自然言語処理を実装するプログラミング言語に求められる特性 まず辞書を用意する。辞書は日本語として可能な単語(形態素)をできるかぎり網羅したものである。一種のデータベースであるが、数十万語レベルの登録がある中から適切な単語を高速に検索するために、特別なインデックス構造を持っている。 たとえば1ページ目で紹介したデモサイト(http://ayu.jurabi.org/)のプログラムでは、日本語の文字コードの特性に合わせた細かいビット演算を用いるインデックス構造を採用している(この構造と検索アルゴリズムは「パトリシア」と呼ばれている。女の子の名前ではないので念のため)。 さらに日本語の場合は、語尾変化のバリエーションが非常に多い。中学か高校あたりで習う、未然形だの連体形だのカ行変格活用だの、を思い出していただければよいかと思う。そこでまずは、辞書には単語の中で変化しない部分(「語幹」と呼ばれる)だけを登録しておき、語幹部分を辞書引きした後、可能な語尾変化のパターンをあてはめて原文と一致するかどうかをチェックする処理が必要になる。 例として「この先生のみとめる人物」という文を辞書引きしてみよう。先頭のほうから、「こ」「この」「この先」「先生」「生」「生の」「の」「のみ」「みとめる」「とめる」「人物」「人」「物」などが単語として得られる。 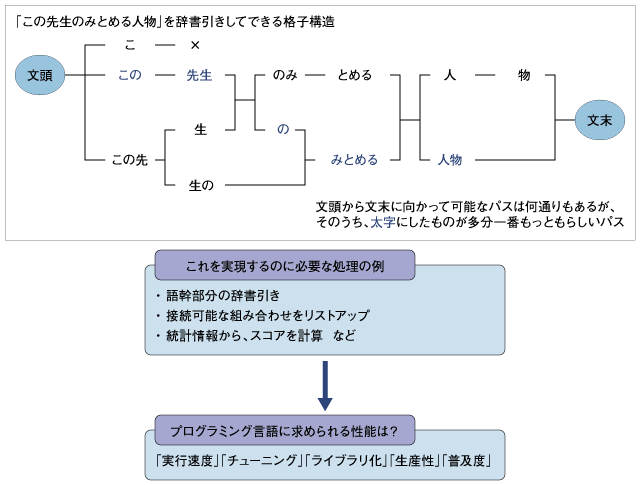 自然言語処理するのに必要な要素 (画像をクリックすると別ウィンドウに拡大図を表示します) この後は、単語の位置関係と品詞などの情報から接続可能な組み合わせだけをリストアップし、単語の出現頻度や組み合わせの妥当性などの統計情報を使って、解のスコアを計算する。最終的にスコアの一番良い解が出力される。おそらく今回の場合では「この/先生/の/みとめる/人物」となるだろう。 このように、自然言語処理では「大量のデータを扱う」「組み合わせの数が多い(工夫しないと爆発する)」「統計的な計算量が多い」という3つの特徴を持っている。 したがって、自然言語処理を実装するプログラミング言語に求められる特性は、まずコードの実行速度と、場合によっては生のメモリにも触れるほど細かなチューニングが可能な柔軟性であろう。 また、形態素解析は自然言語をあつかうさまざまな製品やサービスの部品として使われることが多いので、各種プラットフォームやプログラミング言語から呼び出せるようにライブラリ化できるとよい。さらには製品を素早くリリースするために生産性の高さも必要だ。保守性の観点からは、数多くの開発者によって使用されていることが望ましい。 これらの理由から、自然言語処理に用いるプログラミング言語の選択の規準として、「実行速度」「チューニング」「ライブラリ化」「生産性」「普及度」ができあがる。 では、次にC++、Java、Perl、Rubyから、なぜ「C++」を選択したのかを解説しよう。 | ||||||||||||
| ||||||||||||
| ||||||||||||
| ||||||||||||
| ||||||||||||
| ||||||||||||
-
-
連載


新着記事
焦りは禁物?「特化」の前に「汎用」を。エクサウィザーズが語る東海製造業における生成AI成功の秘訣 6:30 SUSE、インフラのレジリエンスとオープンソースAIで日本のDXを加速——ベンダーロックインからの脱却を支援 6:20 「HAMi」でKubernetes上のGPUメモリ分離の仕組みを理解し、共有を試してみよう 7月15日 6:30 「C/C++」の「RayLib」でコンソールゲーム「Color」を開発してみよう 7月15日 6:30 Gartner、エージェント型AIによってエンタープライズ・アプリケーション向け支出の2,340億ドルがリスクにさらされるとの見解を発表 7月14日 6:30