Apache Kuduのシステム構成と内部アーキテクチャ
2019年4月17日 6:30
はじめに
Kuduは高いスケーラビリティを持つ分散型のデータストアであり、Hadoopエコシステムに適合するように設計されたOSSです。第1回ではHadoop向けのデータストアであるKudu・HBase・HDFSの比較と、Kuduに適したユースケースを紹介しました。
Kuduは複数台のマシンでクラスタを構成することで、大容量・高性能・高可用性のシステムを実現します。今回はKuduシステム構成とデータモデル、可用性、主要な機能、およびKuduが大量のデータをどのように処理しているのかを紹介します。
Kuduのシステム構成
Kuduは分散データストアであり、複数台のマシンでクラスタを構成することで、高性能・大容量・高可用性のシステムを構築できます。図1にKuduのシステム構成を示します。
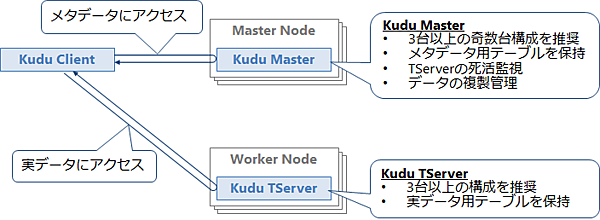
Kuduのクラスタはマスタノードに配置するKudu Master(以下、Master)と、ワーカノードに配置するKudu TabletServer(以下、TServer)で構成します。Masterはメタデータ(テーブルの構成情報など)の管理やTServerの死活監視、およびデータの複製管理を行います。ワーカノードのTServerはテーブルの実データを管理します。KuduのテーブルにアクセスするClientはMasterからテーブルの構成情報を取得して、それを元に目的のデータを持っているTServerにアクセスします。
Kuduはノード障害による動作停止やデータロストを避けるため、Master/TServerともに最低でも3台以上の構成が推奨されています。KuduはMaster間およびTServer間でデータを複製するため、一部のノードに障害が発生してもデータが失われる可能性は低く、そのまま稼働し続けることができます。
可用性を確保するためには、マスタノードは3台や5台などの奇数台構成にする必要があります。ワーカノードも3台以上の構成が推奨されていますが、こちらは奇数台である必要はありません。ワーカノードは台数を増やせば増やすほど容量と性能がスケールアウトします。
Kuduのクライアントインタフェース
Kuduを使用するためのクライアントインタフェースを表1に示します。
表1:Kuduのクライアントインタフェース
| インタフェース | 説明 |
|---|---|
| NoSQL API | 以下の言語用のKudu接続用のライブラリが用意されている。
|
| クエリエンジン/並列分散処理フレームワーク | Hadoopで使用される下記のクエリエンジンやフレームワークからKuduに接続するためのライブラリが用意されている。
|
| JDBC/ODBC | Impalaを経由してKuduにJDBC/ODBC接続が可能。 これにより、さまざまなBIツールからアクセス可能となる。 |
Kudu単体では、C++、Java、PythonのNoSQL API経由によるデータの追加、更新、削除、および参照が可能です。そのほか、クエリエンジンまたは並列分散処理フレームワークからKuduに接続するためのライブラリも用意されています。クエリエンジンであるImpalaを使用することで、SQLによるデータアクセスが可能となるほか、BIツールなどからJDBCやODBC経由でKuduのデータにアクセスできるようになります。また、SparkやMapReduceといった並列分散処理フレームワークを使用することで、複雑なデータ集計や変換処理を行うこともできます。
Kuduの論理データモデル:テーブル
Kuduは表形式のテーブルでデータを扱い、テーブルの各列は必ず型を持ちます。テーブルは1つ以上の列で構成される主キーを持ち、各行は主キーでソートされた状態で保持されます。Kuduのテーブルの例を図2に示します。
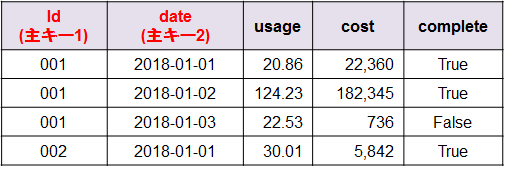
テーブルに対する基本的な操作を表2に示します。
表2:テーブルに対する基本的な操作
| # | 操作 | 説明 |
|---|---|---|
| 1. | Insert | 1レコードを新規追加する。全ての主キー列を指定する必要あり。 |
| 2. | Update | 既存の1レコードを更新する。全ての主キー列を指定する必要あり。 |
| 3. | Delete | 既存の1レコードを削除する。全ての主キー列を指定する必要あり。 |
| 4. | Upsert | InsertとUpdateの組み合わせを実行する。全ての主キー列を指定する必要あり。 |
| 5. | Scan | レコードを主キーの範囲指定で参照する。 |
レコードの書き込み操作(Insert/Update/Delete/Upsert)は必ず主キーを指定する必要があります。書き込み処理は、行単位のACIDトランザクションのみ対応しており、複数行にまたがる処理には対応していません。ですから、複数のレコードにまたがる処理のコミットやロールバックはできません。
レコードの読み出し操作はScanのみです。レコードは主キーでソートされた状態で格納されているため、主キーの範囲を指定してスキャンすることで、効率的に読み出すことができます。また、Kuduのレコードはタイムスタンプを持ち、更新・削除前のレコードも保持しています。KuduはMVCC(Multi-Version Concurrency Control)を採用しており、スキャン開始時点のスナップショットだけでなく、過去の特定時刻のスナップショットも参照できます。
Kuduの物理データモデル:タブレット
テーブルのデータは、「タブレット」と呼ばれる単位で物理的に分割して、各ノードに分散配置します。タブレットを各ノードに分散して配置することで、1つのテーブルを複数のノードで分散処理することができます。テーブルの分割方法はパーティションにより定義します。パーティションによる分割は、主キーによるハッシュまたはレンジ、およびその両方の組み合わせで行います。図3にハッシュパーティションとレンジパーティションの組み合わせによる分割の例を示します。
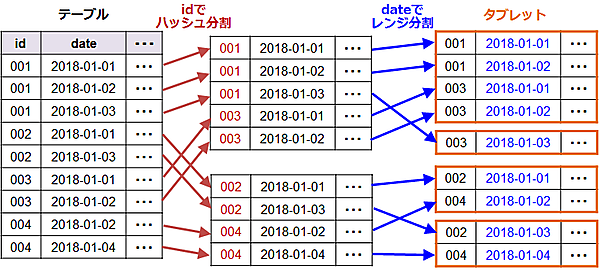
この例では、まずテーブルのid列の値でハッシュ分割をして、テーブルを2つに分割しています。次にdate列の値で、2日単位にレンジ分割を行い、4個のタブレットに分割しています。レンジ分割ではパーティション単位でデータを削除することも可能です。例えば過去のデータを定期的にまとめて消したい場合、そのレンジ(に含まれるタブレット)ごと消せばよいため高速に削除できます。
各タブレットのデータは、列ごとに値をまとめて保存する列指向ファイルで管理します。列指向ファイルは効率的なエンコーディングと圧縮が可能であり、大量データの読み出し時に必要なデータI/Oの量を大幅に削減できます。
データの複製と可用性
テーブルのデータは物理的にタブレットに分割され、各タブレットはさらにノード間で複製されます。これにより、一部のノードに障害が発生してもデータを失うことなく稼働し続けることができます。タブレットの複製は「レプリカ」と呼ばれ、1つがリーダーとして機能し、残りのレプリカはフォロワーとなります。書き込み要求はリーダーだけが処理し、読み取り要求はリーダーとフォロワーの両方が処理することで、書き込みと読み出しを複数のノードで分散処理できます。
タブレットの複製数(リーダーとフォロワーを合わせたレプリカの数)は、テーブル単位で設定することができ、デフォルト設定では3個のレプリカを作成します。もし、ノード障害によってあるタブレットのレプリカが失われた場合、そのレプリカは別のノードに再構築され、指定されたレプリカ数を可能な限り維持しようとします。
タブレットの複製は、一度ディスク上に書き込んだデータを複製する(物理レプリケーション)のではなく、タブレットに対する書き込み操作を複製して、各TServerで同じレコードを書き込む(論理レプリケーション)ことで行います。タブレットに対する操作の複製にはRaftコンセンサスアルゴリズムを使用し、過半数のレプリカで合意した操作のみを各レプリカで実行します(詳細は後述)。Raftコンセンサスアルゴリズムを使用することで、複製中のノード障害によるデータ不整合の発生を抑えることができます。
この仕組みにより、N個のレプリカを持つタブレットは、最大 (N-1)/2個のレプリカに障害が起きても書き込みを受け入れ続けることができます。例えば、3レプリカのタブレットは同時に1ノードの障害に耐えられ、5レプリカのタブレットは同時に2ノードの障害まで耐えることができます。
なお、TServerが持つテーブルのデータと同様に、Masterが持つメタデータ(を保持するシステムテーブル)もタブレットとして管理します。そのため、Master間およびTServer間でそれぞれタブレットの複製が行われます。ただし、Masterが持つシステムテーブルはパーティションによる分割は行われず、1タブレットで構成されます。
Masterが持つメタデータのテーブルは1タブレットで構成されるため、レプリカ数以上のMasterノードがあっても再構築が発生しない限り使用されません。そのためMasterのノード台数はレプリカ数に合わせることを推奨します。
TServerは複数のテーブルを持ち、各テーブルは複数のタブレットで構成されるため、レプリカ数以上のTServerノードがあっても有効活用できます。TServerはデータ容量やアクセス負荷を分散するため、ノード台数をレプリカ数より多くすることを推奨します。
書き込み操作の流れ
図4にレコードの書き込み操作(Insert/Update/Delete)の流れを示します。
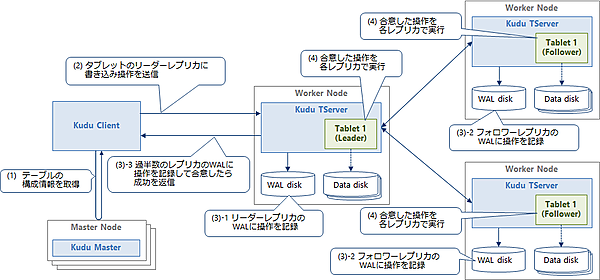
図4の各手順の詳細を以下に示します。
(1)テーブルの構成情報を取得
ClientがMasterにアクセスしてテーブルの構成情報を取得し、書き込み先のタブレットがどのTServerにあるのかを確認します。この情報はClientにキャッシュされ、次回以降はこの情報を使用します。
(2)タブレットのリーダーレプリカに書き込み操作を送信
Clientがテーブルの構成情報を元に、レコード書き込み先のリーダータブレットを特定し、そのタブレットを持つTServerに書き込み操作を送信します。
(3)書き込み操作をTServer間で複製して合意
リーダータブレットは、Raftコンセンサスアルゴリズムを使用して書き込み操作をフォロワータブレットに複製し、同じ操作を実行することをTServer間で合意します。まずリーダータブレットは、書き込み操作を自身のWAL(Write Ahead Log)に書き込みディスクに永続化します。そして各フォロワータブレットに操作を送信してWALに書き込みディスクに永続化します。Raftコンセンサスアルゴリズムにより、タブレット間で操作を合意(レプリカ数3の場合は過半数の2レプリカで合意できれば成功)した時点で、Clientに対して操作の成功を返します。
(4)合意した操作を各タブレットで実行
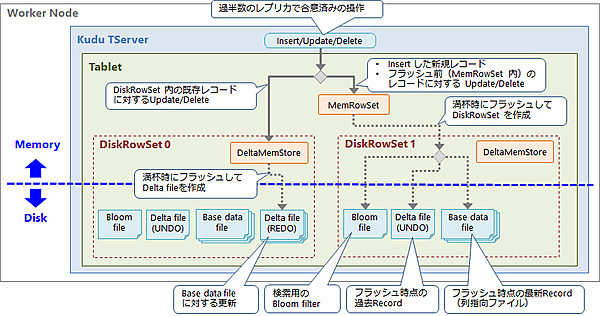
レプリカ間で合意した操作を、各タブレットへ実際に適用します。各タブレットにおける操作適用の流れを図5に示します。Insertの場合、メモリ上のMemRowSetに新規のレコードを追加します。UpdateとDeleteの場合、MemRowSet内の既存レコードに対する更新ならばMemRowSetに更新後のレコードを追加し、DiskRowSet内の既存レコードに対する更新ならばDeltaMemStoreに更新後のレコードを追加します。
MemRowSet内のレコードは主キーでソートされた状態で保持され、一定サイズに達すると新しいDiskRowSetとしてディスクにフラッシュします。このとき最新のレコード(主キーが同一なレコードのうちタイムスタンプが最新のもの)はBase data fileという列指向ファイルに書き込み、それ以外の過去のレコードはUndo用のDelta fileに書き込みます。また、同時に検索用のインデクスとブルームフィルタ※も別のファイルに書き込みます。各DiskRowSet内のDeltaMemStoreは、一定サイズに達したらRedo用のDelta fileにフラッシュします。
※ブルームフィルタは、特定の要素(レコード)が特定の集合(DiskRowSet)の中に含まれているか否かを判定する。ただし、一定の割合で間違った結果を返してしまう。具体的には、特定の主キーを持つレコードが特定のDiskRowSetに含まれていると判定したのに、実際は含まれていなかった(偽陽性)ということがある(含まれていないと判定したのに、実際は含まれていた〔=偽陰性〕ということはない)。ブルームフィルタは確実に判定できない代わりに、インデクスと比較して少ない容量で保持できる。
読み出し操作の流れ
図6にレコードの読み出し操作(Scan)の流れを示します。
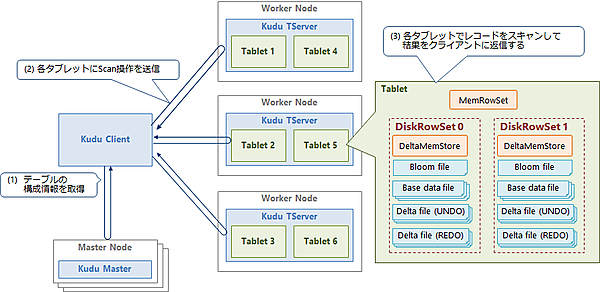
図6の各手順の詳細を以下に示します。
(1)ClientがMasterからテーブルの構成情報を取得
ClientがMasterにアクセスしてテーブルの構成情報を取得します。この情報はClientにキャッシュされ、次回以降はこの情報を使用します。
(2)タブレットに読み出し操作を送信
Clientがテーブルの構成情報を元に、目的のレコードを持つタブレットを特定し、そのタブレットを持つTServerにScan操作を送信します。なお、Scanするタブレットはリーダーとフォロワーのどちらでもかまいません。
(3)各タブレットでレコードを検索して結果をClientに返送する
各タブレットを並列に検索処理して、目的のレコードを読み出します。検索処理では、各DiskRowSetのブルームフィルタを使用して、目的のレコードを含むDiskRowSetを探します。そしてDiskRowSet内のBase data fileをスキャンして、目的のレコードを抽出します。この抽出したレコードに、DiskRowSet内のDelta fileとDeltaMemStoreから抽出したレコード、およびタブレットのMemRowSetから抽出したレコードをマージし、Clientに返送します。なお、KuduではUndo用Delta fileに保存された過去のレコードを使用することで、任意の時点のスナップショットに対する読み出しが可能です。
コンパクション
レコードの書き込みを続けていくと、タブレット内のDiskRowSet数とRedo用Delta file数が増加し続けていきます。レコードの読み出し時に各DiskRowSetのBase data fileとDelta fileを参照する必要があるため、DiskRowSet数やDelta file数が増加するとオーバーヘッドが増加します。また、Base data fileは列指向ファイルなので高速に読み出しできますが、Delta fileはそうではありません。
そのため、Kuduは定期的にDiskRowSet 内のDelta fileとBase data file、およびDiskRowSet同士をマージする「コンパクション」を行います。Kuduには表3に示す3種類のコンパクションがあります。
表3:コンパクション
| # | 種別 | 説明 |
|---|---|---|
| 1. | マイナーデルタコンパクション | DiskRowSet 内のDelta file同士をマージする |
| 2. | メジャーデルタコンパクション | DiskRowSet 内のBase data fileをRedo用Delta fileで更新(再作成)して、最新レコード以外はUndo用Delta fileに移行する |
| 3. | RowSetコンパクション | Key Range内で重複するDiskRowSet同士をマージする |
Kuduクラスタの構築
ソフトウェア構成
Kuduはあくまでストレージエンジンであり、SQLでアクセスを行うためにはSQLエンジンが別途必要です。またKuduへのデータ移行やバックアップには複数のHadoopコンポーネントを組み合わせる必要があります。このようにKuduは使用するコンポーネントが多いため、環境構築と運用管理に手間がかかります。
そのため、Cloudera社のHadoopディストリビューションであるCDH(Cloudera’s Distribution including Apache Hadoop)と、その運用管理ソフトウェアであるCloudera Managerの使用を推奨します。Cloudera Managerを使用することで、手間のかかるシステム構築やパラメータチューニングをほぼ自動的に行えるほか、クラスタの運用管理や性能監視をWebブラウザ上から簡単に行うことができます。
Cloudera ManagerではインストールするHadoopコンポーネントをサービスと呼びます。Kuduクラスタ構築時にインストールすべきサービスを表4に示します。
表4:Kuduクラスタ構築時にインストールすべきサービス
| # | サービス | 説明 |
|---|---|---|
| 1. | Kudu | 分散データストアを構成するストレージエンジン |
| 2. | Impala | KuduにSQLでアクセスするためのSQLエンジン |
| 3. | Hive | Impalaで作成したテーブルのメタデータを保存するメタストア |
| 4. | HDFS | Kuduへのデータ移行時やバックアップ時に、データの保管に使用する分散ファイルシステム |
| 5. | Sqoop | RDBなど他のデータストアからHDFSにデータを移行するETLツール |
| 6. | YARN | SqoopのETL処理やHDFSのバックアップ処理で使用するリソース管理ミドルウェア |
ハードウェア構成
マスタノード(Master)は管理用タブレットを1個だけ保持するため、高い性能は要求されません。しかしHA構成を行うためには最低でも3台必要です。ワーカノード(TServer)は大量のタブレットを保持するため、高い性能が求められます。特にディスクI/Oがボトルネックとなりやすいため、SSDを複数台搭載することを推奨します(WAL用1台+データ用に複数台)。HA構成のためには、タブレットのレプリカ数(3個)以上のノード台数が必要です。ただし、3台構成だと失われたタブレットが別ノードに再構築されないため、4台以上の構成を推奨します。
またKuduはノード間でデータを複製するため、ノード間を10G回線で接続したり、ボンディング(複数回線を束ねて使用)を行うことを推奨します。
なお、各ノードにはKudu以外のサービスもインストールされるため、それらの使用するリソースについても考慮する必要があります。推奨ハードウェアスペックの詳細はClouderaの公式ドキュメント「Hardware Requirements | 6.x | Cloudera Documentation」を参照してください。
Kuduの運用管理
モニタリング
KuduはさまざまなメトリックをREST APIによりJSON形式で公開しています。また、Cloudera Managerを使用することで、これらのメトリックをチャート表示で確認できます。
バックアップ・ディザスタリカバリ
Kuduにはクラスタ間でデータをバックアップする機能はありません。ディザスタリカバリ用にデータセンタ間でバックアップを行いたい場合は、Kuduのデータを一旦HDFSにParquetファイルとして書き出してから、Cloudera ManagerのBRD(Backup and Disaster Recovery)機能を使用して別のデータセンタにあるHDFSクラスタにバックアップすることを推奨します。
データ移行
KuduにはHBaseのようにデータファイルを直接バルクロードする方法はありません。RDBなど他のデータストアからKuduにデータを移行する場合は、まずデータをSqoopなどのETLツールでHDFSにCSVファイルとして格納し、それをImpalaでKuduにInsertします。
おわりに
Kuduは複数台のマシンでクラスタを構成することで、大容量・高性能・高可用性のシステムを実現します。今回はKuduのシステム構成とデータ処理の仕組みについて紹介しました。
次回からは、Kuduの性能検証の結果を紹介します。この検証では、Kuduで大量の電力消費量データを処理するシステムを構築し、2種類のワークロードにおける性能を測定しました。
次回は性能検証のシナリオと、大量の電力消費量データをKuduへ移行するワークロードの検証結果、およびそこから得られたチューニングのポイントを紹介します。
- この記事のキーワード
この記事をシェアしてください
関連記事
バックナンバー
この記事の筆者
筆者の人気記事
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
