MySQL Workbenchを使ってデータモデリングを学んでみよう

「データモデリング」とは?
さて、いきなりWorkbenchホームページのModelsからモデリング!を開始する前に、すこしデータモデリングについてのお話をさせてください。
みなさんが今利用しているMySQLを含むRDBMSは1970年代にIBMのE.F.コッド博士によってなされた提案を源流として、今日まで発展を続けてきました。その発展過程において、現実の世界におけるデータ要件と、データベースの設計とを結びつける方法論が必要になりました。
1976年にP.チェン博士によって提案されたER図はその役目を担うことが可能であり、各種改良を重ねられて今日まで利用されています。現実世界のデータをどのように扱うかをまとめ、ER図のような図版で視覚化したものを「データモデル」といい、そのデータモデルを組み上げていくことを「データモデリング」といいます。
データモデリングの過程、および結果として作成されたデータモデルはデータベースを利用した様々なシーンで役立ちます。例えばゼロからデータベースを設計する場合の繰り返しの改善や、既存のデータベースからデータモデルを逆生成(リバースエンジニアリング)して、開発者や関係者と共有することにより、関連する人々の「共通言語」として機能することが期待できます。
ただ残念なことにデータモデリング自体は奥が深く、とても本記事だけでは書ききれませんので、以下のThink ITの記事や、後ほど例として取り上げるミックさんの書籍、また参考書籍にて勉強することをおすすめします。
ここではWorkbenchでの簡単なER図の作成と、フォワードエンジニアリング、シンクロナイゼーション、リバースエンジニアリングの単純な例をあげるにとどめます。イメージとしてはワープロについて簡単な文字入力と操作について取り上げるレベルと考えていただければよいと思います。むろん、ワープロの操作を覚えただけではすばらしい文章が書ないように、Workbenchの操作を覚えただけはすばらしいモデリングはできませんので、その点はあしからずご了承ください。
Workbenchならではの注意点
WorkbenchはER図のようなデータモデルを独自のファイル(*.mwb)に格納します。ゼロから作成したデータモデルはこのファイルに格納されることになります。またリバースエンジニアリングは、データベースの実体(もしくはSQLスクリプト)からER図を作成し、mwbファイルに納めることになりますし、フォワードエンジニアリングはその逆の動作となります。シンクロナイゼーションは、ER図とデータベースの実体との差分を確認し、ER図を元にデータベースの実体を変更するためのDDL文の作成(および実行)ということになります。
もし、テーブル名やカラム名などに日本語を扱う場合には、以下の手順で日本語を表示できるようにしてください。
ホームからEdit-Preferences...を指定しAppearanceタブからConfigure Fonts For: をDefault(Western)から、Japaneseに変更する。
今回の記事の操作はmydbというスキーマ(データベース)に行われます。接続先のMySQLサーバーに作成(フォワードエンジニアリングやシンクロナイゼーション時)されますので、ご注意ください。
実際にテーブルを作成してみよう
テーブルを作成
WorkbenchのホームページからModelsの+アイコンをクリックします。図1.の画面が表示されますので、Add Diagramをダブルクリックします。EER Diagramタブが現れますので、Diagramペインをクリックしてアクティブにして、tを押します(もしくはツールアイコンからテーブルをクリックしても同じです)。するとアイコンが指の形になりテーブルのアイコンと共に表示されますので、適当な位置でクリックすると初期値table1というテーブルが配置されます。

テーブル名を「会社」にして、カラムを追加
table1を右クリックして、メニューからEdit 'table1' in New Tab...を選択するとテーブル編集の画面が表示されますので、図2.のように入力してください。PKは主キー(Primary Key), NNはNULL不可(Not Null)を示します。これで1つ目のテーブルは完成です。
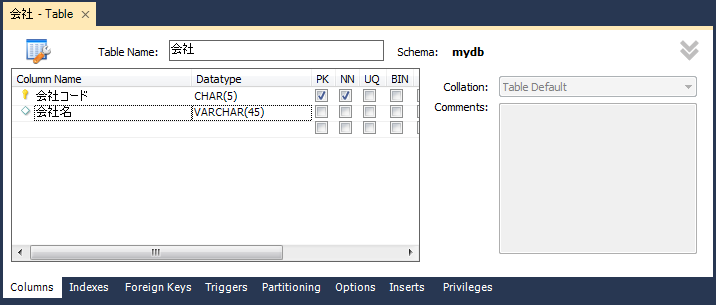
(余分なカラムを追加してしまった場合には、次のページで説明する方法で削除してください。)
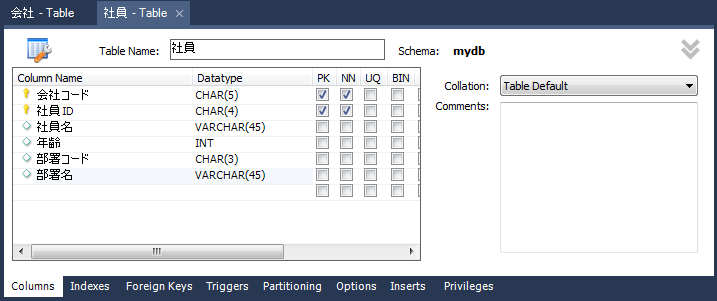
2つ目のテーブル「社員」を作成
1つ目と同様の手順にて「社員」テーブルを作成します。図3.のように入力してください。Datatypeはコンボボックスから選ぶことも可能です。長さを伴わないものはそのまま、長さを伴うものは長さ指定のところにカーソルがある状態で選択されます。例えばVARCHAR()のように選択して、長さを入力する形になります。
リレーションの設定
先ほどまでの作業でER図のE(Entity)としてのテーブルを作成しました。今度はR(Relation)を設定してみましょう。
Diagramペインで数字の6を押す、もしくは1:nのピックアップつき実線アイコン(アイコンメニューの一番下のアイコン)を押すと、ポインタが指の形になり、既存のカラムを利用したリレーションシップ設定アイコンと共に表示されます(当該アイコンが見えず選択できない場合、Workbench自体のウィンドウサイズを広げるか、アイコンメニューの一番下の右向き三角部分をクリック・表示して選択)ので、社員テーブルの会社コードカラム→会社テーブルの会社コードカラムの順にクリックすると図4のようにリレーションが設定されます。設定モードから抜けるにはESCキーを押すか、アイコンメニューの矢印アイコンをクリックしてください。

EntityとRelationの表記方法はIEに準拠したものですが、もう一つの代表的な表皮方法であるIDEF1X(アイデフワンエックス)で表記することも可能です。メニューのModelからObject NotationおよびRelationship NotationにてIDEF1Xを指定してください。
ただし現状Object NotationをIDEF1Xにすると日本語がうまく表記できません。また変更は当該モデル(mwbファイル)のみで有効です。
フォワードエンジニアリング
作成したデータモデルは実際にデータベースに適用(DDLとして)できます。これをフォワードエンジニアリングといいます。
DatabaseメニューからForward Engineer...を選択しForward Engineer to Databaseウイザードで各種指定を行います。Connection OptionsのStored Connectionから前回の記事で設定した接続(Local5614)を指定して、後はNextボタンを押していき、Review SQL Scriptまで進みます。ここでは実際にモデルから生成されたクエリが図5.のように確認できます。そのままCommit Progressまで進むと実際にデータベースに適用されます。

第二正規系から第三正規系に変更
実は先ほど作成したモデルは第二正規化されたものでしたが、ここではそれを第三正規化してみましょう。
第三正規化するには社員テーブルから部署名(と部署コード)を分割した部署テーブルを作成します。部署コードをCHAR(3) PK、部署名をVARCHAR(45)で設定した部署テーブルをこれまでと同じ手順で作成します。そして先ほどの手順と同様に社員テーブルの部署コードカラム→部署テーブルの部署コードカラムの順にリレーションを設定します。こうなると社員テーブルの部署名カラムは不要になりますので、社員テーブルを右クリックしてEdit '社員' in New Tab...を選択し、社員-Tableタブで部署名を選択し、右クリックメニューからDelete Selectedを選びカラムを削除します。結果として図6のようになります。

シンクロナイゼーション
モデルを第二正規形から第三正規形にしたため、実際のMySQLの定義とはズレができてしまいましたので、ここで同期をとってみましょう。
DatabaseメニューからSyncronize Model...を選択し、ウイザードを進めていくとSelect Changes to Applyでモデルと実際のズレが図7.のように表示されます。進めていくとReview DB Changeで実際に発行するDDLが確認できますので、問題ないならそのまま進めてFinishします。

ここまで作成したモデルは任意のタイミングでセーブすることができます。FileメニューのSave Modelからセーブしておきましょう。ここではSample3NF.mwbとしてセーブしておきます。セーブした内容はWBのホームからModelsとして確認できます。
リバースエンジニアリング
本記事の内容と参考文献(今回の第二正規形→第三正規形はミックさんの書籍p.93~101に準拠したものです)を元にいろいろとモデリングを試行錯誤することも勉強になりますが、実務で一からデータモデルを作成する機会はなかなかないのではないかと思います。そのような場合、既存のデータベースをリバースエンジニアリングして、ER図を関係者で共有することにより、既存のデータベースの把握や、拡張作業時のやりとりがスムーズに行えることが期待できます。
リバースエンジニアリングには、Workbenchのホーム画面、Modelsの>アイコンをクリックしてCreate EER Model from Databaseを選択します。Select Schemasにて対象としたいデータベース(スキーマ)を選択後、処理を進めていけば既存のデータベースのER図が生成されます。FileメニューからExport...で好みのフォーマット(PNG, PDF等)に変換出力して役立ててください。
SQLエディタ
「データモデリング、敷居が高いなぁ」というむきにはSQLエディタを試してみることをおすすめします。
SQLエディタはWorkbenchのホーム画面から登録した接続(Local5614)をダブルクリックすることにより起動します(図8)。非常に多くの機能があるため、ここでは手軽に使えて便利な機能をご紹介します。
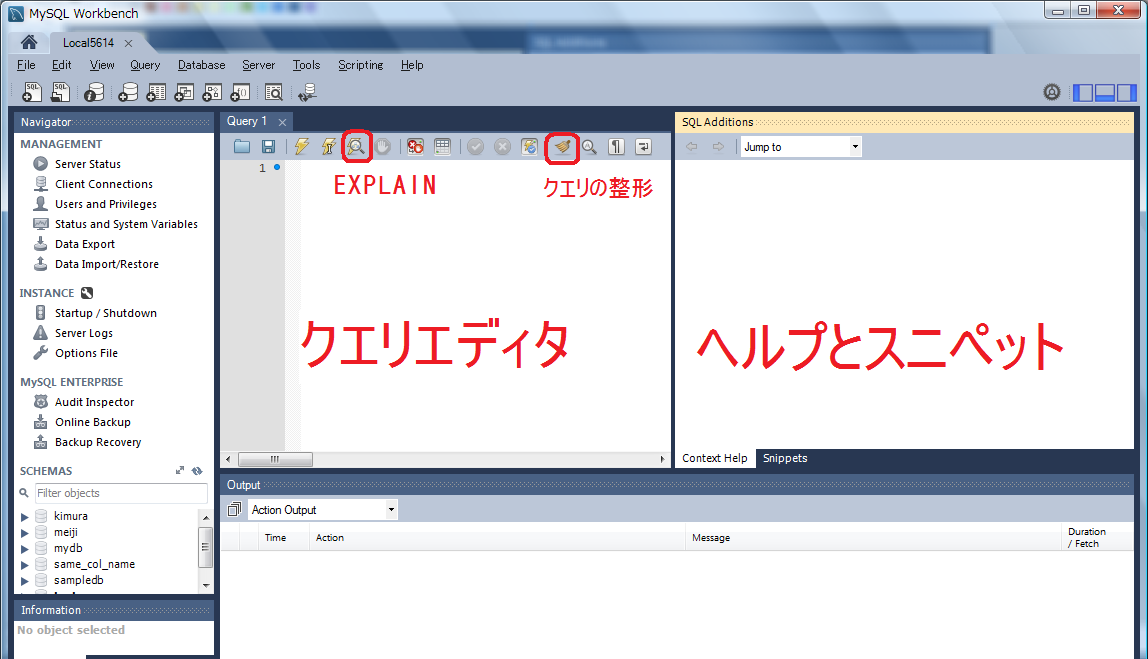
クエリの入力支援機能
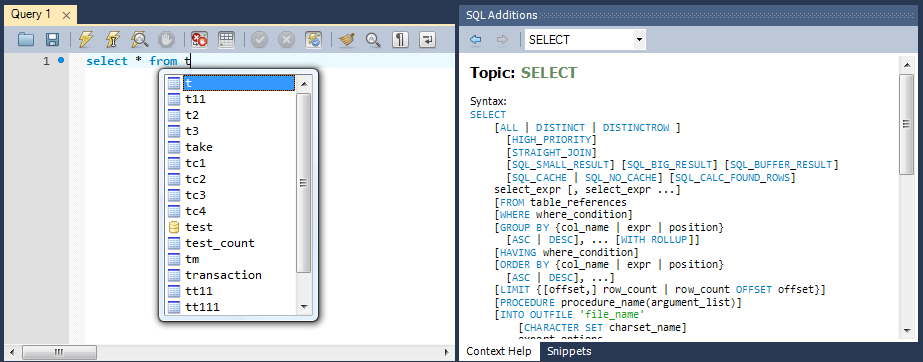
クエリを入力していくと、その文脈にあった形でデータベースオブジェクト(表やビュー、それらを構成するカラム)や関数の候補を表示してくれます(図9)。これは長いデータベースオブジェクト名や関数を利用する際に便利です。またエディタの右のペインでは文脈にあわせてヘルプを(Context Help)表示してくれますので、対話的にゼロからクエリを作成する場合に細かな文法を参照しながら作業を行えますので便利です。
また右のペインではContext Help以外にSnippets(スニペット)を選択することができます。スニペットはクエリそのものやクエリの一部分を保存して再利用できるシンプルな仕組みです。よく利用するクエリのフレーズを記録して利用したり、複雑なクエリを生成する際、クエリの一部を一時保管するのにも利用できます。例えば筆者の場合は特定の範囲(下記の例だと2012年)の日付時刻をランダムに出すために以下のフレーズをよく使います。
1 | SET @FROM = unix_timestamp('2012-01-01 00:00:00'); |
2 | SET @TO = unix_timestamp('2013-01-01 00:00:00'); |
3 | select from_unixtime(FLOOR(@FROM + RAND() * (@TO - @FROM))); |
これをQuery Editorに入力し、Snippetsタブを選択した後、☆に+(Snippetsは☆でイメージしています)のアイコンを押すことにより、この内容のスニペットが作成できます。スニペットを利用する際は右クリックメニューで以下のいずれかを選びます(もしくはそれぞれ☆に→Iのアイコン、☆に↑のアイコンを押します)。
- Insert Snippet at Cursor: スニペットをカーソル位置に挿入
- Replace Editor Content with Snippet: エディタの内容をスニペットで置換
クエリの整形、EXPLAIN機能
他人が書いた複雑で長大なクエリは理解するのも一苦労です。また、ミドルウエアから自動生成されたクエリは独特の記法であまり人間が読んで理解できるようにはなっていないことがしばしばです。
このようなクエリを外部から読み込んだ場合には、クエリの整形機能を使ってみましょう。Query Editorにクエリを表示してから、ほうきのアイコンを押すと整形されます。
メニューからEdit-Format-Beautify Queryを選択することでも可能です。
クエリが効率よく実行されているかどうかは、オプティマイザがそのクエリに対してどのような実行計画を選択したか、を確認する必要があります。
クエリの実行計画を知るにはEXPLAIN句を利用するのですが、Queryエディタからは稲妻に虫眼鏡のアイコンを押すことにより、クエリにEXPLAIN句をつけた結果を容易に取得することができます。
メニューからQuery-Explain Current Statementを選択することでも可能です。
MySQL 5.5以前のバージョンに接続した場合はSELECT文しかEXPLAINの実行はできませんが、5.6以降のバージョンに接続した場合には、更新クエリ(INSERT/UPDATE/DELETE)でも実行計画の取得が可能です。
なおオプティマイザの動作や実行計画についての初歩的な知識を得たい方は、参考文献にあげた拙書の「5.4 プランとヒント」をご参照ください。
さて次回はWorkbench 6.0からは機能を充実させ別プロダクトになったMySQL Utilitiesについて便利なツールを説明したいと思います。
【参考文献】
- ミック『達人に学ぶDB設計徹底指南書』翔泳社(発行年:2012)
- 渡辺幸三『データモデリング入門』日本実業出版社(発行年:2001)
- 梅田弘之『グラス片手にデータベース設計 販売管理システム編』翔泳社(発行年:2003)
- 羽生章洋『楽々ERDレッスン』翔泳社(発行年:2006)
- 木村明治『プロになるためのデータベース技術入門 MySQL for Windows 困ったときに役立つ開発・運用ガイド』技術評論社(発行年:2012)











