コスト削減につながる11g R2の5大新機能
小規模データベース・サーバー統合にRAC技術を応用
■2. RAC One Nodeによる小規模データベースの集約
2つ目もRACに関する新機能です。複数サーバーで構成する通常のRACとは異なり、1台のサーバーで稼働するOracle Databaseのための新機能がRAC One Nodeです。Oracle VMなどの仮想化ソフトウエアのように、小規模データベースを1台のサーバーに集約できます。
さらにRAC One Nodeでは、次のような機能を備えています。
(1)データベース稼働中にも物理サーバー間を移行可能に“OMotion”
「この機能があるから仮想化を導入する」という声が多いのが、Live Migrationと呼ばれる、アプリケーションやOSがオンラインの状態で物理サーバー間を移行させる機能です。これまでは、稼働中のデータベースでLive Migrationを行うことは、実行中のトランザクションが保証されないなどの課題がありました。OMotionでは、トランザクション実行中でも安心して物理サーバー間の移行が可能です。
(2)パッチ適用のダウンタイムを最小化“ローリング・パッチ適用”
OMotionの機能を利用して物理サーバー間を移動させることで、パッチ適用によるダウンタイムを最小化することができます。
(3)データベース障害時にも、高速なフェール・オーバーが可能に“自動フェール・オーバー”
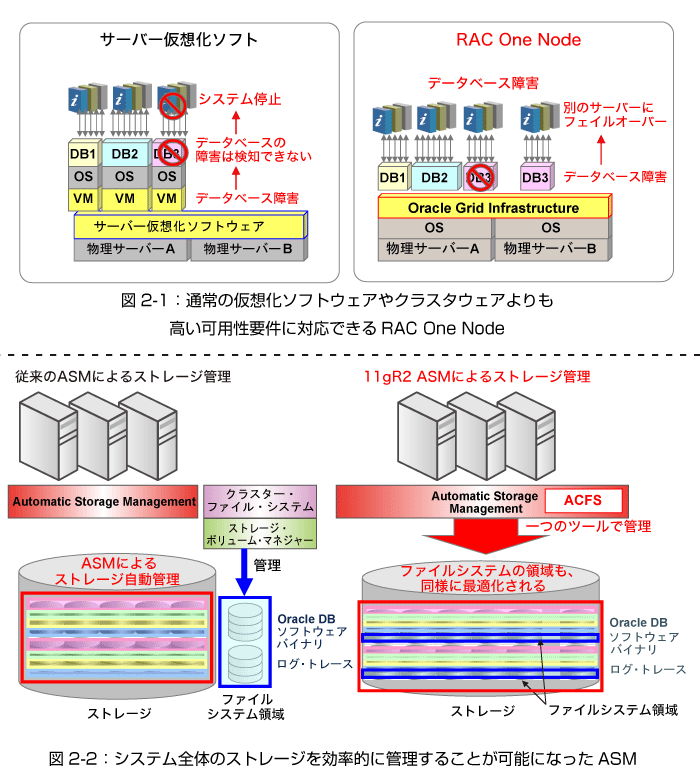
仮想化ソフトウエアも可用性を高める機能を提供していますが(Oracle VMの場合はOracle VM HA)、基本的にはデータベース・インスタンスの障害を検知できませんでした。OMotionでは、データベース・インスタンス障害時にもフェール・オーバーを自動的に行います(図2-1)。
RAC One Nodeのまとめは以下の通りです。
・データベースの機能だけで、小規模データベースの集約が可能に
・通常の仮想化ソフトウエアやクラスタ・ソフトウエアよりも高い可用性要件に対応でき、OMotion機能によるローリング・パッチ適用、自動フェール・オーバーを実現
ストレージ管理やメモリー活用が強化
■3. Automatic Storage Managementの機能拡張によるストレージ管理の一元化
新機能の3つ目は、Automatic Storage Management(ASM)の進化です。
第2回(http://thinkit.jp/article/1044/2/)で紹介したASMは、S.A.M.E.(Stripe And Mirror Everything)と呼ぶストレージ設計の概念「すべてのディスクにデータを均等に分散配置し、かつミラーリングも行うことで、効率性・パフォーマンス・可用性を最適化する」を実現するために提供されているボリューム・マネージャ兼ファイル・システムです。このASMも11g R2では大幅に拡張されています。
図2-2のように、これまでのASMは、基本的にデータベース・ファイルだけを管理対象としていました。この点については、「別途ファイル・システムを用意しないといけないから管理負荷が増えてしまう」という声を聞くことがありました。
11g R2のASMでは、新たにASM Cluster File System(ACFS)が登場しました。これにより、従来管理外にあったソフトウエア・バイナリやログ・トレースなどもASMで管理することが可能になりました。
さらに、ACFS以外にも数多くの機能拡張が行われ、従来の対象であったデータベースだけでなく、システム全体のストレージ・レイヤーを効率化できるようになっています。
ASMのまとめは以下の通りです。
・データベースのストレージを効率的に管理できる → より広くシステム全体のストレージを効率的に管理できる
■4. ハードウエアの進化を最大限に活用するIn-Memory Parallel Query
新機能の4つ目は、パラレル・クエリの進化です。
「Oracle 7.3」から実装が始まったパラレル・クエリも、昨今のハードウエア状況に合わせて進化しています。
従来のパラレル・クエリでは、メモリのサイズが十分でないという旧来の環境を考慮して、常にディスクへのアクセスを実行(Direct Path Read)していました。これに対し、現在のパラレル・クエリであるIn-Memory Parallel Queryは、その名の通りメモリ上にデータを展開してパラレル・クエリを実行します。つまり、従来のパラレル・クエリに比べ、メモリ・リソースを最大限に活用することで、高速な処理が可能です。
また、RACの活用により、複数サーバーの広大なリソースを利用できるようになります。加えて、データ圧縮と組み合わせることで、より多くのデータをメモリ上に展開することが可能になります。
In-Memory Parallel Queryのまとめは、以下の通りです。
・従来のパラレル・クエリは、メモリを利用せず、常にディスク・アクセスを行って実行していた → メモリにデータをキャッシュし、パラレル・クエリを実行することで高速な大容量処理が可能に