| |||||||||||||||||||||||||||||||||||||||
| 前のページ 1 2 3 | |||||||||||||||||||||||||||||||||||||||
| 多重フィルタの罠 | |||||||||||||||||||||||||||||||||||||||
スパムフィルタの開発は容易ではありません。完璧なものを作ることは本当に困難です。このような状況で、最も一般的に陥りがちな誤りは「不完全なフィルタを多重に用いて、よりよい結果を得ようとすること」です。実際、商用スパムフィルタの中には、入手可能なすべての技術を詰め込んだようなものが数多く存在します。 たくさんのフィルタを通すと水がより綺麗になるように、フィルタをたくさん通せばスパムが到着しなくなるのではないかと考えてしまいがちですが、実際はそうはなりません。ここで見落とされているのが、フォールスポジティブの存在です。正規メールがスパムとして判断されてしまうことは、フィルタを通り抜けたスパムを受信することより深刻な現象です。 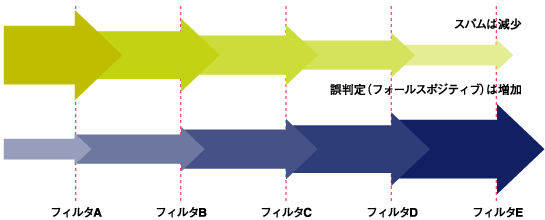 図2:カクテルアプローチ(多重フィルタ)のパラドックス (画像をクリックすると別ウィンドウに拡大図を表示します) | |||||||||||||||||||||||||||||||||||||||
| 多重フィルタの実験 | |||||||||||||||||||||||||||||||||||||||
例えば、表2に示すようなAからFの6種類のフィルタが存在するとします。ここで、すべてのフィルタが独立に効果的に働くと仮定します。
表2:6種類のフィルタ特性 これらのフィルタを重ね合わせた場合の精度と誤判定率は表3のようになります。
表3:多重フィルタの精度と誤判定率 精度とはスパムを排除する確率です。誤判定率とはフォールスポジティブ、つまり、正規メールをスパムと判定する確立です。表3を見るとフィルタを重ね合わせることで精度があがっていますが、同時に誤判定率も増加してしまいます。 一般的にビジネスメールでは誤判定率は限りなくゼロに近くなければならないとされます。悪くても数十万通の内の1通、つまり、0.001%以下でないとビジネスでの使用には耐えられません。 上記の例では、フィルタを単純に重ねただけですが、ベンダーによっては多重化する際にフィルタに重みをつけたり、複雑な多数決方式を採用したりしています。しかし、これらの手法はいたずらに論理を複雑にしてトラブル時の解析を難しくするだけで、上記の例の本質を変えるものではありません。 | |||||||||||||||||||||||||||||||||||||||
| コンテンツベースのパラドックス | |||||||||||||||||||||||||||||||||||||||
スパムか、スパムでないかという判断について、もう一度考えて見ましょう。表4のようなメールはスパムでしょうか?
表4:このメールはスパムか? このメールは、定義上スパムとするべきですし、平均的な受信者はこれをスパムと感じるでしょう。さて、ベイジアンフィルタやヒューリスティックなどのコンテンツベースの手法で、このメールを分析した場合、どうなるでしょうか。この例で、このメールをスパムとしているのは、2の部分です。しかし、統計手法などでは2を認識することは不可能です。1だけの部分ではどのような方法でも、このメールがスパムであることはわかりません。 コンテンツベースを使用することの危険性は、この種類のスパムを受け取ったユーザが、それをスパムとしてフィルタのエンジンにフィードバックしてしまうことです。それによって、フィルタは1に分類される多くの正規メールをスパムと判断するようになってしまいます。 | |||||||||||||||||||||||||||||||||||||||
| トラフィックモニタの危険性 | |||||||||||||||||||||||||||||||||||||||
スパムフィルタの開発者の中には、コンテンツベースフィルタの限界に気づいてケースベースでの技術開発を行ってきました。その、1つが表4の2に注目したトラフィックモニタ型のフィルタです。これは、ハニーポットの変形といえる手法です。 この手法を取っているベンダーは、実際のネットワークのトラフィックを監視しているとしていますが、本当にIX(Internet eXchange)などで監視しているのか、前述のハニーポットに通常のメールボックスからのトラフィックを追加しただけなのかは残念ながら明らかにはされていません。しかし、基本的なアイデアは、同じようなパターンのメールが大量に配信されていれば、それをスパムとみなすというものです。 この方法の大きな欠点は、ニュース配信やユーザが明示的に望んで送ってもらっているオプトイン型のマーケティングメールとスパムとの切り分けをどうするのかということです。あるベンダーは、コンテンツを自動分析することによって可能であると主張しています。しかし、実際のテスト結果を見ると、日本国内の多くの正当なニュース配信だけではなく、英語の著名なメディアのニュース配信もスパムとされてしまっています。 メールを利用して大量の受信者にリアルタイムな情報配信をする正規のビジネスは急速に増加する傾向にあります。当然、このようなサービスに必要があって加入し、メリットを享受しているユーザも急増しています。このような環境で、正規のマスメールをスパムとして誤判定されることは致命的な欠陥です。 | |||||||||||||||||||||||||||||||||||||||
| コラボレーション型フィルタ(Collaboration based Filter) | |||||||||||||||||||||||||||||||||||||||
このように多くのフィルタ技術が課題を抱える中で、今最も期待されているのがコラボレーション型フィルタです。この方式は、DNSBL(DNS-based Blackhole List)のように多くの人々からのインプットをベースにフィルタをしようというアイデアです。詳細は「第2回:コラボレーション型スパムフィルタの仕組み」で解説しましたので省略しますが、いくつかの点でDNSBLと大きく異なっています。
表5:コラボレーション型フィルタの特徴 コラボレーション型フィルタは、スパムとは人間の社会的活動によって決定されるものであるため、メールの世界だけで閉じた定義では正しい判断ができない、という考え方に基づいています。また、Web 2.0の世界のように、利用者が増えるほど精度が増し、さらに利用者が増えるという特性を持っています。今後、最も期待される技術といえるでしょう。 | |||||||||||||||||||||||||||||||||||||||
| 前のページ 1 2 3 | |||||||||||||||||||||||||||||||||||||||
| |||||||||||||||||||||||||||||||||||||||
| |||||||||||||||||||||||||||||||||||||||
| |||||||||||||||||||||||||||||||||||||||
-
人気記事ランキング
-
-
連載


新着記事
NVIDIAら37社が「Open Secure AI Alliance」設立――AIエージェントのセキュリティは重みの非公開では守れない 6:20 【クラウドネイティブ会議】厳格な統制と開発者体験を両立する、Wiz Baseにおけるゴールデンパスの実践 6:00 その「ソーシャルログイン」は大丈夫? OAuth/OIDC実装の3つの落とし穴 7月29日 6:30 KubeCon Europe 2026、新興のオブザーバビリティ企業Hygroundの製品責任者にインタビュー。生成AIの使用を前提にした新世代オブザーバビリティとは 7月29日 6:00 障害発生時でも継続運用を実現する「MySQL」と「PostgreSQL」の「高可用性構成」を理解する 7月28日 6:30