| ||||||||||||
| 前のページ 1 2 3 | ||||||||||||
| 効率よくデータベースの内部構造を学ぶために | ||||||||||||
前項のようにオープンソースとはいえ、データベースは実際のシステムで使うように実装してあるので、ソースコードは大規模で使用されている技術要素も大変広範囲に渡ります。 データベースでは、ディスク装置という低速な記憶装置を相手にしなければならず、かつ信頼性を犠牲にすることなく最大限の性能を引き出さなければならないのです。実装での方式の選択理由には、深い背景事情が隠されていることが多く、これらのすべてをソースコードだけで理解することは実際には大変困難です。 一方、一般的にこのようなデータベースの内部構造を知る手がかりになる書籍の情報も、大変限られています(文献1、文献2、文献3)。書籍では、実装の細部に立ち入るには限界があります。そこで、書籍と実際の実装の間を埋めるような教材や実装モデルが必要ではないかと考えています。 参考文献1:Hector Garcia-Molina、Jeffrey D. Ullman、Jennifer Widom、「Database System Implementation」、2000、Prentice Hall、ISBN:0130402648 参考文献2:Raghu Ramakrishnan、Johannes Gehrke、「Database Management Systems」、2003、McGraw-Hill、ISBN:0071151109 参考文献3:鈴木 幸市、藤塚 勤也、「RDBMS解剖学」、2005、翔泳社、ISBN:4798108642 これらの橋渡しとなるモデル実装を行ってはどうでしょうか。システム部品として使い物になるデータベースのソースコードは、数十万行の規模になりますが、高度な最適化や高速化のための工夫を制限することで、数十万行程度のデータベースエンジンが作れるのではないかと期待しています。 データベースエンジンは、図2に示すような構造でできています。 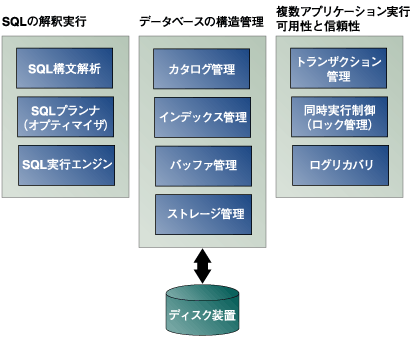 図2:データベースエンジンの構造の模式図
表3:モデル実装の提案 | ||||||||||||
| おわりに | ||||||||||||
本連載ではリレーショナルデータベースを取り巻くトピックスを紹介させていただきました。データベースは理論ではなく、きわめて現実的な技術ですが、その内部構造は複雑を極めています。 一方、ITにおけるデータベースの役割はますます重要になっています。安全にデータベースにデータを蓄積し、安心してシステムを利用できるようにするためには、今後もデータベースの利用のみならず、内部方式に精通した技術者が多く必要になります。これら技術者が多く育つよう、読者の皆様を含め、多くの人々の知恵を絞っていくことを提案することで、一連の連載の締めくくりとしたいと思います。 | ||||||||||||
| 前のページ 1 2 3 | ||||||||||||
| ||||||||||||
| ||||||||||||
| ||||||||||||
-
人気記事ランキング
-
-
連載


新着記事
「Proxmox VE」とは? 製品群の全体像と仮想化基盤として注目される理由 7月31日 6:30 LFがOSSの脆弱性協調対応イニシアティブ「Akrites」を発足、CRA準備状況レポートは改善どころか悪化、ほか 7月31日 6:20 NVIDIAら37社が「Open Secure AI Alliance」設立――AIエージェントのセキュリティは重みの非公開では守れない 7月30日 6:20 【クラウドネイティブ会議】厳格な統制と開発者体験を両立する、Wiz Baseにおけるゴールデンパスの実践 7月30日 6:00 その「ソーシャルログイン」は大丈夫? OAuth/OIDC実装の3つの落とし穴 7月29日 6:30