| ||||||||||
| 1 2 3 次のページ | ||||||||||
| はじめに | ||||||||||
これまでスパムフィルタの選定基準やベンチマークテストの手法について解説してきましたが、今回は改めてスパムフィルタを支えている技術について紹介します。自社の企業システムに適したスパムフィルタを選定する上で、フィルタの仕組みやメリット・デメリットを知ることは大変重要です。 なぜなら製品選択によって、メールユーザや管理者の業務が天と地ほど異なるからです。また、「長期に渡って信頼できる技術を選択したい」「現在利用している技術はどのような位置づけなのか知りたい」あるいは「よりよい技術や利用法を知りたい」という方は、やはりある程度スパムフィルタ技術を理解する必要があるでしょう。 しかしスパムフィルタを支える技術は、コンピュータ技術の中でも難解である上、日々進化しています。しかも残念なことに、スパムフィルタ技術を知るための資料はあまり存在していません。そこで、今回は現在市場に出ている技術について、実際の製品評価を行った結果や、市場/学会の様々な情報源から収集したものをベースにして、わかりやすく紹介します。 | ||||||||||
| スパムフィルタの技術の分類 | ||||||||||
スパムフィルタの種類は大きくわけて2種類あります。1つはメールの内容を解析して判定する方式、もう1つはメールや送信者のIDの信用度(レピュテーション)のデータベースを利用して判定する方式です。本連載では、前者を「コンテンツベース(Content Base)」、後者を「ケースベース(Case Base)」と呼びます。 本連載で紹介する技術は、図1のように分類されます。 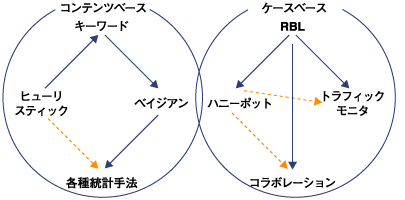 図1:スパムフィルタの分類 | ||||||||||
| キーワードフィルタ | ||||||||||
「キーワードフィルタ」は最も初期のコンテンツベースフィルタです。 スパム発生初期の頃は、スパムの送信者(スパマー)が限られていましたので、単純にスパマーのアドレスを登録して、そのアドレスからのメールを破棄するだけでも効果がありました。しかしすぐにスパマーが増加したことに加え、頻繁にアドレスを変更するようになったため、このような方式では対処しきれなくなりました。 そこで考え出されたのが、スパマーが使いそうな言葉を登録しておき、その言葉を含むメールをブロックするというキーワードフィルタです。この方式は一時期非常に利用されましたが、効果が少ない割りに誤判定が多いものでした。今では、このような技術でフィルタを実現する企業やISP(Internet Services Provider)も少なくなりましたが、この技術が一般的だった頃にはこのフィルタによる被害が頻繁に起こりました。 例えば、米国のある有名女優が乳癌の治療や予防を支援する呼びかけをメールで行ったところ、「Breast Cancer(乳癌)」の「breast(乳)」が原因で多くのISPでブロックされてしまったとか、天文学者がメールの中で使った「Naked Eye(裸眼)」の「naked(裸)」によってブロックされてしまったなどという、笑い話のような実話が多くあります。 | ||||||||||
| ベイジアンフィルタ | ||||||||||
ベイジアンフィルタを説明する前に、「ベイズの定理」を説明しましょう。 ベイズの定理は統計的な予測手法の1つです。例えば「男子学生55人、女子学生45人のクラスで、キティちゃんのストラップを持った女子学生は14人、男子学生は2人います。ドラえもんのボールペンを持った女子学生は3人、男子学生は9人います。さて、ある学生がキティちゃんのストラップを持っていて、ドラえもんのポールペンを持っていなかった場合、女子学生である確率は何%でしょうか?」というような問題を解くときに利用する定理です。 ベイジアンフィルタはこのベイズの定理をスパムフィルタに適用したものです。具体的には、受信者に多くのメールをスパムと正規メールに分類させ、その中で使用されている言葉をスパム辞書と非スパム辞書に登録していき、それに基づいてフィルタしていくという手法です。 一般的に3ヶ月ほど辞書を蓄積(「トレーニング」という)すると使えるレベルの精度になるといわれていました。わかりやすい手法であることもあり、多くの個人用メールソフトに実装されました。 しかし、この手法には大きな欠点がありました。それはトレーニング処理の存在です。ほとんどのソフトは最初から基本的な辞書が組み込まれています。しかし、ソフトをインストールした後、必ずトレーニングが必要です。これは、個人にとっても企業にとっても大きな負担です。 トレーニングが必要な理由は、すべての人や企業に適用できる汎用の辞書が作れないからです。汎用の辞書が最初から用意できれば、個人や企業でのトレーニングのプロセスは不要になり、負荷が軽減されるでしょうが、それは実現できていません。 なぜなら、ベイジアンの有効性が個人の社会行動や嗜好などの要素に大きく依存しているからです。例えば、ゴルフに興味がない人がゴルフ用品の販売のメールを受信したら、高い確率でスパムであると判断するでしょう。一方、受信者がゴルフ好きの人ならばゴルフ用品の特売情報を求めている可能性が高いため、その人にとってはスパムではありません。よって、この条件を汎用のスパム辞書に登録することはできないのです。 さらに、ベイジアンフィルタの有効性を決定的に劣化させてしまったのは、スパマーがベイジアンポイズニング(Bayesian Poisoning)という手法を使うようになったことです。これは、非スパム辞書に入っていることが確実であると予測される言葉を大量に付加することによって判定を有利にしてしまう手法です。 また、HTMLや、Lの小文字を数字の1で置き換えるなどの意図的な誤記、スペースや記号を使って単語の判読を難しくするなどの手法が一般的になり、ベイジアンフィルタの精度は大きく劣化してしまいました。 一部の専門家によれば、ベイジアンフィルタに使われているベイズ定理は「ナイーブベイジアン」と呼ばれ、各単語の出現を独立であると仮定しているため、有効性が一定以上にはならないとのことです。 | ||||||||||
| 1 2 3 次のページ | ||||||||||
| ||||||||||
| ||||||||||
| ||||||||||
-
人気記事ランキング
-
-
連載


新着記事
NVIDIAら37社が「Open Secure AI Alliance」設立――AIエージェントのセキュリティは重みの非公開では守れない 6:20 【クラウドネイティブ会議】厳格な統制と開発者体験を両立する、Wiz Baseにおけるゴールデンパスの実践 6:00 その「ソーシャルログイン」は大丈夫? OAuth/OIDC実装の3つの落とし穴 7月29日 6:30 KubeCon Europe 2026、新興のオブザーバビリティ企業Hygroundの製品責任者にインタビュー。生成AIの使用を前提にした新世代オブザーバビリティとは 7月29日 6:00 障害発生時でも継続運用を実現する「MySQL」と「PostgreSQL」の「高可用性構成」を理解する 7月28日 6:30