Apache Kuduによるデータ移行処理のチューニング
2019年5月9日 6:30
はじめに
Kuduは多数のマシンでクラスタを構成することで、大容量・高性能・高可用性のシステムを実現できます。連載第2回「Apache Kuduのシステム構成と内部アーキテクチャ」ではKuduのシステム構成とデータ処理の仕組みについて紹介しました。
第3回と第4回ではKuduの性能検証の結果を紹介します。この検証では、Kuduで大量の電力消費量データを処理するシステムを構築し、2種類のワークロードにおける性能を測定しました。今回はまず性能検証のシナリオと、大量の電力消費量データをKuduへ移行するワークロードの検証結果、およびそこから得られたチューニングのポイントを紹介します。
性能検証の概要
検証のシナリオ
近年、住宅やビルの分電盤に設置したセンサから得られる電流の波形情報を分析することで、電力を消費する設備(空調、エレベータ、照明など)や家電機器(PC、電子レンジ、洗濯機など)ごとの動作状態や電力消費量を推定する「ディスアグリゲーション」という技術が実用化されています。これにより、電力消費量の見える化や生活行動の分析といったサービスが生まれています。
現在、住宅や施設単位で電力消費量を計測するスマートメータが普及していますが、これは30分単位の電力使用量を取得するのが一般的です。しかし機器単位の消費電力を測定したい場合、電子レンジなど一部の家電機器は動作時間が短いことが多く、正確な動作状態を把握するにはより短い間隔で電流データをサンプリングする必要があります。そのためディスアグリゲーション技術では1秒間隔のデータを使用することが多く、データ量は膨大になります。Kuduはリアルタイムなデータ格納と大量データの参照に優れているため、このようなデータの格納に適していると考えられます。
今回の検証で想定するシステムの全体像を図1に示します。今回の検証では、ビルの設備や機器の電力消費量を蓄積し、その集約結果をダッシュボードやレポートで可視化するシステムを想定します。このうち電力消費量データの蓄積と、ダッシュボードやレポーティングに使用する集約結果の格納にKuduを使用します。
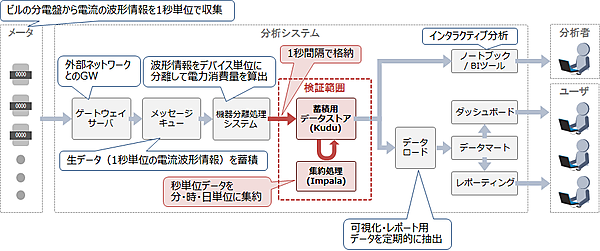
図1に示した処理の流れを説明します。まずビルの分電盤に設置したセンサが電流の波形情報を1秒間隔で収集して、本システムのゲートウェイサーバに転送します。このデータを一旦メッセージキューでキューイングした後、電流の波形情報を分析して機器単位の波形情報に分離し、それを電力消費量レコードに変換します。そして変換した全機器の電力消費量レコードを、1秒間隔でまとめてKuduに格納します。Kuduに格納した秒単位の電力消費量レコードは、定期的に集約して分単位、時単位、日単位のレコードに変換します。
Kuduに蓄積したレコードはデータ分析や可視化に使用します。データ分析者はKuduに蓄積したデータに対してインタラクティブ分析を行い、最適な分析手順や可視化方法を検討します。そして、分析結果を多くのユーザが活用できるように、ダッシュボードやレポーティングツールを使用して、分析結果の可視化やレポート作成の自動化を行います。
ダッシュボードやレポーティングツールはKuduに直接アクセスしてデータを参照することも可能ですが、これらのツールは多くの人から使用され、チャート表示やレポート作成のたびにデータアクセスが発生するため、Kuduの格納処理や集約処理に影響が出る恐れがあります。そこで、参照用のデータマートを別に用意して、チャート表示やレポート作成に必要なレコードを定期的にデータマートへコピーします。
今回はKuduの検証が目的であるため、図1に示した全体像のうち、Kuduに対するデータ格納処理と、格納したデータの集約処理を検証範囲としました。この検証では、事前に作成しておいた1秒間隔の電力消費量レコードを使用して、Kuduの性能測定を実施しました。
検証項目
新しくシステムを構築する場合、既存のデータを新規のシステムに移行することがよくあります。そのため、本連載では以下に示す2種類のワークロードについて性能検証を行いました。
(1)既存データをKuduへ移行するバッチ処理
(2)新規データをKuduにリアルタイム格納しつつ参照を行うオンライン処理
本記事の後半では、(1)のワークロードの検証結果を紹介します。(2)のワークロードの検証結果は次回の記事にて紹介します。
検証環境
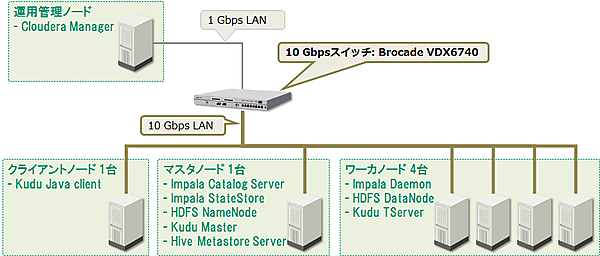
検証に使用したハードウェア構成とソフトウェアの配置を図2に示します。今回の検証ではCloudera Managerを用いてKuduのクラスタを構築しました。使用したバージョンはCDH 5.12(Kudu 1.4)です。クラスタにはKuduのほかにImpala、Hive、HDFS、YARNをインストールしました。
検証環境のハードウェアスペックを表1に示します。
表1:検証ハードウェア構成
| # | ノード | 種別 | 台数 | CPU | メモリ | ディスク割当 |
|---|---|---|---|---|---|---|
| 1. | 運用管理ノード(Cloudera Manager用) | 仮想 | 1台 | 2コア | 16GB | 320GB×1台 |
| 2. | マスタノード | 物理 | 1台 | 40コア | 384GB | OS用:2台でRAID1構成 Kudu Master WAL用:1台 Kudu Master Data用:2台 HDFS NameNode用:2台 |
| 3. | ワーカノード | 物理 | 4台 | 40コア | 384GB | OS用:2台でRAID1構成 Kudu TServer WAL用:1台 Kudu TServer Data用:7台 HDFS DataNode用:8台(Kuduと共用) |
| 4. | クライアントノード | 物理 | 1台 | 40コア | 384GB | OS用:2台でRAID1構成 |
マスタノード、ワーカノード、クライアントノードは同一スペックのマシン(HA8000/TS20AN)を使用しました。今回は性能検証が目的のため、マスタノードの冗長化は実施していません。KuduはWAL用のディスクにSSDの仕様を推奨していますが、今回は用意できなかったため、すべてのディスクにHDDを使用しました。
Kuduはノード間でデータを複製するため、ノード間を10G回線で接続したり、ボンディング(複数回線を束ねて使用)を行うことを推奨しています。そのため今回の検証では、マスタノード、ワーカノード、クライアントノード間は10Gbps回線で接続しました。
検証データ
テーブル設計
検証で使用するKuduのテーブル一覧を表2に示します。
表2:kuduのテーブル一覧
| # | テーブル名 | 説明 |
|---|---|---|
| 1. | load_per_sec | 機器の1秒単位の電力消費量レコードを格納 |
| 2. | minutely_load | load_per_secテーブルのレコードを1分単位で合計したものを格納 |
| 3. | hourly_load | minutely_loadテーブルのレコードを1時間単位で合計したものを格納 |
| 4. | daily_load | hourly_loadテーブルのレコードを1日単位で合計したものを格納 |
表2の各テーブルはすべて同じテーブル定義を持ちます。この共通のテーブル定義を表3に示します。各テーブル共に、1レコードのサイズは32bytesとなります。
表3:テーブル定義
| # | Column名 | キー | データ型 | サイズ | 説明 |
|---|---|---|---|---|---|
| 1. | building_id | ○ | int32 | 4 bytes | 建物を示すID |
| 2. | floor_id | ○ | int32 | 4 bytes | 建物内の階層を示すID |
| 3. | device_id | ○ | int32 | 4 bytes | 電力を消費する設備や機器を示すID |
| 4. | time_stamp | ○ | unixtime_micros | 8 bytes | 電力測定時の時刻 |
| 5. | device_load | int64 | 8 bytes | 電力消費量(Active power[watts]) | |
| 6. | device_type | int32 | 4 bytes | 設備や機器の種別 |
各テーブルの1レコードは、機器単位の特定時刻の電力消費量を示します。building_id、floor_id、device_idの3つのキーで機器を特定し、これにtime_stampを加えることで、ある機器の特定時刻の電力消費量を特定できます。
想定データ量とパーティション設定
今回はビル10棟、1ビルあたり50フロア、1フロアあたり200機器存在すると想定し、合計機器数は10棟×50フロア×200機器=10万機器と仮定しました。このときload_per_secテーブルには1日あたり84.6億レコード(表3の論理サイズで252.1GB)が格納されます。
ただし、Kuduはデータを列指向ファイルに圧縮して保持するため、実際のデータサイズはもっと小さくなります。事前に10万機器×6時間(21,600秒)分のレコードをKuduに格納して圧縮率を測定した結果、Kudu上のサイズは80.7GBとなり、表3の論理サイズの約32%まで圧縮されることが分かりました。
Kuduはテーブルをパーティションで区切ることでタブレットに分割します。タブレットサイズの推奨値はありませんが、テーブルを適切にタブレットへと分割することで、読み書きを分散処理できます。今回は1タブレットあたりの圧縮後データ量が最大5GB程度となるようにパーティションを定義しました。表4に各テーブルのパーティション定義と、圧縮後の最大タブレットサイズの推定値(論理サイズの32%)を示します。
表4:Kuduテーブルのパーティション定義とタブレットサイズ
| # | テーブル名 | レコード数(1日あたり) | データサイズ(1日あたり) | パーティション設定 | 最大タブレットサイズ(圧縮後の推定値) |
|---|---|---|---|---|---|
| 1. | load_per_sec | 84.6億件 | 定義上:252.1 GB 圧縮後:80.7 GB | ハッシュ:16個 レンジ:1日単位 | 5.1 GB |
| 2. | minutely_load | 1.44億件 | 定義上:4.2 GB 圧縮後:1.3GB | ハッシュ:8個 レンジ:1月単位 | 5.1 GB |
| 3. | hourly_load | 240万件 | 定義上:73MB 圧縮後:23MB | ハッシュ:4個 レンジ:1年単位 | 2.1 GB |
| 4. | daily_load | 10万件 | 定義上:3MB 圧縮後:1MB | ハッシュ:4個 レンジ:なし | 278 MB/年 |
Kuduにload_per_secテーブルを作成するImpalaクエリを以下に示します。このクエリをImpalaから実行することで、KuduのテーブルとそれにマッピングされたImpalaテーブルが作成されます。
CREATE TABLE load_per_sec
(
building_id INT,
floor_id INT,
device_id INT,
time_stamp TIMESTAMP,
device_load BIGINT,
device_type INT,
PRIMARY KEY (building_id, floor_id, device_id, time_stamp)
)
PARTITION BY
HASH (building_id, floor_id) PARTITIONS 16,
RANGE(time_stamp)
(
PARTITION cast('2018-01-01T00:00:00' as timestamp) <= VALUES < cast('2018-01-02T00:00:00' as timestamp),
PARTITION cast('2018-01-02T00:00:00' as timestamp) <= VALUES < cast('2018-01-03T00:00:00' as timestamp),
PARTITION cast('2018-01-03T00:00:00' as timestamp) <= VALUES < cast('2018-01-04T00:00:00' as timestamp),
PARTITION cast('2018-01-04T00:00:00' as timestamp) <= VALUES < cast('2018-01-05T00:00:00' as timestamp),
PARTITION cast('2018-01-05T00:00:00' as timestamp) <= VALUES < cast('2018-01-06T00:00:00' as timestamp)
)
STORED AS KUDU
TBLPROPERTIES('kudu.num_tablet_replicas'='3');
テーブル作成時は1TServerあたり最大60タブレット(複製を含む)、つまり4TServerで最大240タブレットの制限があります。本検証ではタブレット複製数をデフォルト設定である3個に設定したため、テーブル作成時の複製を除いたタブレット数は最大80個となります。そのため、上記のクエリではハッシュパーティション16個×レンジパーティション5個のみを定義しています。
それ以上のタブレット数が必要な場合は、「ALTER TABLE」クエリで後からレンジパーティションを追加していく必要があります。なお、1TServerの最大タブレット数(複製を含む)は2,000個となります。レンジパーティション範囲外のデータはInsertが拒否されるため、タブレット数の上限には注意が必要です。
データ移行処理の検証
新しくシステムを構築する場合、既存のデータを新規のシステムに移行するケースがよくあります。そのため、まずは既存データをKuduへ移行するバッチ処理の性能を検証しました。
RDBなどに保存された既存データをKuduに移行する場合、まずはデータをCSVファイルなどに書き出して一旦HDFSに格納します。その後、Impalaを使ってHDFS上のCSVファイルをKuduに格納します。今回のデータ移行処理の検証範囲を図3に示します。
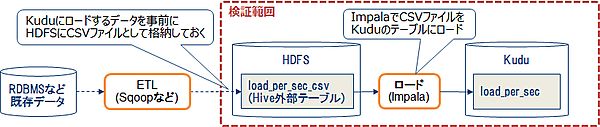
今回の検証では、HDFSに格納したCSVファイルに対してHiveの外部テーブル(load_per_sec_csv)を定義して、そのテーブルのデータをImpalaでKuduのテーブル(load_per_sec)にInsertする際のスループットを測定しました。CSVファイルを格納したHiveテーブルのレコードを、KuduのテーブルにInsertするImpalaクエリを以下に示します。
INSERT INTO load_per_sec SELECT * FROM load_per_sec_csv;
格納データサイズと格納スループット
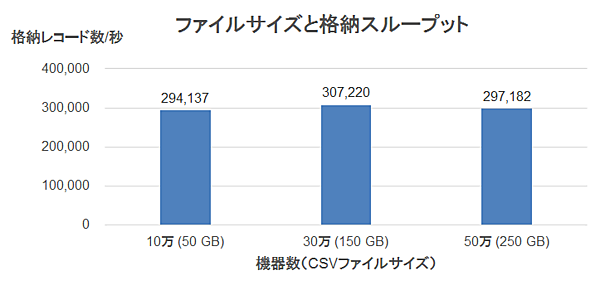
今回の検証では、データをImpalaでKuduにInsertする時間を測定し、そこから格納スループットを計算しました。この測定で使用した、3種類のサイズのCSVファイルを表5に示します。なお、入力に使用したCSVファイルはテキスト形式であるため、ファイルサイズは表4の論理サイズやKudu格納後の列指向ファイルのサイズとは異なります。
表5:入力データサイズ
| # | 機器数 | レコード数(6h分) | CSVファイルサイズ |
|---|---|---|---|
| 1. | 10万 | 21.6億 | 50.2GB |
| 2. | 30万 | 64.8億 | 150.5GB |
| 3. | 50万 | 108億 | 250.8GB |
測定結果を図4に示します。格納に使用するデータ量に関わらず、格納スループットは秒間約30万レコードでほぼ一定となりました。
TServerメモリ割当量と格納スループット
KuduのCloudera公式ドキュメント「Loading Data into Kudu Tables - Using Impala to Query Kudu Tables | 5.12.x | Cloudera Documentation」には以下の記載があります。
If a bulk operation is in danger of exceeding capacity limits due to timeouts or high memory usage, split it into a series of smaller operations.
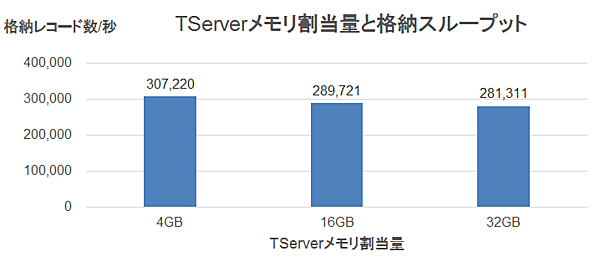
そのため、念のためにTServerのメモリ割当量(memory_limit_hard_bytesで設定)を増やした場合のスループットも測定しました。
検証時に設定したTServerのメモリ割当量を表6に示します。
表6:TServerのメモリ割当量
| # | TServerのメモリ割当量(memory_limit_hard_bytes) | 説明 |
|---|---|---|
| 1. | 4GB | Cloudera Managerのデフォルト設定値 |
| 2. | 16GB | Clouderaの最小推奨値 |
| 3. | 32GB | Clouderaの最小推奨値の2倍 |
格納データには機器数30万(150GB)のCSVファイルを使用しました。この測定結果を図5に示します。メモリ割当量を増やすと格納スループットがわずかに下がりましたが、ほぼ秒間30万レコードで一定であるといえます。
検証結果の考察
今回の検証では、格納するデータ量やTServerのメモリ割当量に関わらず、格納スループットは秒間約30万レコードでほぼ一定でした。図6にメモリ割当量4GBで30万機器×6時間分のレコードを格納した際の、格納スループットの推移を示します。この格納スループットは3つに複製したタブレットの分を含むため、実際の格納スループットは1/3となります。青い実線が平均値、点線が最小値および最大値を示しています。
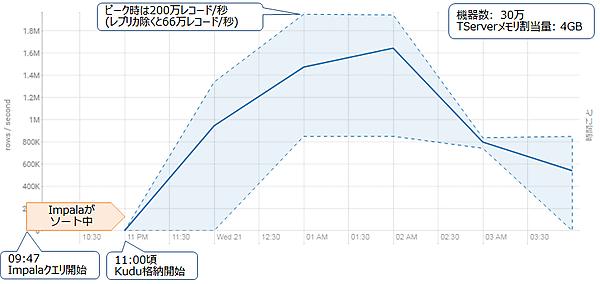
Impalaクエリの実行期間は09:47 PMから03:40 AMまでの約6時間です。クエリは09:47 PMに開始されましたが、Kuduへの格納が始まるのは11:00 PMからです。ImpalaでKuduにデータをInsertする際、Impalaはメモリ上でデータをソートしてからKuduに格納します(参考:「[IMPALA-3742] INSERTs into Kudu tables should partition and sort - ASF JIRA」)。そのため、最初の73分間はImpala上でソートを行っていて、Kuduへの格納が発生していないと考えられます。
Kuduへの格納が始まると、スループットは徐々に向上していき、ピーク時には秒間200万レコード(複製分を除くと66万レコード)のスループットで格納していました。格納スループットの平均は秒間30万レコードですが、実際には一定ではないことがわかります。
データ移行処理のチューニングポイント
データ移行処理では、基本的にKuduおよびImpalaのチューニングは必要ありません。今回の検証においては、Kuduのメモリ割り当て量を増やしても効果はありませんでした。Impalaによるデータ格納では、Impalaがレコードをメモリ上でソートしてからKuduに格納します。そのためKuduよりもImpalaの方がメモリを多く使用すると考えられます。
Impalaはインメモリ処理による高速化を目的としたクエリエンジンであり、Cloudera ManagerはImpalaのメモリ割当量を多めに設定してくれます。そのため基本的には、Impalaのメモリ割当量を変更する必要はありません。
おわりに
今回は性能検証のシナリオと、大量の電力消費量データをKuduへ移行するワークロードの検証結果、およびそこから得られたチューニングのポイントを紹介しました。
本連載は次回が最終回となります。次回はKuduの典型的なユースケースである、データをリアルタイムに格納しつつ、分析のために大量参照するようなオンライン処理の検証結果を紹介します。また、この検証から得られたKuduの高負荷時の挙動と、チューニングのポイントを紹介します。
- この記事のキーワード
この記事をシェアしてください
バックナンバー
この記事の筆者
筆者の人気記事
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
