| ||||||||||||||||||
| 1 2 次のページ | ||||||||||||||||||
| 統計情報を確認する | ||||||||||||||||||
PostgreSQLの問い合わせオプティマイザは、統計情報をもとにインデックスを使うかどうかなどの判断をしています。たとえば、図9の場合はインデックスが使われるのに、図10の場合はインデックスが使われないのは、オプティマイザが結果件数が多い場合は順スキャンの方が速いと判断するからです。 | ||||||||||||||||||
test=# EXPLAIN SELECT * FROM accounts WHERE aid | ||||||||||||||||||
図9:EXPLAINの使用例3 | ||||||||||||||||||
test=# EXPLAIN SELECT * FROM accounts WHERE aid | ||||||||||||||||||
図10:EXPLAINの使用例4 | ||||||||||||||||||
| こうした判断の材料となるのがシステムカタログのpg_statsにある統計情報です(注3)。統計情報は列ごとに管理されており、先ほどの例では、図11のようにすればaid列に関する統計情報を参照できます。 ※注3:pg_statsはビューなので実際の統計情報は別の場所に格納されていますが、とりあえずはここを見れば統計情報がわかると考えてかまいません。 | ||||||||||||||||||
test=# SELECT * FROM pg_stats WHERE tablename = 'accounts' AND attname = 'aid'; | ||||||||||||||||||
図11:統計情報の参照 | ||||||||||||||||||
| 統計情報についてそれほど詳細に立ち入る必要はありませんが、histogram_boundsとmost_common_valsには注意を払う必要があるかもしれません。これらは検索の結果抽出される行数を計算するために使われる値で、インデックスを使用するかどうかに大きな影響を与えます(注4)。 ※注4:テーブルの行数に関する統計情報はpg_classに格納されています。 | ||||||||||||||||||
異なる値が多い場合は、histogram_boundsがNULL以外の値になり、テーブル行数を10等分したときに、境界となる列の値が配列として記録されます。これをグラフで表すと図12のようになります。 | ||||||||||||||||||
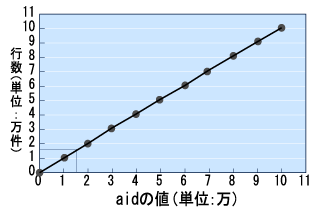 図12:aidと行数の関係 | ||||||||||||||||||
| 1 2 次のページ | ||||||||||||||||||
| 書籍紹介 まるごと PostgreSQL! Vol.1  日本での市場シェアNo.1(オープンソースRDBMS部門)データベースソフトPostgreSQLの最新情報を、開発メンバーを含む豪華執筆陣が多面的かつ詳細に解説します。PostgreSQL用クラスタリング/レプリケーションソフト、PostgreSQL⇔Oracle移行、PostgreSQLによる大規模サイト構築法、新バージョンPostgreSQL 8.0先行レビュー、PostgreSQL用.NETデータプロバイダ等々、他では読めない貴重な記事が満載です。 日本での市場シェアNo.1(オープンソースRDBMS部門)データベースソフトPostgreSQLの最新情報を、開発メンバーを含む豪華執筆陣が多面的かつ詳細に解説します。PostgreSQL用クラスタリング/レプリケーションソフト、PostgreSQL⇔Oracle移行、PostgreSQLによる大規模サイト構築法、新バージョンPostgreSQL 8.0先行レビュー、PostgreSQL用.NETデータプロバイダ等々、他では読めない貴重な記事が満載です。発売日:2004/12/08発売 定価:\1,890(本体 \1,800+税) | ||||||||||||||||||
| ||||||||||||||||||
| ||||||||||||||||||
| ||||||||||||||||||
-
人気記事ランキング
-
-
連載


新着記事
NVIDIAら37社が「Open Secure AI Alliance」設立――AIエージェントのセキュリティは重みの非公開では守れない 6:20 【クラウドネイティブ会議】厳格な統制と開発者体験を両立する、Wiz Baseにおけるゴールデンパスの実践 6:00 その「ソーシャルログイン」は大丈夫? OAuth/OIDC実装の3つの落とし穴 7月29日 6:30 KubeCon Europe 2026、新興のオブザーバビリティ企業Hygroundの製品責任者にインタビュー。生成AIの使用を前提にした新世代オブザーバビリティとは 7月29日 6:00 障害発生時でも継続運用を実現する「MySQL」と「PostgreSQL」の「高可用性構成」を理解する 7月28日 6:30