システム障害の検知と原因特定を、予測・因果・生成の3つのAIで自動化─Dynatraceが説くAIOpsの最先端
提供:Dynatrace合同会社
2024年4月9日 6:00
IT運用の現場では、システム監視の作業に時間をとられ、本来やるべきだった業務に時間を使えない事態が発生している。こうした中、障害を自動で検知したり、原因を自動で特定したりする手法として、AIOpsに注目が集まっている。オブザーバビリティ(可観測性)およびAIOps分野のリーダーと市場から評価されるDynatraceは、予測AI、因果AI、生成AIの3つのAIを組み合わせ、これまで自動化が難しかったIT運用の多くを自動化するAIOpsを実現するプラットフォームだ。2023年12月11日〜12日に開催されたクラウド技術のイベント「CloudNative Days Tokyo 2023」に登壇した同社のAIOpsエバンジェリスト角田勝義氏は、AIOpsで変わるIT運用の姿を解説した。
IT運用をAIで自動化するAIOps
「システム監視ツールの画面を、1日に何時間も見ている」─。IT運用の現場では、システム監視の作業に時間をとられ、本来やるべきだった業務に時間を使えない事態がよく発生している。こうした中、システム監視データを基に、AI(人工知能)を使って障害を検知し、原因を特定し、復旧作業につなげる手法として、AIOpsに注目が集まっている。
AIOpsは、米Gartnerが提唱した言葉。ビッグデータと機械学習を組み合わせ、異常を検知したり、イベントの相関関係や因果関係を見出したりして、ITの運用にAIを活用することを指している。
システムの障害には、エンドユーザーがサービスを利用できないケースや、ページの読み込みが遅いケースなど、各種のパターンがある。一般的には、システム監視ツールのアラートメールやエンドユーザーからのクレームなどを契機に障害に気付く。障害を認識した後は、人手で問題を切り分け、原因を特定し、復旧する(図1)。

図1:一般的なシステム障害の検知から復旧までの流れ
「異常の検出から復旧作業において、人が実施している部分、時間がかかっている部分はどこなのかを思い浮かべて欲しい」とDynatrace のAIOpsエバンジェリスト角田 勝義氏(写真)は指摘する。

写真:Dynatrace合同会社 AIOps エバンジェリスト 角田 勝義氏
「Dynatraceは、障害を検知し、AIが自動で原因を特定して復旧してくれます。これまで人間がやっていた作業の多くを代わりにやってくれる、夢のような世界といえます(図2)」(角田氏)。
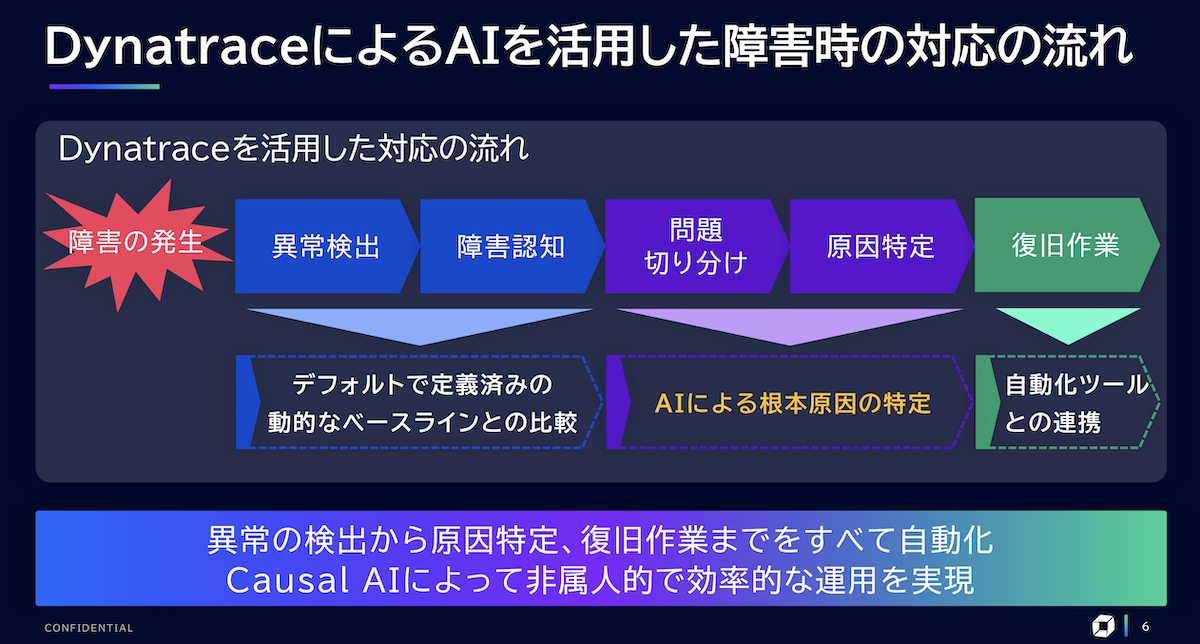
図2:Dynatraceによるシステム障害の検知から復旧までの流れ
Dynatraceはインフラからアプリケーション、バックエンドからフロントエンドまで、フルスタックでオブザーバビリティ(可観測性)を提供するものだ。システム全体の稼働状況と性能を把握できるほか、AIによって障害原因の分析まで行える。
「Dynatraceは、運用に関わる作業の多くを自動化できます。例えば、監視項目やアラートのための閾値は、過去のナレッジに基づいて最初から設定されており、1つひとつマニュアルで設定する必要がありません。異常の検知に関しても過去のデータに基づいて動的にベースラインを割り出し、ここから逸脱した場合に異常だと判断します」(角田氏)。
エージェントを導入するだけで
オブザーバビリティを始められる
角田氏が挙げるDynatraceの特徴は5つある(図3)。

図3:Dynatraceの特徴
①単一エージェントによるデータの自動収集:
まず、導入が容易。一般に、システムを監視する場合、エージェントをサーバーに導入し、監視の閾値を設定し、アラートを定義する。一方、Dynatraceは、異常検出のためのアラート設定はデフォルトで定義済み。よって、エージェントを導入するだけで済む。オブザーバビリティに必要なテレメトリデータを取得する設定も自動で完了する。
②依存関係の自動把握:
例えば、コンテナ運用基盤であるKubernetesのワーカーノードにエージェントを展開すると、ここから情報を集め、どのようなPodが動いていて、どのように連携しているかといった縦と横の関係をAIが把握する。「マイクロサービス環境の全体像を把握するのは人手では難しいですが、Dynatraceは人に代わってAIがリアルタイムな状況を把握します」(角田氏)。
③ペタバイト級のログデータを一元保管:
ログを取り込む際にも、インデックス化やスキーマ定義などの作業は必要ない。また、取り込んだログに対するクエリーも、応答時間が短い。
④AIによる根本原因の分析:
システムに障害が発生した際には、AIを使って根本原因を分析する。
⑤復旧作業のと自動化:
障害の原因を特定した後は、外部システムと連携し、復旧作業を実施する。
Causal AI(因果AI)が原因の特定に活躍
システム障害の問題の切り分けと原因の特定については、Dynatraceが備えるCausal AI(因果AI)が活躍する(図4)。「イベント情報や各種メトリック情報などの依存関係を基に、根本原因を見出すAIです」(角田氏)。根本原因が判明すれば、すぐに復旧作業に取り掛かることが可能になる。
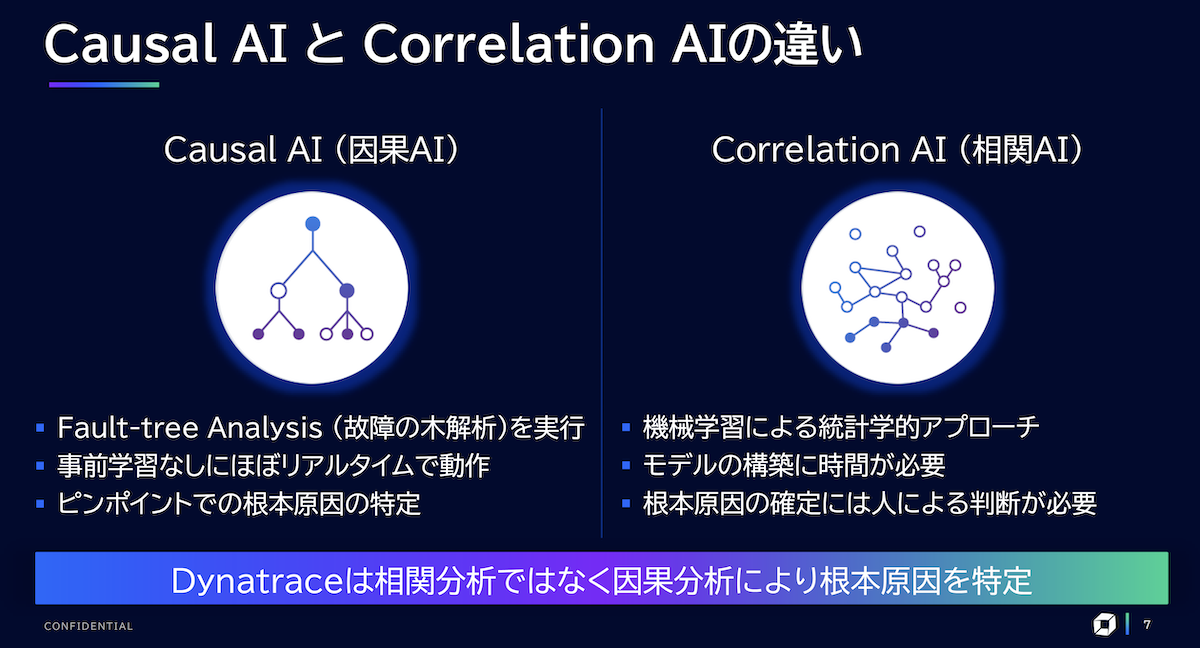
図4:Dynatraceが備えるCausal AI(因果AI)と一般的なCorrelation AI(相関AI)の違い
Causal AIは、機械工学などで使われるフォルトツリーアナリシス(故障の木解析)と呼ぶ手法を用いて、因果関係を洗い出し、どこに原因があるのかを特定する。事前学習なしにリアルタイムで動作することも特徴だ。角田氏によると、Causal AIは論文数も増えており、注目を集めている。
これに対して、一般的なCorrelation AI(相関AI)の場合、機械学習による統計学的アプローチをとっており、AIモデルの構築に時間がかかる。さらに、相関関係しか特定できないので、根本原因を確定させるには、人による判断が必要になる。
相関関係が把握できても、因果関係は分からない。例として角田氏は、Kubernetes環境のサービス応答時間が遅くなり、CPUリソースがリミット設定の上限に達しているケースを示した。レプリカの数も上限に達しており、これ以上性能をスケールさせられない。この場合、応答時間の遅延とCPU使用率が高いこととの相関は分かるが、これだけでは対策は打ちにくい。
「KubernetesクラスタのCPUリソースの状況を見て、リミット設定の上限を増やすとか、レプリカの数を増やすとかの対策が思い浮かびます。しかし、新バージョンをテストするためのカナリアリリースに限って影響があったということが分かった場合、対策は変わってきます」(角田氏)。因果関係が特定できれば、カナリアリリースのデプロイメントを差し戻すといった対策がとれる。
生成AIを含めて3つのAIを組み合わせて活用
Dynatraceでは、Causal AI(因果AI)のほかに、Generative AI(生成AI)にも力を入れている。2023年7月には、これらにPredictive AI(予測AI)を加えた3つのAIを組み合わせたハイパーモーダル型のAIを発表している(図5)。
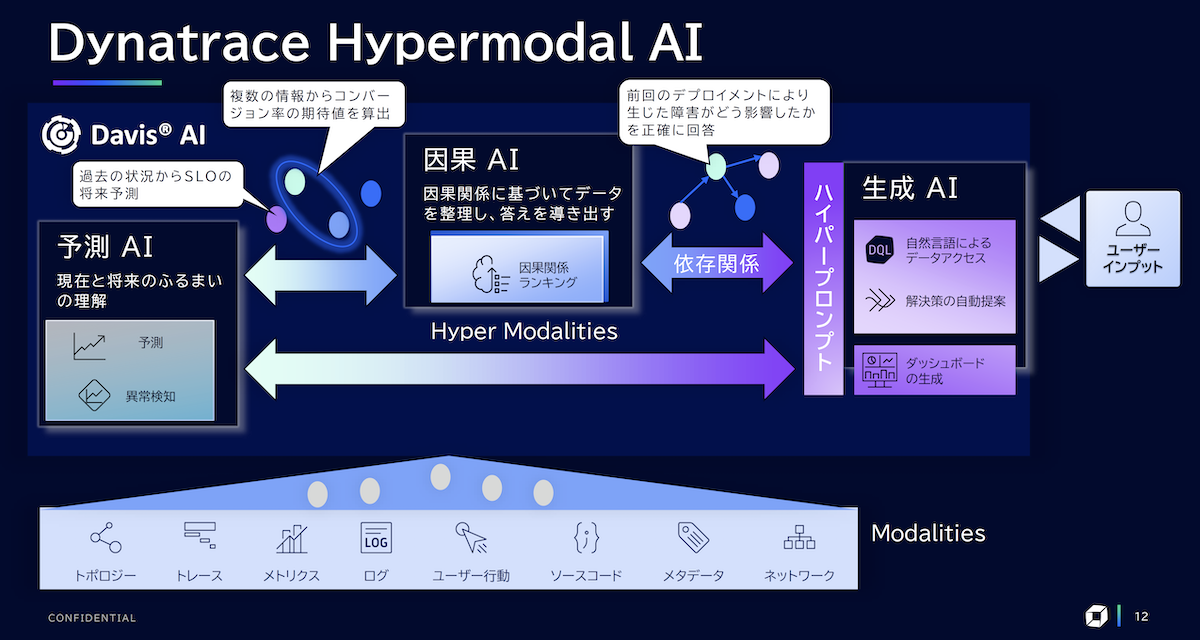
図5:予測AI/因果AI/生成AIの3つを組み合わせたハイパーモーダルAIを提供している
3つのAIのうち、予測AIは、機械学習や統計学的アプローチを使って、将来動向を予測したり、異常の発生を予測したりする。因果AIは、依存関係を基に根本原因を特定する。生成AIは、自然言語で問い合わせられるように採用した。
「何か障害があった際に、対話型のプロンプトから自然言語で問い合わせれば、障害がどう影響するのかをAIが計算して回答してくれます」(角田氏)。大規模言語モデル(LLM)が元々持っているデータセットだけでなく、リアルタイムに集めたシステム監視データやソースコード、ネットワーク情報、イベント情報などを基に回答を生成する。
例えば、「過去の状況からSLO(サービスレベル目標)を維持できるかどうかの予測を立てたり、バーンレート(SLOのエラーバジェットの消費速度)からエラーバジェットが尽きるまでの時間を予測できます」(角田氏)。
AIOpsは幅広いユースケースをカバー
角田氏は、DynatraceのAIOps機能によってIT運用を自動化するユースケースをいくつか紹介した。
1つは、コンテキスト情報から正確な答えを回答してもらう使い方だ。例えば、「昨日の障害で、どのくらいのユーザーに影響があったのかを知りたい」といったことをプロンプトから問い合わせる。一般的な生成AIの場合、役に立たない回答しか返ってこない。
一方、Dynatraceは、問い合わせを解決するためのクエリーを自動で生成して実行し、「901人」といった具体的な結果を返す(図6)。「最初からクエリーを書いても良いですが、問い合わせに自然言語を使うことで、クエリーの構文エラーを減らす効果があります」と角田氏は指摘する。他にも「応答時間が遅いサービスのトップ5を表示して欲しい」といった問い合わせが可能だ。
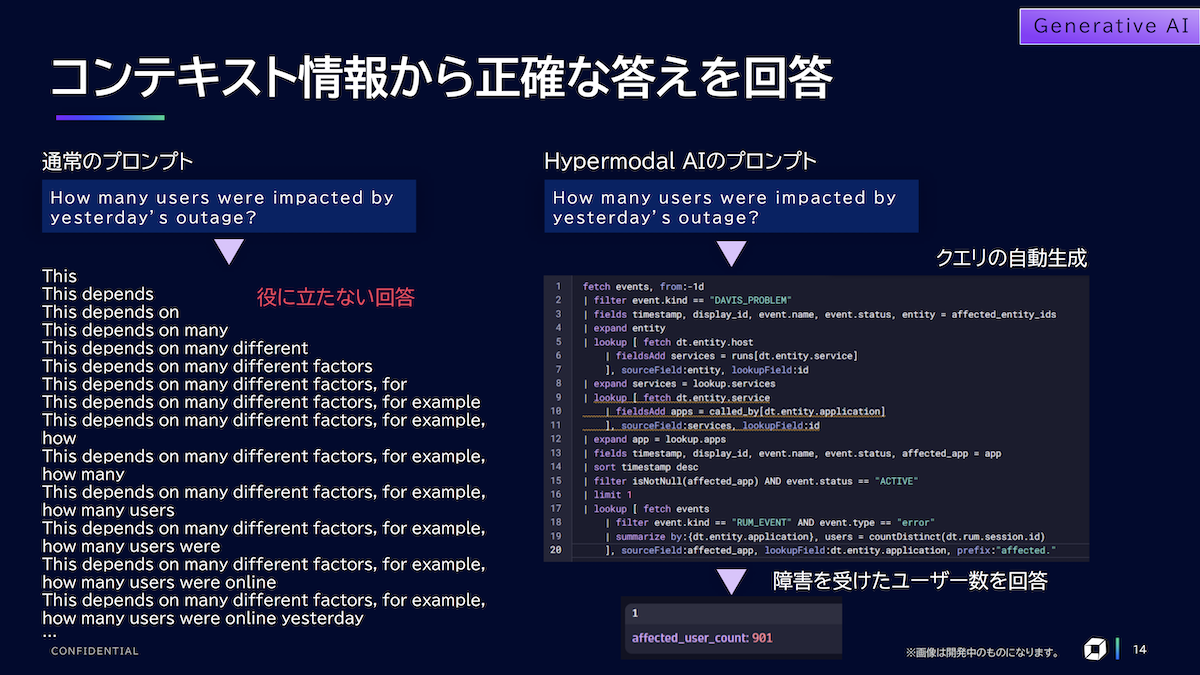
図6:自然言語による問い合わせをクエリーに変換して実行し、正確に回答する
今後の機能強化の計画では、Dynatraceに組み込んだCoPilotエンジンを使って、ダッシュボードの作成も可能になる。「こういう情報が載っているダッシュボードを作って欲しい」といった指示を出すだけで、所望のダッシュボードを自動で作ってくれるようになる予定だ。
AIOpsは、予測分析にも使える。「毎朝8時に、すべてのディスクの空き容量を予測する、といった使い方ができます。今後24時間以内に空き容量が枯渇しそうなことを検知し、Slackやメールで通知する、といった運用が可能になるでしょう」(角田氏)。
角田氏は、IT運用を自動化するAIOpsの仕組みとメリットを説いた。中でもDynatraceのハイパーモーダルAIは、因果AIと予測AI、生成AIの3つのAIがシームレスに連携する。3つのAIの連携により、どこで何が起きているのかすぐに把握し適切な回答を得ることができる。角田氏が「夢のような世界」と呼ぶAIOpsの理想像は、すでに実現しているという。
日本リージョン開設も決定
最後に角田氏はDynatraceの日本(東京)リージョン開設が決定したことも報告した。クラウドであっても、サーバーの所在地が近接している方が通信速度の観点では明らかに有利となる。また、データを日本国内に保存できること、国内のデータプライバシーおよびセキュリティに関する規制に対応できることなど、そのメリットは大きい。日本リージョンが存在する他ベンダーは限られており、より安定したセキュアなサービスの提供体制を整えている。

写真:Dynatraceの日本(東京)リージョン開設が決定
この記事をシェアしてください
バックナンバー
この記事の筆者
筆者の人気記事
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
