| ||||||||||||
| 1 2 3 4 次のページ | ||||||||||||
| データベースをスケールアウトする | ||||||||||||
前回はシステム部品としてのデータベースの特徴、データベースの性能がどのようにして決まるか、なぜデータベースを単純に並べただけではスケールアウトできないのかを説明しました。今回は、データベースをスケールアウトさせるにはどうすればよいのかを解説します。 | ||||||||||||
| 基本的なアイデア | ||||||||||||
スケールアウトとは、何台もサーバを並べて全体で処理能力を上げる方法です。WebサーバやJavaのアプリケーションサーバの場合には、共有データが必要ない場合が多いので、単純にサーバを増やして、負荷分散装置(あるいはサーバと不可分散ソフトウェア)を使えばスケールアウトが可能でした。 一方データベースは本質的に共有データを扱うソフトウェアなので、そうは簡単にはいきませんが、図1に示すように、2つの方法のスケールアウトが考えられます。 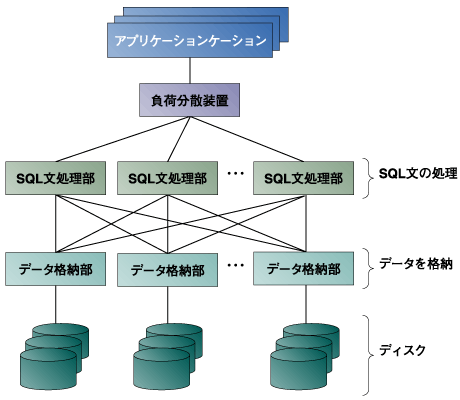 図1:スケールアウトしたデータベースのイメージ
| ||||||||||||
| 2については、前回の解説から、有効性はご理解いただけるでしょう。データベースの性能を決める上では、ディスクの性能が大きな影響をあたえるので、データを格納するサーバを増やして、1台あたりに格納するデータの量が増えないようにしておけば、これらのサーバが連携して全体の性能が上がります。 1については、前回解説しませんでしたが、SQLの処理速度の問題があります。SQL言語は非常に複雑な言語で、C言語と比べても文法は3倍程度複雑です(注1)。 | ||||||||||||
| 注1:C言語の文法を記述しているファイルよりも、SQLの文法を記述しているファイルの方が3倍程度大きいのです。どちらの文法も、yaccとよばれるツールで記述されている例があるので、このような比較ができます。 | ||||||||||||
| しかもC言語は、あらかじめコンパイルしてサーバが直接処理できるバイナリ命令に変換しておくことができますが、SQLの場合は、相手のデータベースの状態がわからなければ処理できないのです(注2)。 | ||||||||||||
| 注2:例えば、あるテーブルの全部のタプルを取り出すSQLを考えます。Select * from Tab1; などが典型でしょう。この場合は、Tab1という名前のテーブルが実際にデータベース内にあるかどうかを確認しないと、データは取り出せません。また、このテーブルの中にどんなカラムがあるかどうかもわからなければ、「*」の中は解釈できません。このように、SQL文の実行手順は、実際にデータベースの中を調べなければ決められないのです。 | ||||||||||||
| つまりSQL文の場合、基本的には実行時に命令を解釈するため、実行手順を作り出す必要があるのです。これには相当の時間がかかります。SQL処理全体の時間の1/3がSQLの翻訳と実行手順の決定という例もあるのです。 これを軽減するために、ストアドプロセジャといって、あらかじめ決まったSQLをデータベースに入れておく手段もありますが、この能力も限られています。そのため、SQLの処理部分を担当するサーバを増やすことにも意味があるのです。 もう一度、図1のサーバ構成を見てみましょう。SQLの構文を処理するサーバとデータを格納するサーバが複数台、相互に接続されています。一見複雑そうですが、基本は上記の1と2のアイデアの組み合わせです。図1を出発点として、このような構成を作り上げるための主な技術的背景を解説していくことにします。 | ||||||||||||
| 1 2 3 4 次のページ | ||||||||||||
| ||||||||||||
| ||||||||||||
| ||||||||||||
-
人気記事ランキング
-
-
連載


新着記事
「Proxmox VE」とは? 製品群の全体像と仮想化基盤として注目される理由 7月31日 6:30 LFがOSSの脆弱性協調対応イニシアティブ「Akrites」を発足、CRA準備状況レポートは改善どころか悪化、ほか 7月31日 6:20 NVIDIAら37社が「Open Secure AI Alliance」設立――AIエージェントのセキュリティは重みの非公開では守れない 7月30日 6:20 【クラウドネイティブ会議】厳格な統制と開発者体験を両立する、Wiz Baseにおけるゴールデンパスの実践 7月30日 6:00 その「ソーシャルログイン」は大丈夫? OAuth/OIDC実装の3つの落とし穴 7月29日 6:30