードオフの観点を説明します。次に商用製品を含めた製品比較を行い、オープンソース「Ludia」にどのような特徴があり、どの程度の機能があるのかを解説します。 | ||||||||||||||||
| Ludia Ver.0.9 12月12日にLudia Ver.0.9が公開されました。主な変更点は次の通りです。
詳細はSourceForgeのサイトを参照してください。 SourceForge.jp:Project - Ludia http://sourceforge.jp/projects/ludia/ | ||||||||||||||||
| 全文検索機能の仕組み | ||||||||||||||||
全文検索に関しては、文書データ処理のための自然言語処理をはじめ様々な研究がなされており、論文なども多数存在し、これらの中には専門用語が多数含まれています。以降では、情報システムと関わりが深い項目に絞り、それらを説明していきます。 | ||||||||||||||||
| 適合率と再現率 | ||||||||||||||||
全文検索機能では「性能」や「安定性」といった、どのソフトウェアにも要求される事項のほかに、利用者が考慮しなくてはならない観点があります。それは適合率と再現率です。 適合率とは、検索結果として得られたものの中に検索を依頼したユーザが期待する結果をどれくらいの割合で含んでいるかという指標です。従って適合率が高いということは、どれだけ期待する文書が含まれ、期待しない文書が少ないかということを意味します。期待しない文書のことを「ノイズ」といいます。 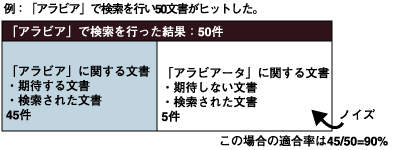 図1:適合率 これに対して再現率とは、期待する内容を含んだ文書のうちにどれだけの文書を検索できたかを示す指標です。従って再現率が高いということは、期待する文書を検索漏れすることなく検索できたことを意味します。本来なら検索すべきでありながら、検索できなかった文書のことを、「漏れ」といいます。  図2:再現率 適合率と再現率の関係をイメージ化すると図3のようになります。 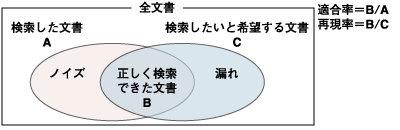 図3:適合率と再現率 | ||||||||||||||||
| 適合率と再現率のトレードオフ | ||||||||||||||||
利用者が全文検索を行う場合、適合率・再現率とも100%を望みます。しかし、文書が自然言語で書かれていて、送り仮名や記述にバラつきが存在する以上、100%の適合率・再現率を得ることは困難です。そのため、適合率・再現率ともに少しでも100%に近づける努力を行うわけですが、この両者はトレードオフの関係にあります。 まず、適合率を高めようとするケースを考えてみます。ここではノイズを減らせばよいので、条件の評価のやり方を厳密にし、少しでも期待しない可能性がある文書を排除すれば、ノイズを削減でき適合率が高まります。しかし、これでは本来期待するはずの文書を除外する可能性が高まり、再現率が下がります(図4の左)。 逆に再現率を高めようとする場合、少しでも適合する可能性がある文書をすべて検索すれば、再現率が高まります。しかし、今度は適合しない文書を検索する可能性が増加し、適合率が下がります(図4の右)。 以上のように適合率と再現率はトレードオフの関係にあります。 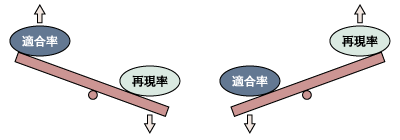 図4:適合率と再現率はトレードオフ では、適合率と再現率の割合を変化させるには、どのようにすればよいでしょうか。全文検索の基本的な仕組みとして、単語インデックスとN-gramがあります。この2つをうまく使い分けることにより、適合率と再現率をコントロールします。次項より、単語インデックスとN-gramについて説明します。 | ||||||||||||||||
| 1 2 3 次のページ | ||||||||||||||||
| ||||||||||||||||
| ||||||||||||||||
| ||||||||||||||||
-
-
連載


新着記事
焦りは禁物?「特化」の前に「汎用」を。エクサウィザーズが語る東海製造業における生成AI成功の秘訣 6:30 SUSE、インフラのレジリエンスとオープンソースAIで日本のDXを加速——ベンダーロックインからの脱却を支援 6:20 「HAMi」でKubernetes上のGPUメモリ分離の仕組みを理解し、共有を試してみよう 7月15日 6:30 「C/C++」の「RayLib」でコンソールゲーム「Color」を開発してみよう 7月15日 6:30 Gartner、エージェント型AIによってエンタープライズ・アプリケーション向け支出の2,340億ドルがリスクにさらされるとの見解を発表 7月14日 6:30