| ||||||||||||
| 前のページ 1 2 3 次のページ | ||||||||||||
| 実現性は? | ||||||||||||
データベースは非常に大きく、また複雑なソフトウェアです。データベースのコアの部分だけでもソースコードで数10万行の規模になります。しかも、この中のモジュールは大変複雑で深い関係にあります。このような大規模なソフトウェアをゼロから実装するのは大変難しいのです。 しかしながら、データベースにもPostgreSQLやMySQL、Firebirdといったオープンソースのソフトウェアがあります。これらはすべて完全なデータベースであり、必要な機能の多くはすでに実装されているのです。これらを基にすれば、共通の機能をそのまま使用して並列分散データベースが実装できるはずです。 筆者は、実際にPostgreSQLを用いた並列分散データベースの実験を行っています。全体の構成は図5に示す通りです。 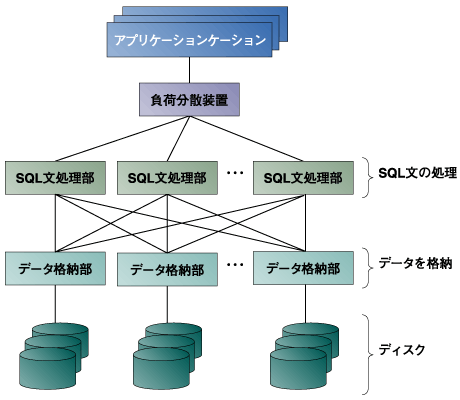 図4:スケールアウトしたデータベースのイメージ 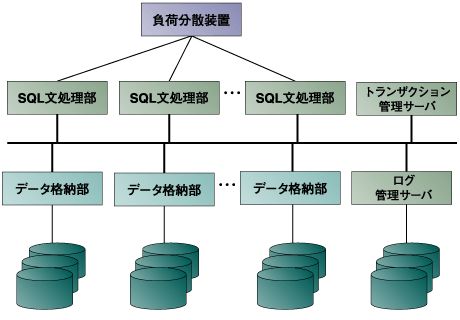 図5:PostgreSQLをベースにした並列分散データベース例 PostgreSQLを基にしてどの程度実用に近いものができるかは今後の課題です。興味ある結果が出ることを期待しながら実験を進めています。 | ||||||||||||
| まとめ | ||||||||||||
第2回と第3回に渡ってデータベースを分割し、サーバの規模が大きくならないようにし、これらを並列に動作させることで全体の効率を上げる可能性について紹介しました。実験結果は今後の機会をいただいて紹介していきます。 | ||||||||||||
| 前のページ 1 2 3 次のページ | ||||||||||||
| ||||||||||||
| ||||||||||||
| ||||||||||||
-
人気記事ランキング
-
-
連載


新着記事
「Proxmox VE」とは? 製品群の全体像と仮想化基盤として注目される理由 7月31日 6:30 LFがOSSの脆弱性協調対応イニシアティブ「Akrites」を発足、CRA準備状況レポートは改善どころか悪化、ほか 7月31日 6:20 NVIDIAら37社が「Open Secure AI Alliance」設立――AIエージェントのセキュリティは重みの非公開では守れない 7月30日 6:20 【クラウドネイティブ会議】厳格な統制と開発者体験を両立する、Wiz Baseにおけるゴールデンパスの実践 7月30日 6:00 その「ソーシャルログイン」は大丈夫? OAuth/OIDC実装の3つの落とし穴 7月29日 6:30