| ||||||||||||
| 前のページ 1 2 3 4 次のページ | ||||||||||||
| 仮想CPUの分析と考察 | ||||||||||||
冒頭で紹介したESPモジュールとパフォーマンスモニタやその他の分析ツールを利用して、インターネット・メール・プロトコルを使った様々なシナリオをシミュレーションしました。そして、ESX Serverの仮想CPU(VCPU)機能を活用し、VMごとにプロセッサ・リソース量を変える方法を検証しました。以降に、テスト結果と考察を示します。 | ||||||||||||
| Outlook Web Access(OWA)の標準性能〜シナリオ1 | ||||||||||||
シナリオ1では、100ユーザ/インスタンスを処理するVMを1つ選び、OWAテストを実行しました。他のVMは電源を点けた(パワーオン)後、アイドル(休止)状態にしておきました。
表2:100ユーザのOWAワークロードを発生させたときの仮想マシン性能(perfmonデータ) 表2のように、いくつかの主要なパフォーマンス・カウンタを確認すると、VMやインターネット・メール・サービスの稼動状況を追跡調査し、VMのボトルネックを発見するのに役立ちます。例えば、「%Processor Time」は、スレッドの実行に使ったCPU時間を%で表したものです。 上記のテストでは、100人のOWAユーザをシミュレーションしたとき、VMの平均プロセッサ利用率が25%未満となっています。この場合、プロセッサ利用率(%)は、当該VMのプロセッサを測定した値であることに注意してください。コンテキストスイッチは、あるスレッドから別のスレッドへプロセッサが切り替わる(スイッチする)頻度を調べたもので、全体の平均値(1秒あたりのスイッチ数)が算出されます。OWAのようなフロントエンド・サービスは、あまり多くのシステムメモリを使用しません。 このテスト・シナリオ1の場合も、VMは、割り当てた全メモリのうち約440 MBしか使用していません。これは、「Available Mbytes」というPerfmonカウンタを見るとわかります。つまり、VMに割り当てた3,600MBのうち、3,164MBのメモリが未使用のまま空いています。 「Inetinfo Private Bytes」は、Inetinfoプロセスが使用しているメモリ量を測定するカウンタです。このカウンタを一定時間監視すれば、同時使用している(アクティブな)OWAユーザ数に対し、Inetinfoがどれくらいのメモリを使用しているのか調べることができます。システム管理者は、vmkusageツールから取得できるVMの性能情報に加え、上記のようなパフォーマンス・カウンタを見ることで、ゲストOS、アプリケーション、VMごとのリソース利用率や性能特性を調べることができます。 下記の図3は、vmkusageユーティリティで作成したプロセッサ利用率のグラフです。下記の「Esxtopの出力結果」を見ると、ESXサーバ全体のCPU利用率は平均して約13%となっています。 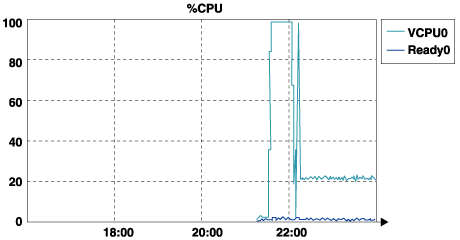 図3:vmkusageで測定したCPU利用率のグラフ また、図3を見ると、ESPが最初のOWAモジュールをロードしたとき、CPU利用率が100%に跳ね上がりますが、その後、テスト・モジュールのロードが完了し、テストが始まると、CPU利用率が安定することがわかります。このように、ESX Serverホスト全体とVMごとのプロセッサ利用率を調べたいときは、vmkusageとesxtopを併用することができます。 Esxtopの出力結果 PCPU: 11.61%, 14.69% : 13.15% used total図中、「VCPU0」とあるのがテストしたVCPUで、シナリオ1の場合、各VMが専用のVCPUを使っています。「Ready0」は、VMのレディ・ステート(実行可能状態)を示します。Ready0を見ると、VMが稼動可能であるにも関わらず、物理CPU上の実行スケジュールが確保できない「待機時間」の割合(%)がわかります。 図3を見ると、VMのCPU平均利用率は約20%、レディ・ステートは5%未満となっています。このようにReady0の値が低ければ、VMが命令の処理待ち状態に置かれていないことがわかります。 この構成では、PCPU0をサービスコンソールとVMで共有しています。2ウェイ・ホストの場合、最初のVMがパワーオンされ次第、VMkernelは、このVMをPCPU1上で稼動するようスケジュールします。PCPU0とPCPU1は、2基の物理プロセッサですが、ハイパースレッディングを有効にすると、1基のCPUがそれぞれ2つの論理プロセッサとして扱われます。PCPU0に対応する論理プロセッサは常にLCPU0とLCPU1となり、PCPU1に対応する論理プロセッサは常にLCPU2とLCPU3になります。 | ||||||||||||
| 前のページ 1 2 3 4 次のページ | ||||||||||||
| ||||||||||||
| ||||||||||||
-
人気記事ランキング
-
-
連載


新着記事
その「ソーシャルログイン」は大丈夫? OAuth/OIDC実装の3つの落とし穴 6:30 KubeCon Europe 2026、新興のオブザーバビリティ企業Hygroundの製品責任者にインタビュー。生成AIの使用を前提にした新世代オブザーバビリティとは 6:00 障害発生時でも継続運用を実現する「MySQL」と「PostgreSQL」の「高可用性構成」を理解する 7月28日 6:30 KVMベースの国産仮想化基盤「Prossione Virtualization」——ライセンス高騰と属人化運用、2つの課題を同時に解決 7月28日 6:20 「DrupalCamp Tokyo 2026」参加レポート ーAI時代に進化するCMS「Drupal」は次のフェーズへ! 7月27日 6:20