データベースの運用管理にログの情報は不可欠ですが、オープンソースのDBMSであるPostgreSQLが出力するログは、直接取り扱うのに適した形式とは言えません。そこで本記事では、オープンソースのログ収集ツールであるFluentdを使って、PostgreSQLのログを運用管理に活用しやすい形に加工する方法を紹介します。
PostgreSQLの運用管理に使う稼働統計情報とログ
データベースを安定稼働させるには、データベースを健全な状態に保つ運用管理が必要不可欠です。データベースの運用管理には一般的に死活監視、リソース監視、性能分析、チューニング、バックアップといった項目が挙げられますが、まずは監視によって正しく現状を把握することが、運用管理の第一歩と言えるでしょう。PostgreSQLで監視に使える機能には、稼働統計情報とログがあります。稼働統計情報はPostgreSQLの様々な稼働情報を蓄積したもので、通常は専用のビューにSQL文で参照できます。稼働統計情報では、接続中のクライアントの実行状態や実行中のSQL文、データベース単位のコミット/ロールバック回数やSQLの実行回数、テーブル単位で更新されたレコード数といった情報を参照でき、性能分析やチューニングに活用できます(リスト1)。
リスト1:稼働統計情報からデータベースのキャッシュヒット率を取得
# SELECT datname, round(blks_hit*100/(blks_hit+blks_read), 2) AS cache_hit_ratio
FROM pg_stat_database WHERE blks_read > 0
datname | cache_hit_ratio
---------+-----------------
postgres | 99.00
ログにはPostgreSQLサーバから出力された様々な情報が記録されます。例えば、サーバが即停止するような深刻なレベルからサーバの稼働に影響しない警告レベルまで何らかの事象が発生したことを示すメッセージや、処理されたSQL文、チェックポイント、自動VACUUMの実行状況、デッドロックの発生状況といった情報は全てログに出力させることが可能です。またPostgreSQLのログは、任意のファイルにテキスト形式で出力する以外に、syslogやWindowsのイベントログへの出力や、外部ツールで扱いやすいCSV形式での出力も可能です。
リスト2:PostgreSQLのログファイルの中身
[2014-06-26 06:32:14 GMT][11550][53abb2b8.2d1e-21][0][00000](postgres, fluentd, [local], psql) LOG: duration: 20020.457 ms statement: select pg_sleep(20);
[2014-06-26 07:36:38 GMT][17077][53abcc5a.42b5-1][0][00000]LOG: checkpoint starting: time
[2014-06-26 07:36:39 GMT][17077][53abcc5a.42b5-2][0][00000]LOG: checkpoint complete: wrote 4 buffers (0.0%); 0 transaction log file(s) added, 0 removed, 0 recycled; write=0.303 s, sync=0.004 s, total=0.320 s; sync files=3, longest=0.002 s, average=0.001 s
ログにしか出力されない情報もあるため、運用管理にはログも活用したいところですが、PostgreSQLのログにはいくつか扱いづらい点があります。特にPostgreSQLは1つのファイルに全てのログを出力するため、エラーレベルや事象の種別で分割することができず、ログから必要な情報を探したり、分析に活用したりするのが困難です。そこで本記事では、オープンソースのログ収集ツールであるFluentdを使って、PostgreSQLのログを分析しやすい形に加工する方法を紹介していきます。
Fluentdの概要
Fluentdは軽量でプラガブルなログ収集ツールで、Apache License Version 2.0のもとOSSとして公開されており、自由に使うことができます。またFluentdは、ログ管理を3つの層(インプット、バッファ、アウトプット)に分けて管理しており、しかも各層がプラガブルなアーキテクチャになっています。そのため用途に応じたプラグインを追加するだけで、柔軟に機能拡張できるメリットがあります。Fluentdの詳細はドキュメントをご覧ください。
PostgreSQLのログを加工する
ここからはPostgreSQLのログをFluentdで収集し、分析しやすい形に加工する手順を解説します。図1はPostgreSQLサーバが出力したログをFluentdプロセスが収集・加工して、最終的にPostgreSQLデータベースのテーブルにログデータを格納するまでの処理の流れを図示したものです。なお、テキスト形式のログデータをデータベースのテーブルに格納するのは、使い慣れたSQLでログデータの抽出や分析を可能にすることを狙ったからです。
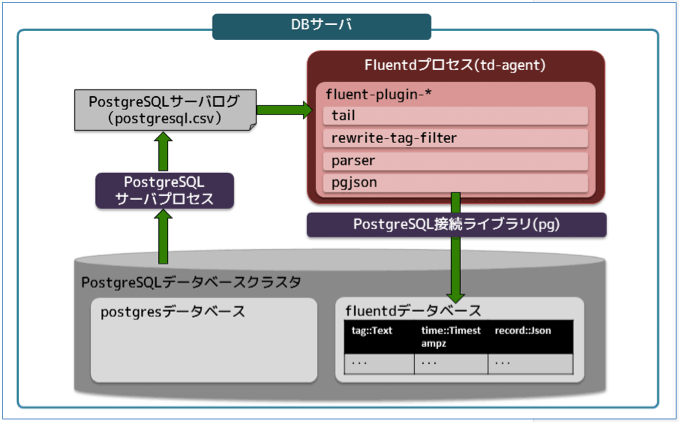
図1:処理の流れ(クリックで拡大)
なお、今回の環境で利用するソフトウェアは以下のとおりです。
| プロダクト名 | バージョン |
|---|---|
| CentOS | 6.4(64bit) |
| PostgreSQL | 9.3.5 |
| td-agent (Fluentd) | 1.1.20(0.10.50) |
| fluent-plugin-rewrite-tag-filter | 1.4.1 |
| fluent-plugin-parser | 0.3.4 |
| fluent-plugin-pgjson | 0.0.4 |
- この記事のキーワード
関連記事
バックナンバー
この記事の筆者

筆者の人気記事
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
