Nodeの水平スケール
Nodeの水平スケール
最後に、Nodeの水平スケール(Cluster Autoscaler、以下CA)について説明します。
Nodeの水平スケールの概要
Nodeの水平スケール(CA)は、Kubernetesクラスタ内のNode数を水平スケール(スケールアウト/イン)する仕組みです。スケール方法はPodのResource Requestsの値をベースにクラスタ内のリソースの過不足を判断し、Node数を増減させます。Nodeの水平スケールはIaaSに依存するため、特にクラウド・プロバイダに関しては仕様や利用方法に違いがあります。
CAは1つのDeployment(Pod)によって動作し、Kubernetes API Serverを通してクラスタのリソース使用状況を監視してNode数を操作します。 CAを実現するDeploymentはControl Planeに配置することを推奨していますが、Worker Nodeに配置しても問題ありません。
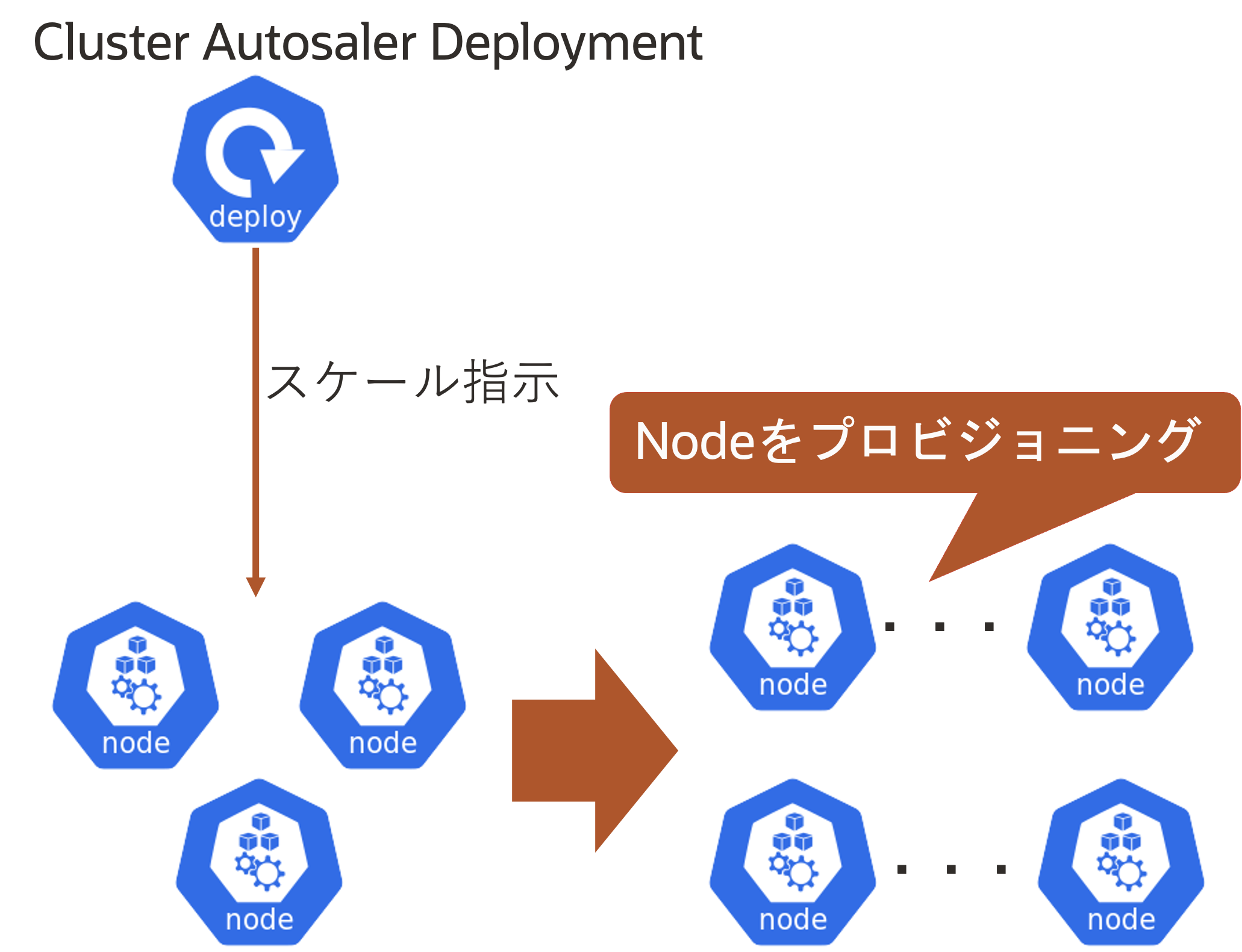
CA
ここからは、Oracleが提供するOracle Container Engine for Kubernetes(OKE)のCAの仕組みをベースに解説します。
CA DeploymentとDeployment(ワークロード)の定義
まずは、CA DeploymentのManifestから見ていきます。CA DeploymentのManifest例は以下のようになります。
apiVersion: apps/v1
kind: Deployment
metadata:
name: cluster-autoscaler
namespace: kube-system
labels:
app: cluster-autoscaler
spec:
replicas: 3
selector:
matchLabels:
app: cluster-autoscaler
template:
metadata:
labels:
app: cluster-autoscaler
annotations:
prometheus.io/scrape: 'true'
prometheus.io/port: '8085'
spec:
serviceAccountName: cluster-autoscaler
containers:
- image: iad.ocir.io/oracle/oci-cluster-autoscaler:1.29.0-10
name: cluster-autoscaler
resources:
limits:
cpu: 100m
memory: 300Mi
requests:
cpu: 100m
memory: 300Mi
command:
- ./cluster-autoscaler
- --v=4
- --stderrthreshold=info
- --cloud-provider=oci
- --max-node-provision-time=25m
- --nodes=1:5:{{ ocid1.nodepool.oc1.ap-tokyo-1.aaaaaaaajsesqrdewqdewqdewdaaaaaaae2xldew }}
- --nodes=1:5:{{ ocid1.nodepool.oc1.ap-tokyo-1.aaaaaaaajsesdewqdewqdwaaaaaaaaaaae2xdela }}
- --scale-down-delay-after-add=10m
- --scale-down-unneeded-time=10m
- --unremovable-node-recheck-timeout=5m
- --balance-similar-node-groups
- --balancing-ignore-label=displayName
- --balancing-ignore-label=hostname
- --balancing-ignore-label=internal_addr
- --balancing-ignore-label=oci.oraclecloud.com/fault-domain
imagePullPolicy: "Always"
env:
- name: OKE_USE_INSTANCE_PRINCIPAL
value: "true"
- name: OCI_SDK_APPEND_USER_AGENT
value: "oci-oke-cluster-autoscaler"ここで主に指定するパラメータは、OKEの論理的なNodeグループであるNodePoolのOCID(OCIリソースを一意に特定するID)です。ここで定義されたNodePoolがCAの対象とみなされます。スケール対象のNodePoolは複数指定できます。CA Deploymentの設定は利用するKubernetesサービスやベンダーによって異なります。
次に、Deployment(ワークロード)の定義を説明します。Deploymentの定義は、HPAやVPAと同様にResource Requestsの値を定義します。CA DeploymentはResource Requestsの値を元に既存の各Podのリソースの合計が既存Nodeのリソースを超える、もしくは下回った場合にスケールさせます。

Deployment(ワークロード)の定義
CAの仕組み
CA DeploymentはHPAやVPAと同様にmetrics-serverからメトリクスを取得します。そのメトリクス結果を元に、既存NodeでのCPUやメモリの過不足がある場合はリソース過不足分のNode数をスケールします。ただし、スケールインについては「Resource Requestsの合計がノードのリソース空き領域の50%を下回る状態」が10分を超えて継続し、かつ引越し先のノードに充分な空きがある場合に実施されます。他にも細かい条件が存在します。
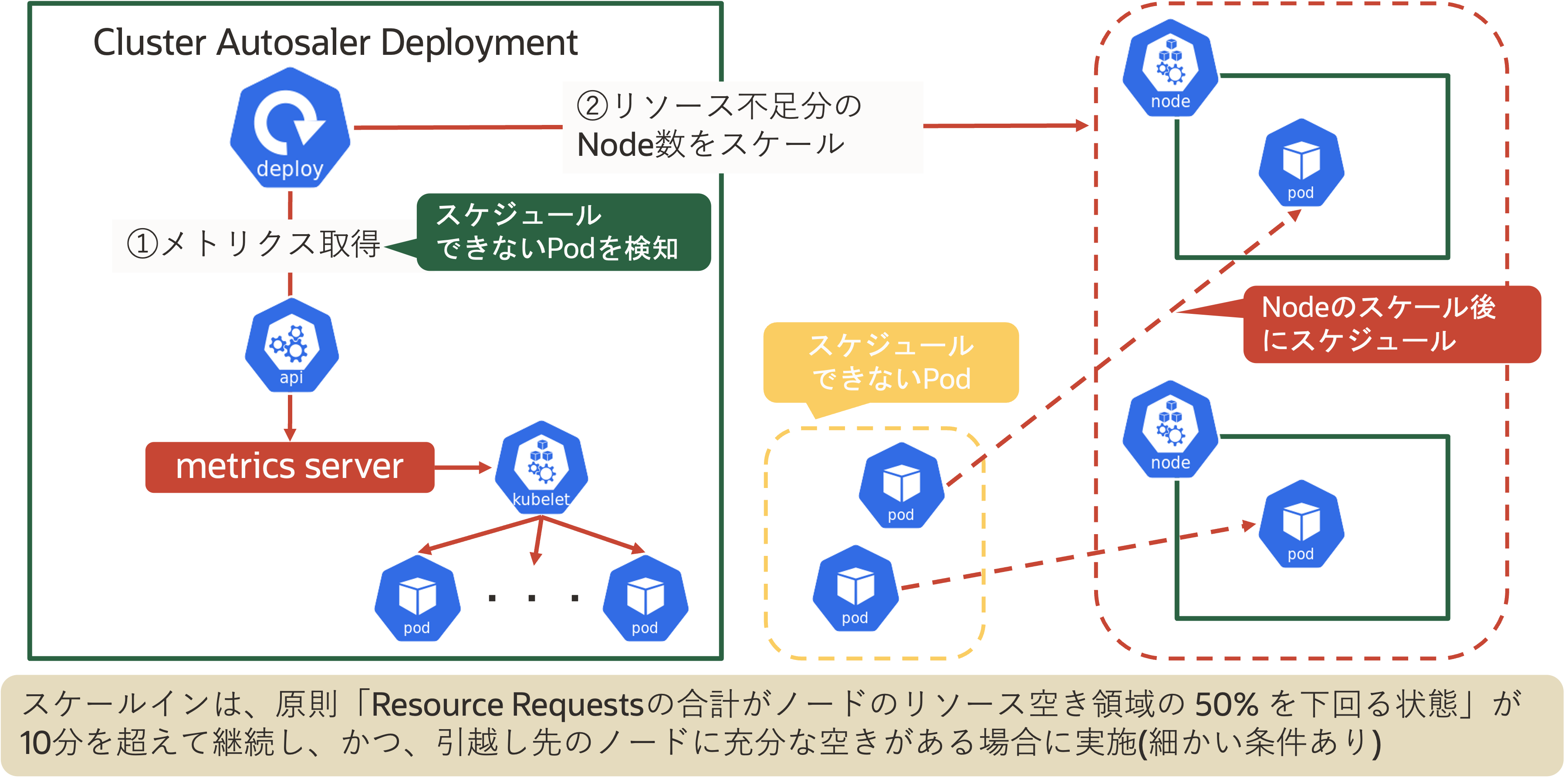
スケールインの仕組み
CA利用時の留意事項
CAを利用する際にはいくつか留意事項が存在します。特にスケールイン時はNodeが削除されるため、いくつかの考慮が必要です。例えば、Nodeがスケールイン(削除)される場合は、対象のNodeで動作していたPodに対して再スケジューリング(kubectl drain node→evict)が発生し、サービスにダウンタイムが発生する可能性があります。
これを防ぐためには、PodDisruptionBudget(PDB、後述)を設定することで、なるべくGraceful shutdownが実施されるように設定を実施することが重要です。
また、以下の場合(一部)は、Nodeが削除されないこともあります。
- kube-system namespaceで実行されているシステムコンポーネント関連のPod
- PodDisruptionBudget(PDB)により制限されているPod
- Controllerにより管理されていないPod(Deployment/ReplicaSet/Job/StatefulSetでないPod)
- NodeAffinity/NodeSelectorによりスケジュールされているPod
- .metadata.annotationsに
"cluster-autoscaler.kubernetes.io/safe-to-evict": "false"が設定されているPod
このような留意事項を考慮した上で、CAを利用しましょう。
PodDisruptionBudgetとPriorityClass
ここで、CAを利用する際に有効な2つのリソース、PodDisruptionBudgetとPriorityClassについて紹介します。
・PodDisruptionBudget(PDB)
PodDisruptionBudget(PDB)は、自発的な中断(Cluster Autoscalerによるスケールイン時やkubectl drain実行時)が発生した場合に同時にダウン(再スケジューリング)するレプリカを制限する仕組みです。このリソースを定義することで最低限稼働しておくべきPod数を確保でき、サービスのダウンタイムを防止できます。
PodDisruptionBudget(PDB)では、主に以下の2つを定義します。
| 項目 | 内容 |
|---|---|
| 最低限稼働しておくべきレプリカ数 | minAvailable/maxUnavailableで定義 |
| Selector | 対象PodをSelectorで指定 |
PodDisruptionBudget(PDB)の例は以下の通りです。
apiVersion: policy/v1
kind: PodDisruptionBudget
metadata:
name: myapp
spec:
# 最大で無効状態な Pod は 1 に設定。これを超えてevictできない
maxUnavailable: 1
# 対象 Pod のセレクタ
selector:
matchLabels:
run: myapp・PriorityClass
PriorityClassは、スケジュール時にリソースを確保できない場合(通常であればPending状態)に優先的に起動できるようにする仕組みです。このリソースをCAで活用して意図的に「優先度低の待機用Pod」でノードを多めに起動しておくことで、Podのスケールアウト(HPA)時のNodeリソース不足を防止できます。
PriorityClassでは、主に以下の2つを定義します。
| 項目 | 内容 |
|---|---|
| 優先度 | 10億以下の整数。値が大きいほど優先度高 |
| グローバル適用要否 | priorityClassNameが付与されていないPodへの適用要否。trueの場合はクラスタに一つだけ適用可能 |
apiVersion: scheduling.k8s.io/v1
kind: PriorityClass
metadata:
name: high-priority
value: 1000000
globalDefault: false
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx
labels:
app: nginx
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- image: nginx
name: nginx
resources:
memory: "500Mi"
ports:
containerPort: 80
priorityClassName: high-priority #PriorityClassの適用CA利用時の留意事項(OKEの場合)
OKEについても、いくつかの留意事項が存在します。OKEではスケール対象外のNodePoolを最低1つは用意することが推奨され、スケール対象に設定したNodePoolの手動スケールは厳禁です。このように、マネージドKubernetesサービスでCAを利用する場合は、それぞれの条件(推奨構成や留意事項など)を確認することが重要です。
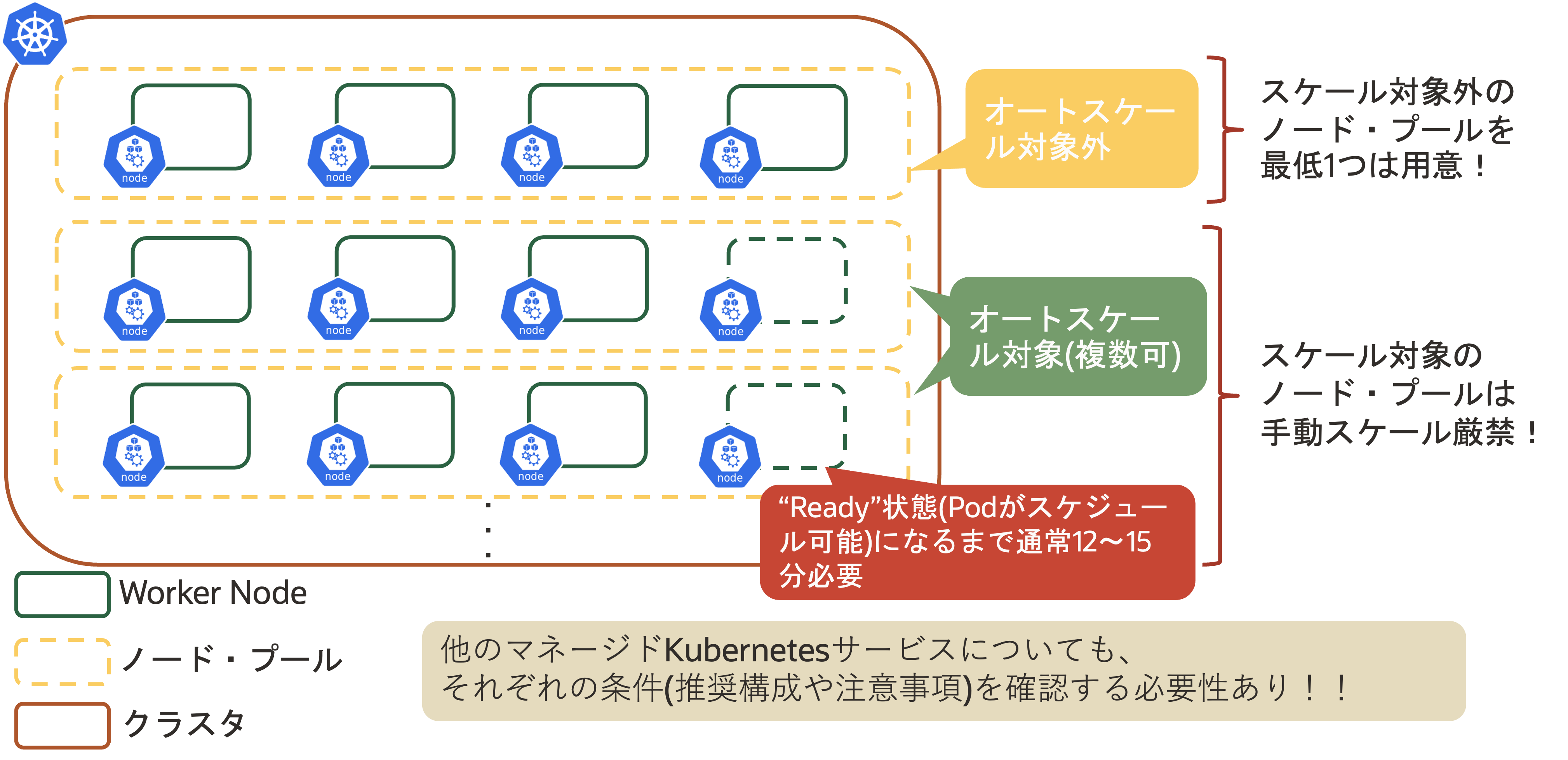
マネージドKubernetesサービスでCAを利用する場合は条件を確認
Kubernetesの各スケール手法まとめ
これまで見てきたスケール手法を以下に整理します。
| HPA | VPA | CA | |
|---|---|---|---|
| スケール対象 | Deployment(ReplicaSet) | Pod | Node(Worker Node) |
| スケール手法 | 水平スケール | 垂直スケール | 水平スケール |
| 追加コンポーネント | metrics server | metrics server Updater Admission Controller Recommender |
metrics server Cluster Autoscaler Deployment |
| スケールメトリクス | Podや任意のリソース | Resource Requests | Resource Requests |
| スケール時の即応性 | 高(スケールの振る舞いはカスタマイズ可能) | 低 | 低 |
| スケールイン時のダウンタイム | なし | あり(in-placeは未実装) | あり(PDB等より一部制御可能) |
Kubernetesでの各種スケールのユースケース
最後に、これまでご紹介してきた各種スケール手法を組み合わせた1つのユースケース例を紹介します。
- VPAを利用したResource Requestsの決定
- Resource Requestsの最適値を確認
- Resource Limitはアプリケーションの特性やNodeのリソースに応じて定義
- アプリケーションの特性やサービス指標に応じて、Podの水平スケール(HPA)範囲を決定
- 2.で定義したPodの水平スケールにおいて、Nodeのリソース不足に備えてCluster Autoscalerを定義
- 定常時のNode数を考慮しつつ、2.で定義したスケール範囲で不足すると想定されるリソース分のNode数を判断
- PodDisruptionBudget(PDB)やPriorityClassを利用しながら、Nodeのスケールインによる意図しないサービスダウンの防止、スケールアウト時のNodeプロビジョニングによるリードタイムの短縮を計画
おわりに
今回は、従来からあるスケールの種類とその特徴を踏まえた上で、Kubernetesにおける3種類のスケール(Podの水平/垂直スケール、Nodeの水平スケール)を見てきました。Kubernetesにおいて、オートスケールは最も重要な機能と言っても過言ではありません。
本記事がKubernetesのオートスケールを理解する手助けになれば幸いです。
- この記事のキーワード
バックナンバー
この記事の筆者

筆者の人気記事
Oracle Cloud Hangout Cafe Season5 #1「Kubernetes Operator 超入門」(2022年1月19日開催)
2023年3月17日 6:30
Oracle Cloud Hangout Cafe Season 4 #2「Kubernetesのネットワーク」(2021年5月12日開催)
2024年2月20日 6:30
Oracle Cloud Hangout Cafe Season6 #1「Service Mesh がっつり入門!」(2022年9月7日開催)
2023年6月22日 6:30
Oracle Cloud Hangout Cafe Season 4 #5「Kubernetesのオートスケーリング」(2021年8月4日開催)
2024年5月29日 6:30
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
