| ||||||||||||
| 前のページ 1 2 3 次のページ | ||||||||||||
| メタデータの限界 | ||||||||||||
では、メタデータさえ情報リソースに付与すればそれで十分であるかというとそうではない。メタデータは所詮、人が恣意的に決めた語彙によるデータフォーマットに過ぎず、異なる人が決めれば異なるデータフォーマットができあがる。 図4では、「メタデータA用に書かれたプログラムA」がメタデータBを理解できない様子をあらわしている。メタデータAを作成した企業Aでは当然そのメタデータAを処理するためのプログラムを作成する。ある日突然メタデータBも処理してくれといわれてもそれは不可能である。 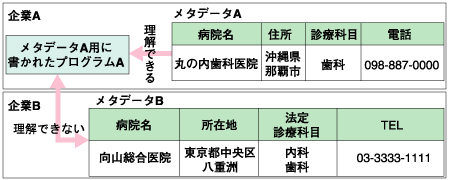 図4:メタデータの限界 出典:野村総合研究所 企業AでメタデータAもメタデータBも処理する必要があるならば、以下のどれかの方法を選択しなければならない。
表1:対応方法 また、例えすべての企業で同じ共通メタデータが利用されたとしても、それはあくまでもデータフォーマット部分だけを共通化したに過ぎず、情報リソース(データ)そのものは依然として人が恣意的に作成したものとなっている。情報リソースそのものも共通化するということは、全世界の人が1つの言語(例えばすべて英語)で情報リソースを記述することよりも困難な話であり、あまりにも非現実的である。 | ||||||||||||
| オントロジーの重要性 | ||||||||||||
先に述べたメタデータの限界を補足し、より広範囲な情報リソースをコンピュータに自律的に処理させるためには、オントロジーの利用が有効である。 オントロジーとは「ある特定分野の概念や知識」のことを指し、「語彙の定義」や「語彙と語彙の関係」を記述したものである。図5は簡単なオントロジーの例である。ここでは、「住所」と「所在地」が同意語であることや「診療科目」が「歯科」の「医者」は「歯医者」であることなどが定義されている。 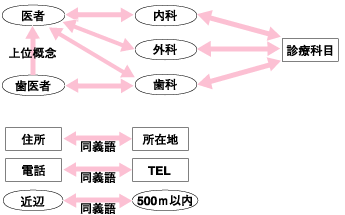 図5:オントロジーの例 出典:野村総合研究所 図6は、図5のオントロジーを検索エンジンに理解させたセマンティック検索の例である。注目していただきたいのは、異なるメタデータを使っているWebサイトの情報リソースを同様に扱えることと、丸の内という文字列がなくとも八重洲が丸の内近辺であることを推論することの2点である。このようにオントロジーという形で事前に語彙が持つ意味を検索エンジンに理解させることで、より人が判断することに近い検索が可能となる(この例ではもちろん自然言語処理も必要であるが)。 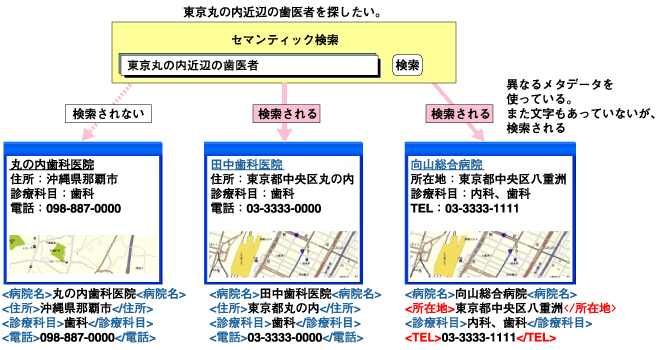 図6:オントロジーを使ったセマンティック検索の例 出典:野村総合研究所 (画像をクリックすると別ウィンドウに拡大図を表示します) | ||||||||||||
| 前のページ 1 2 3 次のページ | ||||||||||||
| ||||||||||||
| ||||||||||||
| ||||||||||||
-
-
連載


新着記事
焦りは禁物?「特化」の前に「汎用」を。エクサウィザーズが語る東海製造業における生成AI成功の秘訣 6:30 SUSE、インフラのレジリエンスとオープンソースAIで日本のDXを加速——ベンダーロックインからの脱却を支援 6:20 「HAMi」でKubernetes上のGPUメモリ分離の仕組みを理解し、共有を試してみよう 7月15日 6:30 「C/C++」の「RayLib」でコンソールゲーム「Color」を開発してみよう 7月15日 6:30 Gartner、エージェント型AIによってエンタープライズ・アプリケーション向け支出の2,340億ドルがリスクにさらされるとの見解を発表 7月14日 6:30