ハッシングの実際
ハッシングの実際
ハッシング+リンクトリストの基本構造を見てきましたが、この構造はさまざまなところで使われています。また、ハッシュの考え方は衝突は覚悟の上で、あるものをいくつかのグループに一意的に分類するのに役立ちます。そのような実例のいくつかを紹介しましょう。
1つ目がバッファキャッシュです。リスト構造やツリー構造、そしてハッシュは基本ソフトウエアの中でたくさん使われています。その代表的なものがOSのファイル管理に使われるバッファキャッシュ(buffer cache)です。
現代のOSの重要な機能のひとつにファイルシステムがあります。ファイルの入出力、特にハードディスクとの間でデータ転送(読み書き)を管理する際、データ転送の効率を上げるためにバッファキャッシュ、またはディスクキャッシュ(Disk Cache)と呼ばれるメカニズムを使います。
ディスク上のファイルの読み書きは、最も下のレベルではブロック単位でのデータの転送を行います。ディスクI/Oでは物理的にはブロック単位の操作が基本です。そして、ディスク上の特定のブロックをファイルから読み込む際、いったんメモり上にその写し(copy)が作られます。一度メモリ上にコピーが作られれば、その後の入出力の際には、直接ディスクとのデータ転送は行わずに、このコピーに対して読み書きを行います。プログラムから見ればディスクへの書き出しを行う場合でも、実際にはこのコピーに対して書き込みが行われるだけで、ファイルを閉じるなど本当に必要なときにのみ実際のデータの書き出しが行われます。
さて、このようなメモリ上のコピーがバッファキャッシュなのですが、これらに素早くアクセスするためにハッシュ+リンクトリストの構造が使われます。ディスク上のブロックの番号をハッシュ値に変換して、その値が同じものを1つのリンクトリストとして管理します(図2-1)。
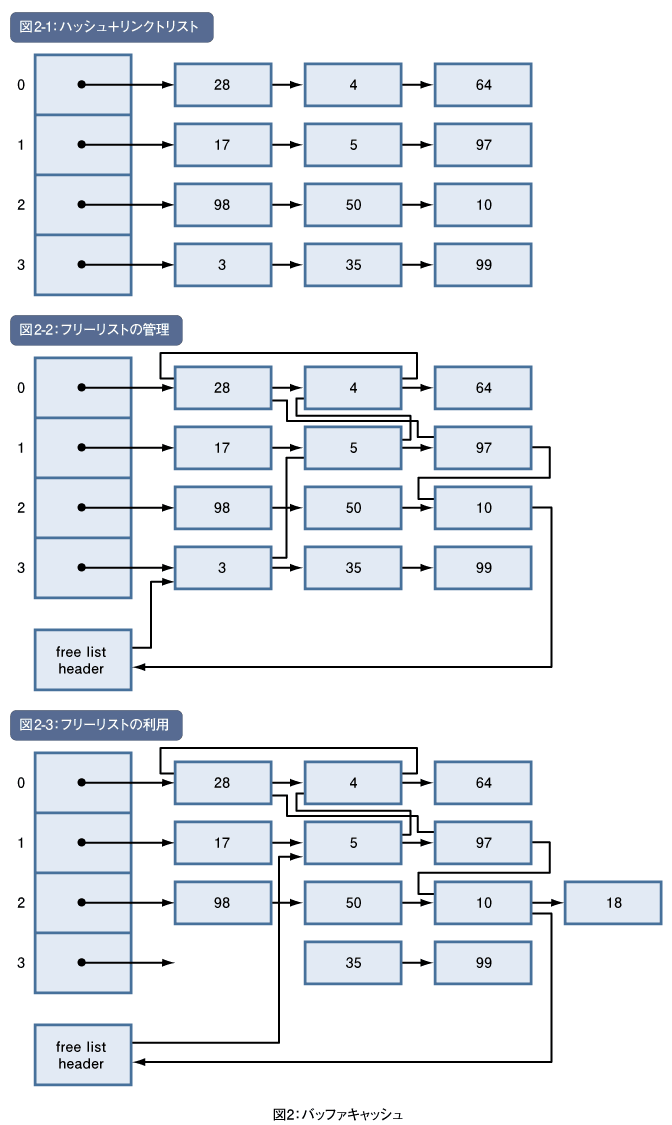
バッファキャッシュの構造
ここでは話を簡単にするために、グループを4つに分けています。つまり、メモリブロックは、ディスク上のブロック番号を4で割った余りの数値(0~3)をインデックスとするリストにつながることになります。
さて、このメモリ上のキャッシュ領域も無限にはありませんから、これらを使い切った場合のことを考えなくてはなりません。キャッシュがいっぱいになった場合にはその一部を「解放」して再利用します。このために、未使用のバッファキャッシュのためのメモリブロックをフリーリスト(free list)として管理します(図2-2)。
1つのディスクブロックに対応するメモリブロックは、同じ仲間-つまり同じハッシュ値をもったブロック-のリンクトリストとしてつながっていると同時に、フリーリストにもつながることになります。
今、新たにブロック番号18をディスクから読み込む必要が生じたとします。対応するメモリブロック18はキャッシュ上にないので、どこかを空ける必要があります。このとき、フリーリストの先頭にあるブロック3番を空けます。
こうして空けられたブロックが18番用になり、インデックス2の場所につながります(図2-3)。
フリーリストの管理方法については詳述しませんが、LRU(Lease Recently Used)と呼ばれるアルゴリズムが使われるのが一般的です。つまり、「最近一番使われていなかったもの」を優先して解放します。今の例ではそれが3番のブロックでした。
1つのメモリブロックが2つのリストの要素になっているというのはややこしいのですが、ハッシュ値によって分散されたリンクトリストであると同時に、その一部はフリーリストとして管理されるのです。
- この記事のキーワード
関連記事
バックナンバー
この記事の筆者

筆者の人気記事
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
