Apache Kuduによるオンライン処理のチューニング
はじめに
連載第3回「Apache Kuduによるデータ移行処理のチューニング」では、データをKuduへ移行するワークロードの検証結果を紹介しました。最終回となる今回は、大量の電力消費量データをリアルタイムにKuduへ格納しつつ、分析のために大量参照するようなオンライン処理の検証結果を紹介します。また、この検証から得られたKuduの高負荷時の挙動と、チューニングのポイントを紹介します。
オンライン処理の検証内容
オンライン処理の検証では、1秒間隔のレコード書き込みと、書き込まれたレコードの定期的な集約処理を同時に実行しました。この処理を2時間から8時間ほど流し続けて、格納と集約の遅延や失敗が発生しなければ成功とします。例として、毎秒10万レコードを処理する際の流れを図1に示します。
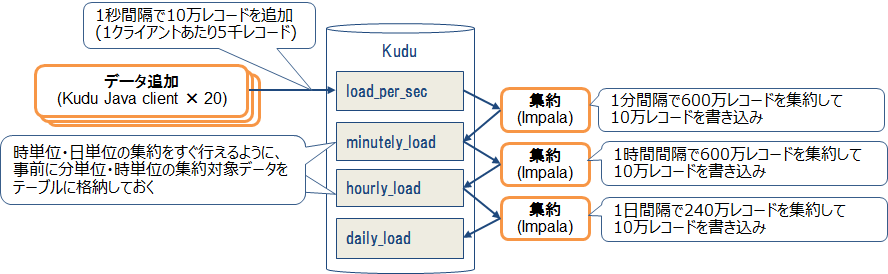
まずKuduのJavaクライアントを使用して、1秒間隔で10万レコードを秒単位テーブル(load_per_sec)に格納します。20個のJavaクライアントで同時に書き込むため、1クライアントあたり5千レコードを格納します。もし、格納リクエストのレイテンシが1秒を超えた場合は、前の格納リクエストが終わり次第、次の格納リクエストを即時実行します。
同時にImpalaを使用して、1分間隔で60秒分のレコード(10万機器×60秒=600万レコード)を機器ごとに合計して、その結果(10万レコード)を分単位テーブル(minutely_load)に書き込みます。また、1時間ごとに60分ぶんのレコードを集約して、時単位テーブル(hourly_load)に書き込みます。同じように1日間隔で24時間分のレコードを合計して、日単位テーブル(daily_load)に書き込みます。なお、前の集約クエリが完了していない場合でも、時間が来たら次の集約クエリの実行を開始します(並列に実行します)。
この集約に使用したImpalaクエリと、クエリの埋め込み変数を以下に示します。
- クエリ:
-
INSERT INTO ${var:target_table} SELECT building_id, floor_id, device_id, cast("${var:begin_time_stamp}" as timestamp) as time_stamp, sum(device_load) as device_load, device_type FROM ${var:source_table} WHERE time_stamp >= cast("${var:begin_time_stamp}" as timestamp) AND time_stamp - クエリの埋め込み変数:
-
- ${var:target_table} : 集約先テーブル名
- ${var:source_table} : 集約元テーブル名
- ${var:begin_time_stamp} : スキャン開始time_stamp
- ${var:end_time_stamp} : スキャン終了time_stamp
レコードの格納と集約処理の流れを図2に示します。
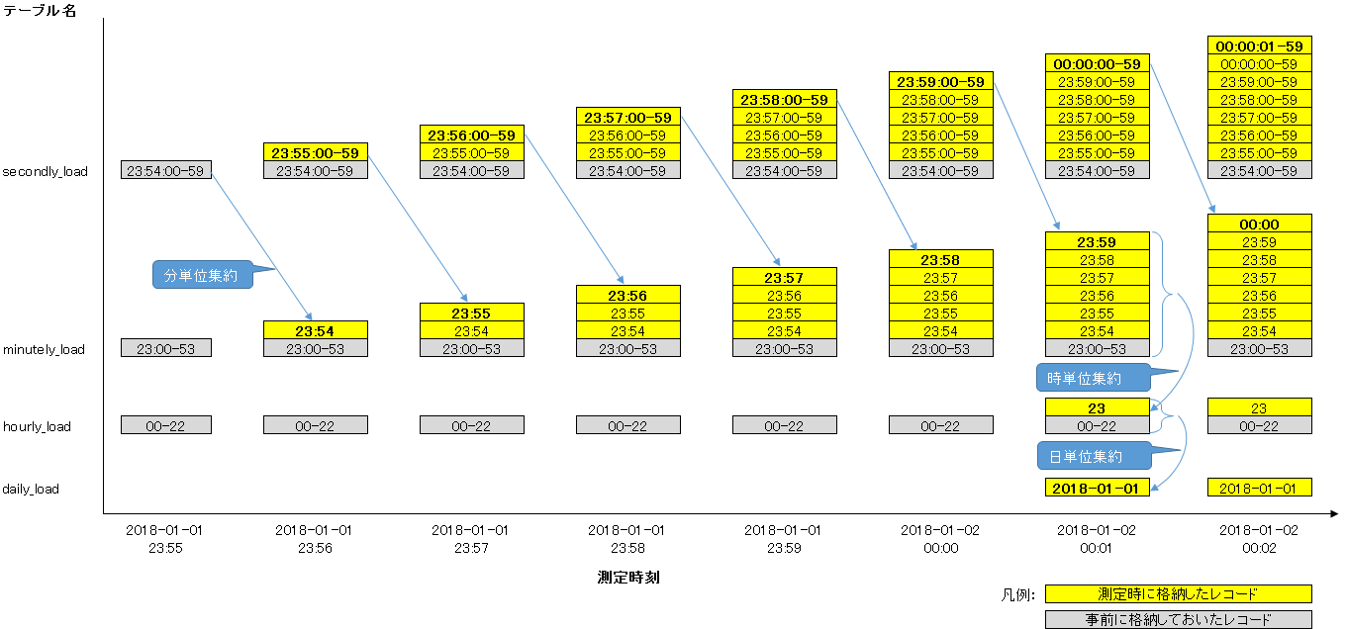
Kuduにデータが無い状態で測定を開始すると、日単位の集約が最初に行われるまでに1日待つ必要があるため、測定に時間がかかってしまいます。今回は測定時間を短縮するため、事前に集約対象のレコードを格納してから測定を行いました。図2に示した通り、オンライン処理の開始時刻は2018-01-01 23:55:00として、集約時に必要な直近1分、1時間、1日のレコードは事前に格納しておきました。これにより、格納開始の6分後(2018-01-02 00:01:00)には時単位および日単位の集約が実行されます。
今回のようなオンラインシステムでは、分電盤で電力データが収集されてからKuduに格納されるまでタイムラグがあるため、収集時のTimestampのレコードを即座に集約することはできません。今回の検証ではレコードがKuduに格納されるのを待つため、レコードのTimestampの1分後に集約を開始します。例えば、2018-01-01 00:00:00 ~ 2018-01-01 00:00:59に発生したデータの分単位集約は、2018-01-01 00:02:00に実行します。
なお、実システムではデータが1分以上遅れて到着することもあり、そのレコードが集約範囲に含まれなくなるという問題があります。しかし今回は性能検証が目的であるため、1分以上遅れてきたデータに対する対処法は考慮していません。
今回の検証では、格納処理と集約処理を一定時間実行して、表1に示す確認項目をすべて満たせば成功としました。
表1:オンライン処理の測定時の確認項目
| # | 確認項目 | 詳細 |
|---|---|---|
| 1. | 格納遅延なし | 格納リクエストの実行開始の遅延時間が1秒以内であること。ただし、一時的なスパイクは問題なしとする。 |
| 2. | 集約遅延なし | 集約リクエストのレイテンシが1分以内であること。ただし、一時的なスパイクは問題なしとする。 |
| 3. | 格納エラーなし | 格納リクエストが失敗しないこと。 |
| 4. | 集約エラーなし | 集約リクエストが失敗しないこと。 |
初期設定における検証結果
毎秒の格納レコード数(機器数)を10万から30万まで増やして測定を実施しました。なお、TServerのメモリ割当量はCloudera Managerのデフォルト設定である4GBとしました。
毎秒10万レコードの処理結果
毎秒10万レコードの処理を実行した際の、格納リクエストと集約クエリのレイテンシの推移を図3に示します。処理の測定期間は2時間弱です。なお、グラフの横軸は測定時の実時間(17:11~19:21)であり、レコードのTimestamp(23:55~02:05)とは異なります。レコードの集約はTimestampに従って実行されます。
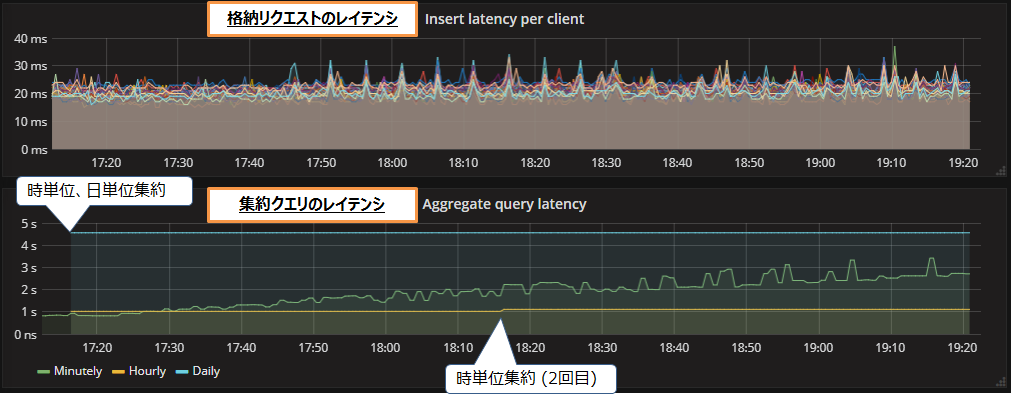
図3上段のグラフは、Javaクライアントの格納リクエストのレイテンシであり、20~30ミリ秒でほぼ一定でした。図3下段のグラフは、Impalaの集約クエリのレイテンシです。分単位集約のレイテンシ(緑色のライン)は、最初の1秒程度から徐々に増加していき、2時間経過後には3秒近くまで上昇しました。時単位集約(黄色のライン)は2回実行され、レイテンシはいずれも1秒程度でした。日単位集約(青色のライン)は最初に1回だけ実行され、レイテンシは4.5秒でした。
格納リクエストと集約クエリのレイテンシはいずれも1分以内であり、遅延や失敗も発生しませんでした。そのため、毎秒10万レコードの処理は成功といえます。
毎秒20万レコードの処理結果
毎秒20万レコードの処理を2時間ほど実行した際の、格納リクエストと集約クエリのレイテンシを図4に示します。
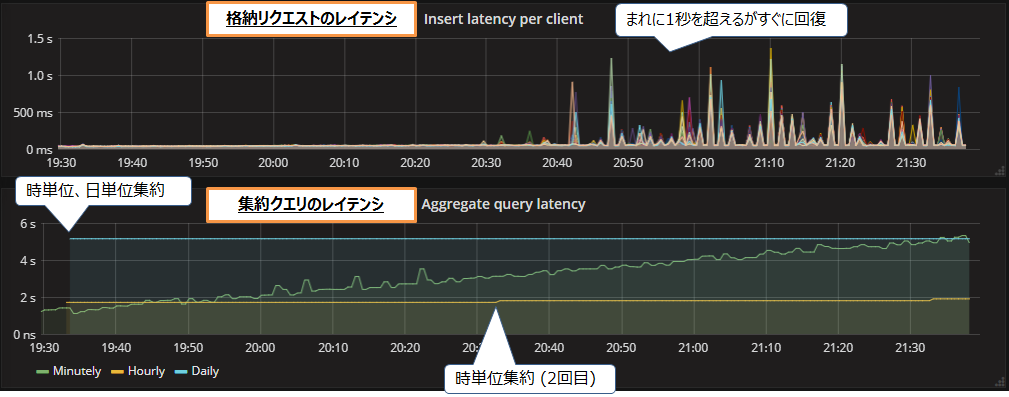
格納リクエストのレイテンシ(図4上段)はスパイク的に1秒を超えることが確認できます。格納は1秒間隔で行うため、レイテンシが1秒を超え続けると、格納の開始が遅延してしまします。ただしこのグラフではたまに1秒を超えるだけなので、格納の遅延はすぐに回復します。集約クエリのレイテンシ(図4下段)は、分単位集約クエリのレイテンシが徐々に増加していきますが、いずれの集約クエリもレイテンシは1分以内であるため問題はないといえます。
なお、格納・集約ともに失敗はありませんでした。以上の結果から、毎秒20万レコードの処理も成功といえます。
毎秒30万レコードの処理結果
毎秒30万レコードの処理を2時間ほど実行した際の、格納リクエストと集約クエリのレイテンシ、および格納開始の遅延時間を図5に示します。
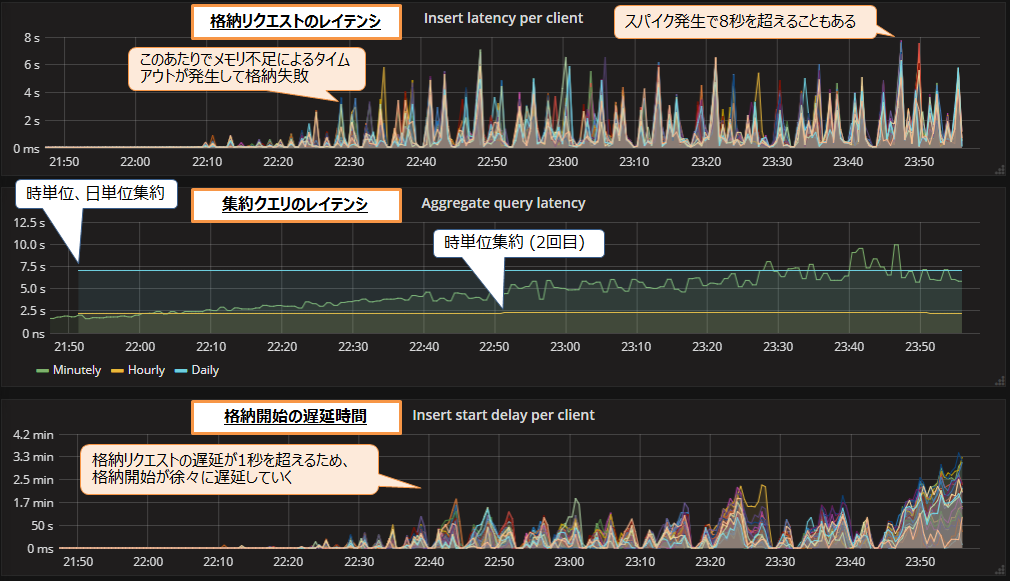
格納リクエストのレイテンシ(図5上段)は1秒を大きく超えて8秒に達することもあります。格納は1秒間隔で行うため、レイテンシが1秒を超え続けると、格納の開始が遅延してしまいます。図5下段のグラフは格納開始の遅延時間の推移を示しています。格納のレイテンシが1秒を超えるため、格納開始が遅延し続けていることが確認できます。また、今回は格納の途中でメモリ不足によるタイムアウトが発生し、一部レコードの格納に失敗しました。
集約クエリのレイテンシ(図5中段)は最大でも10秒のため、問題はありませんでした。分単位集約クエリのレイテンシは途中から低下していますが、これは格納が遅延して集約するレコード数が減ったためと考えられます。
今回は格納の遅延とエラーが発生しているため、毎秒30万レコードの処理は失敗といえます。
初期設定における検証結果のまとめ
初期設定における検証結果のまとめを表2に示します。
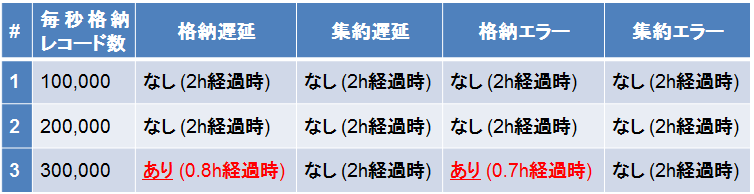
毎秒20万レコードまでの処理は、2時間実行した時点では問題ありませんでした。しかし毎秒30万レコードの処理では、格納開始の遅延とTServerのメモリ不足エラーによる格納失敗が発生しました。以上の結果から、初期設定では毎秒20万レコードの処理が限界といえます。
メモリ割当量変更時の検証結果
初期設定における検証では、毎秒30万レコードの処理でメモリ不足による格納失敗が発生しました。そこでTServerのメモリ割当量を初期設定の4GBから16GB、32GB、64GB、128GBまで増やして測定を行いました。また、初期設定における検証の測定期間は2時間でしたが、メモリを増やすとメモリ上に乗るデータ量も増えるため、今回は測定期間を6時間に伸ばしています。
メモリ割当量16GBの検証結果
メモリ割当量16GBで毎秒30万レコードを処理した際の結果を図6に示します。
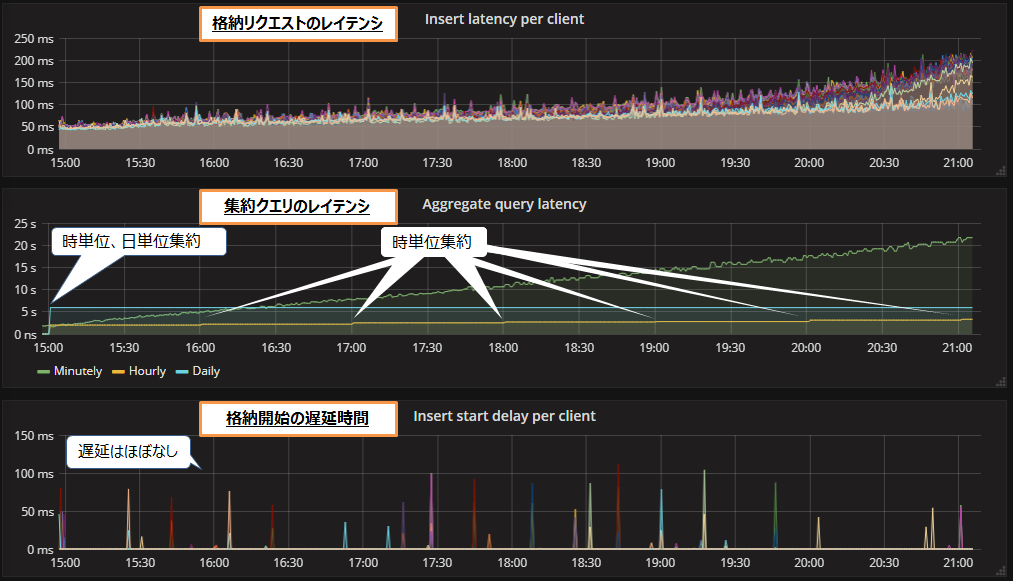
格納リクエストのレイテンシ(図6上段)は、最初の50ミリ秒から6時間後には250ミリ秒まで上昇しています。格納開始の遅延時間(図6下段)については、格納リクエストのレイテンシが1秒以下なので遅延はほぼ発生していません。集約クエリのレイテンシ(図6中段)は、分単位集約のレイテンシが6時間後に22秒まで増加していました。ただし1分以内なので、とりあえず問題なしといえます。
次に、処理レコード数を毎秒40万レコードに増やした際の結果を図7に示します。
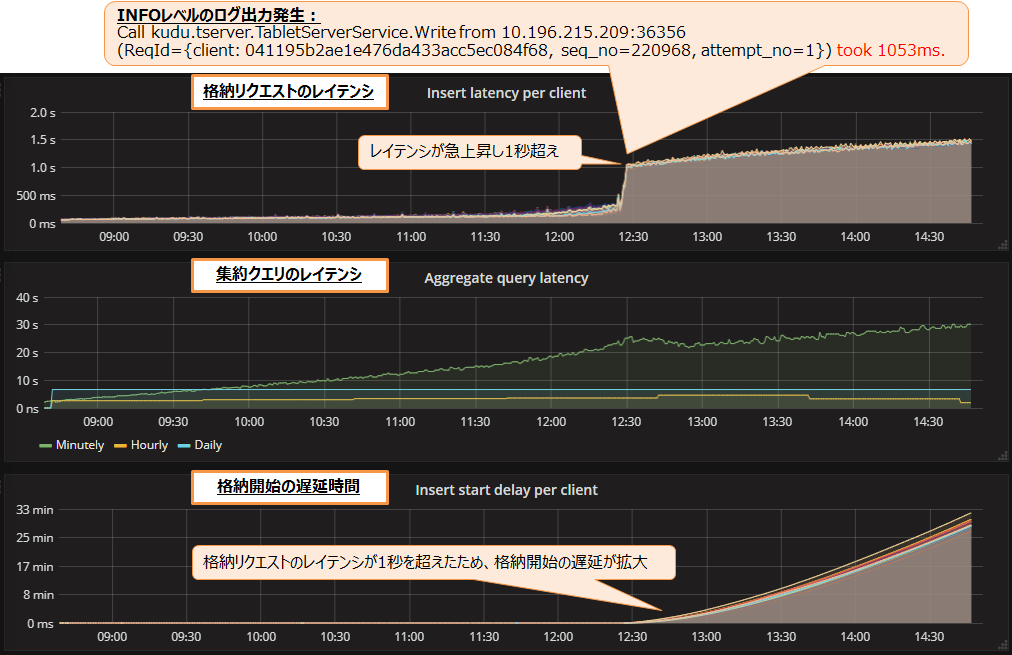
格納リクエストのレイテンシ(図7上段)は、測定開始から3.8時間ほど経過した時点で急上昇し、1秒を超え続けていました。そのため格納開始の遅延時間(図7下段)も拡大し続けていました。
TServerのログファイルには、格納リクエストのレイテンシが急上昇した頃からログが出力され始めました。これはINFOレベルのログであり格納失敗ではありませんが、この処理(kudu.tserver.TabletServerService.Write)のレイテンシが急上昇していることが分かります。
集約クエリのレイテンシ(図7中段)は、分単位集約のレイテンシが6時間後に30秒まで増加しました。途中の12:30-13:00頃にレイテンシが一時的に下がりましたが、これは格納が遅延して集約するレコード数が減ったためと考えられます。
なお、メモリ不足によるエラーは発生せず、レコードの格納リクエストはすべて成功していました。ただし格納が遅延しているため、毎秒40万レコードの処理は失敗といえます。
メモリ割当量32GB、64GB、128GBの検証結果
上記ではメモリ割当量16GBの結果を紹介しましたが、他にも32GB、64GB、128GBで測定を行いました。これらの測定結果のまとめを図8に示します。
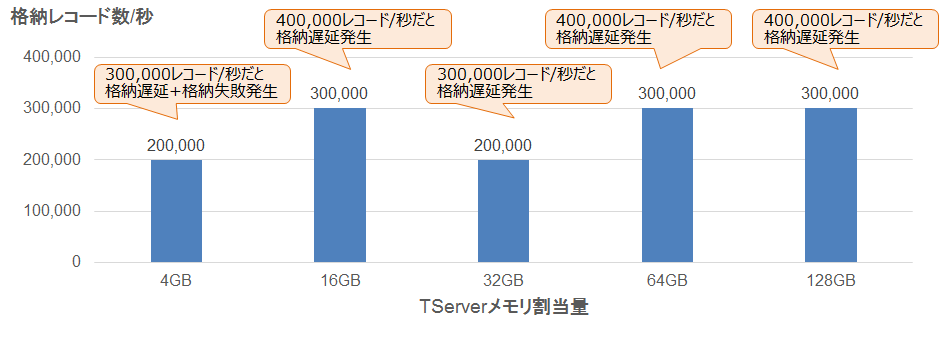
メモリを16GBに増やすことで、メモリ不足によるエラーは解消しました。しかし、メモリを128GBまで増やしても、格納リクエストのレイテンシが急上昇する現象は発生しました。そのため、処理可能なレコード数は毎秒20万から30万程度でほぼ変わりませんでした。
また、今回の検証では6時間処理を実行し続けて測定を行いましたが、より長い時間処理を継続した際に問題が発生しないという保証はありません。特に格納リクエストと集約クエリのレイテンシは増加し続けていたため、より長時間処理を行った場合は問題となる可能性があります。
レンジパーティション間隔1時間における検証結果
これまでの検証結果から、格納リクエストと集約クエリのレイテンシが増加し続けているため、より長時間処理を行った場合は問題となる可能性があることが分かりました。ここまでの検証はタブレット数を固定した状態で行っていたため、毎秒の格納レコード数を増やしていくと1タブレットあたりの最大データ量も増加していました。そのため、1タブレットあたりの最大データ量を減らすことで、レイテンシの増加を抑えられる可能性があります。
1タブレットあたりの最大データ量を減らすには、ハッシュパーティション数を増やすか、レンジパーティションの期間を短くして、タブレット数を増やす必要があります。今回はタブレット切り替え時の性能変化を確認しやすいように、レンジパーティションの期間を短くして検証を行いました。ここまでの検証では秒単位テーブル(load_per_sec)のレンジパーティションを1日単位で設定していたため、今回はこれを1時間に短縮しました。
その状態であたらめて、メモリ割当量32GB、64GB、128GBで測定を行いました。なお、他のテーブルはデータ量がそれほど大きくないため、レンジパーティション間隔は変更していません。
メモリ割当量32GBの処理結果
レンジパーティション間隔は1時間、かつメモリ割当量32GBで、毎秒50万レコードを処理した際の結果を図9に示します。なお、測定期間は6時間です。
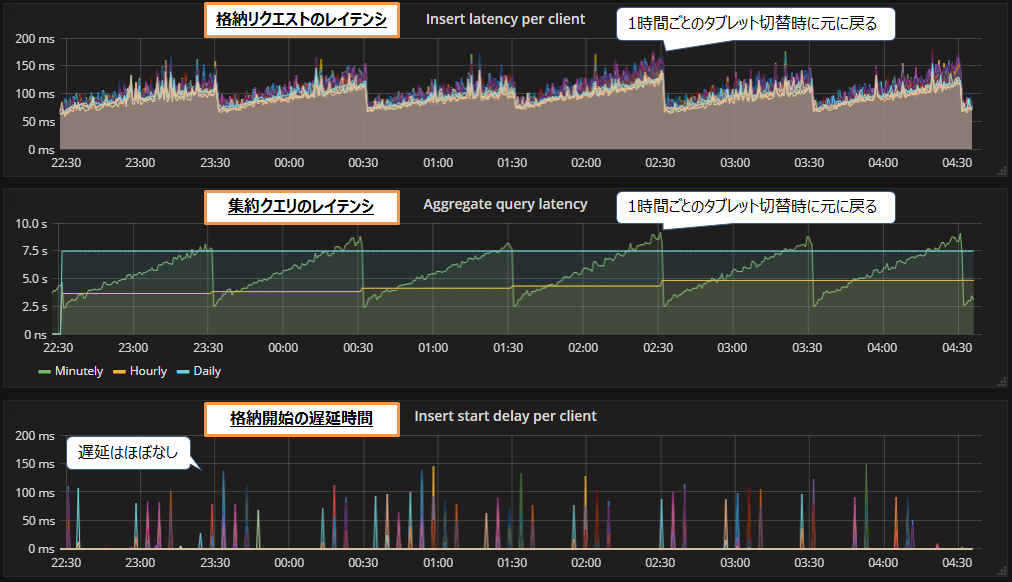
格納リクエストのレイテンシ(図9上段)は、1時間ごとのタブレット切り替え時に大きく低下し、毎回リセットされることが確認できます。中央のグラフは集約クエリのレイテンシ(図9中段)についても、1時間ごとのタブレット切り替え時に毎回リセットされることが確認できます。格納開始の遅延と、格納失敗も発生しなかったため、毎秒50万レコードの処理は成功といえます。
次に、格納レコード数を毎秒60万レコードに増やして測定した結果を図10に示します。
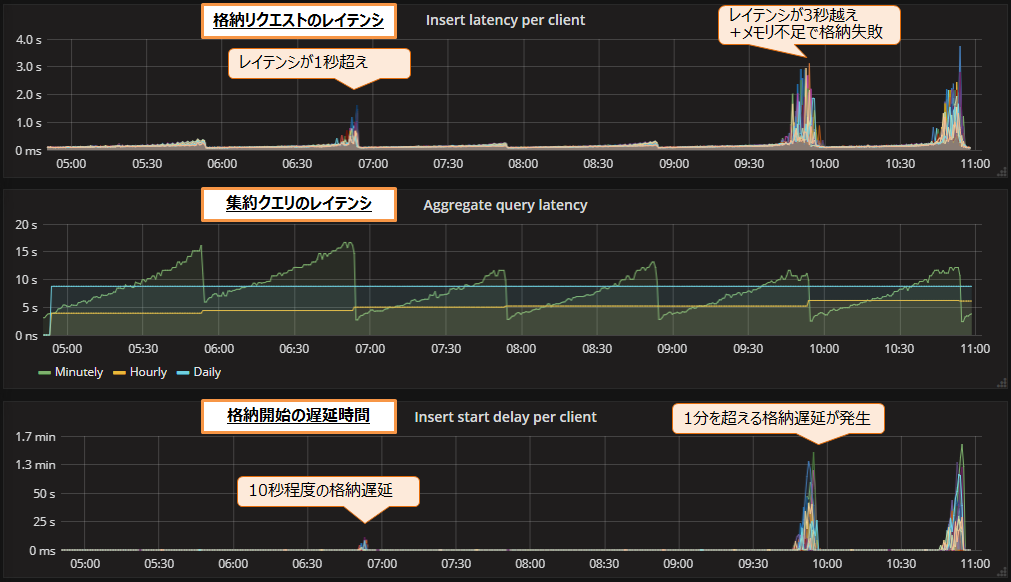
格納リクエストのレイテンシ(図10上段)は、測定開始から2時間ほど経過した時点で急上昇しています。そのため、格納開始の遅延(図10下段)が最大で10秒ほど発生しました。タブレット切り替え時にレイテンシは元に戻りましたが、今度は測定開始から5時間ほど経過した時点で、TServerのメモリ不足によるエラーが発生し、一部のレコードの格納に失敗しました。以上の結果から、毎秒60万レコードの処理は失敗といえます。
メモリ割当量64GB、128GBの検証結果
先ほどはメモリ割当量32GBの結果を紹介しましたが、ほかにも64GB、128GBで測定を行いました。図11にレンジパーティション間隔1時間の測定結果をまとめました。

メモリ割当量32GBでは毎秒50万レコードの処理が限界でしたが、メモリ割当量64GBでは毎秒60万レコード、128GBでは毎秒70万レコードの処理に成功しました。このように、レンジパーティション間隔を1時間に短縮して、1タブレットの最大データ量を抑えることで、格納と集約のレイテンシ増加をリセットでき、格納の遅延と失敗も抑制できました。
オンライン処理の検証結果まとめ
オンライン処理の測定結果まとめを図12に示します。
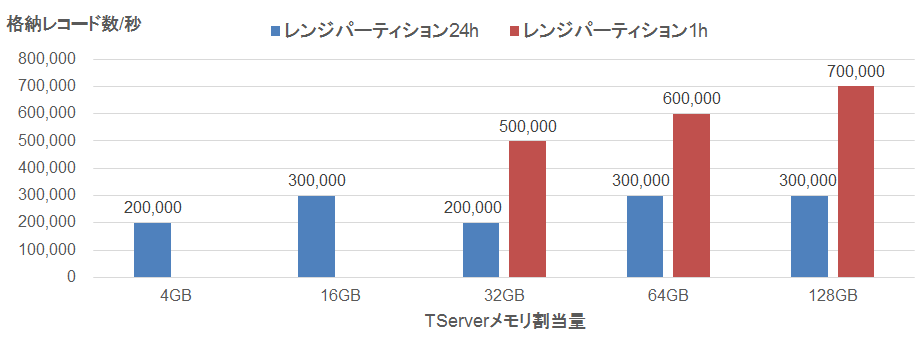
今回の検証では、TServerのメモリ割当量を増やすことで、メモリ不足エラーによる格納失敗を解消できました。ただし、格納レイテンシの急上昇による格納遅延には効果がありませんでした。次に、レンジパーティション間隔を短縮して1タブレットの最大データ量を抑えることで、格納と集約のレイテンシ増加を定期的にリセットできました。これにより、レイテンシの急上昇による格納の遅延や失敗を抑制することができました。
今回の性能検証では、メモリ割当量を128GBに増やし、レンジパーティション間隔を1時間に短縮することで、8時間にわたって毎秒70万レコードの格納とその集約処理が可能であることが確認できました。
検証結果の考察
連載第2回「Apache Kuduのシステム構成と内部アーキテクチャ」で説明した通り、Kuduはタブレットに格納されたレコードを、プライマリキーとなるカラムの値でソートしてから列指向ファイルに書き込みます。今回使用したテーブル定義を表3に再掲します。このテーブル定義では、機器を示すID(building_id、floor_id、device_id)と時刻(time_stamp)をキーに指定しているため、レコードは機器ID→時刻の順にソートされます。
表3:テーブル定義
| # | Column名 | キー | データ型 | サイズ | 説明 |
|---|---|---|---|---|---|
| 1. | building_id | ○ | int32 | 4 bytes | 建物を示すID |
| 2. | floor_id | ○ | int32 | 4 bytes | 建物内の階層を示すID |
| 3. | device_id | ○ | int32 | 4 bytes | 電力を消費する設備や機器を示すID |
| 4. | time_stamp | ○ | unixtime_micros | 8 bytes | 電力測定時の時刻 |
| 5. | device_load | int64 | 8 bytes | 電力消費量(Active power[watts]) | |
| 6. | device_type | int32 | 4 bytes | 設備や機器の種別 | |
今回のオンライン処理では1秒間隔でレコードが到着するため、レコードは時刻順にタブレットへ格納されます。そのため列指向ファイルへ書き出す前に、メモリ上でレコードを機器ID→時刻の順にソートする処理が発生します。また、列指向ファイルのコンパクション(マージ)時にはファイル全体のソート処理が必要となるため、タブレット内のレコード数が増えると処理の負荷も大きくなります。以上の理由から、タブレットサイズが大きくなると格納遅延が発生するのだと推測できます。
プライマリキーを時刻→機器IDの順に設定すればこの問題は解消できます。列指向ファイルへ書き出す前にメモリ上でソート処理が必要なのは同じですが、ファイルのコンパクション時にはソートが不要であり、2つのファイルを結合するだけでマージできます。そのためコンパクション処理の負荷は極めて小さくなります。
しかし、プライマリキーの順番を変更するとレコードの格納順も変更されるため、参照性能に影響を与えます。例えば「ある機器の1日分の秒単位レコードを取得」する場合、機器ID→時刻の順にソートされていたほうが素早く参照できます。一方、「ある時刻の全機器のレコードを取得」する場合は、時刻→機器IDの順にソートされていたほうが素早く参照できます。そのため、想定される参照パターンと、格納性能と参照性能のトレードオフを考慮してプライマリキーの順番を定義する必要があります。
なお、連載第3回で紹介したデータ移行処理では、ImpalaでレコードをソートしてからKuduに格納しているため、タブレット側で列指向ファイルに書き出すまでの負荷はそこまで高くないと考えられます。ただし列指向ファイルのコンパクション時にはファイル全体のソート処理が必要となるため、タブレット内のレコード数が増えると処理の負荷も大きくなると考えられます。
オンライン処理のチューニングポイントと注意点
オンライン処理では以下のチューニングを行うことで、毎秒の格納レコード数を増やすことができます。
- (1)TServerのメモリ割当量を増やす
- TServerのメモリ割当量が少ないと、メモリ不足によるエラーが発生して、レコードの格納に失敗することがあります。このエラーは、メモリ割当量を増やすことで防ぐことができます。
- (2)格納性能と参照性能のトレードオフを考慮してプライマリキーを定義する
- Kuduはタブレットに格納されたレコードを、プライマリキーとなるカラムの値でソートした状態で保持するため、プライマリキーの順番は格納性能と参照性能に影響を与えます。そのため、想定される参照パターンと、格納性能と参照性能のトレードオフを考慮してプライマリキーの順番を定義する必要があります。
- (3)1タブレットの最大サイズを減らす
- オンライン処理では1秒間隔でレコードが到着するため、プライマリキーを機器ID→時刻の順に定義すると、タブレット側のソート処理とコンパクション処理の負荷が増大します。そのため、1タブレットに大量のデータを格納すると、格納と参照クエリのレイテンシが増加します。しかし参照性能を優先する場合、プライマリキーを入れ替えられないこともあります。この場合は、1タブレットの最大サイズを減らすことで負荷の増大を抑えることができます。
1タブレットあたりの最大データ量を減らすには、ハッシュパーティション数を増やすか、レンジパーティションの期間を短くして、タブレット数を増やす必要があります。今回の検証では、レンジパーティションの間隔を短くしてタブレットを頻繁に切り替えることで、クエリのレイテンシ増加をリセットできました。
実際のオンライン処理では、レコードの格納と集約を24時間365日実行し続ける必要があります。今回の検証では、処理を2時間から8時間流して測定しましたが、より長い期間実行し続けた際に、問題が発生しないとは断言できません。今回の検証では、最初は問題なくとも数時間経過した頃にレイテンシが高騰したり、エラーが発生したりすることがありました。そのため、Kuduを用いたオンライン処理システムを構築する際は、各種のチューニングに加えて長期間の性能負荷試験を実施することを推奨します。
おわりに
Kuduはデータのリアルタイムな格納と大量データの参照(分析)が得意なデータストアであり、常時稼働が必要なオンライン処理システムに活用されています。今回の性能検証では、メモリ割当量とパーティション割当方法のチューニングを行うことで、8時間にわたって毎秒70万レコードの格納とその集約処理が可能であることを確認できました。なお、Kuduは使用するディスクにSSDを推奨していますが、今回の検証では全ディスクにHDDを使用しました。そのため、SSDを使用すればさらなる性能向上が見込めると考えられます。
本連載は今回で最後となります。本連載ではKuduのアーキテクチャと、大量の電力消費量データを用いた性能検証の結果を紹介してきました。本連載がKuduを用いたシステムを構築する際の参考になれば幸いです。





