「K8sGPT」の未来と生成AIを用いたKubernetes運用の最前線
第9回の今回は、Kubernetesのトラブルシュートを生成AIで補助する「K8sGPT」について紹介します。
2024年11月14日 9:28
はじめに
3-shakeのSreake事業部に所属する戸澤(@tozastation)です。第9回目の今回は、Kubernetes のトラブルシュートを生成AIで補助する「K8sGPT」について紹介します。
K8sGPTは組み込みのアラート条件とセットになったプロンプトをもとにGoogle Gemini、Amazon Bedrock、OpenAIに問い合わせ、問題に対する解決策を提示してくれるツールです。SREの経験が Analyzerにコード化されており、不具合に対して関連の高い情報を抽出し生成AIに問い合わせるというのが特徴です。本ツールは、2023年にCNCFのSandbox Projectとなっています。
K8sGPTの紹介

K8sGPTではアラート条件を決めて解決方法を生成AIに問い合わせるAnalyzerが定義されており、Kubernetesのリソース毎に用意されています。また、この問い合わせを実行することを Analyze(分析、※以降分析)と呼びます。
まずはデモを見ながら、どのような処理が実行されるかを紹介します。「CLIでPod Analyzerを実行するデモ(下図)」はK8sGPT CLIからPodリソースに対する分析を実行している例です。おおまかなステップとして「分析対象のピックアップ」と「分析」の2つに分かれます。今回は何かしらの状況でPodがうまく起動できないシーンを想定します。
- 分析対象のピックアップ
Pod Analyzerでは、コンテナのステータスがWaitingかつ、その理由がエラーに該当するPodを分析対象としてピックアップします。合わせて、エラーの調査に関連性のある「Podの最新イベント」も取得します。 - 分析
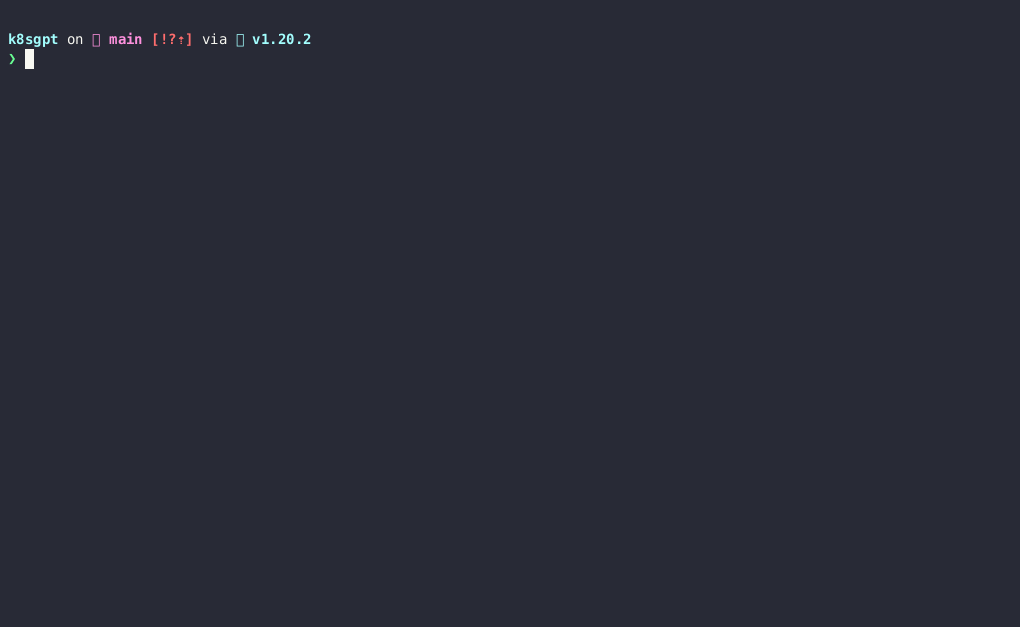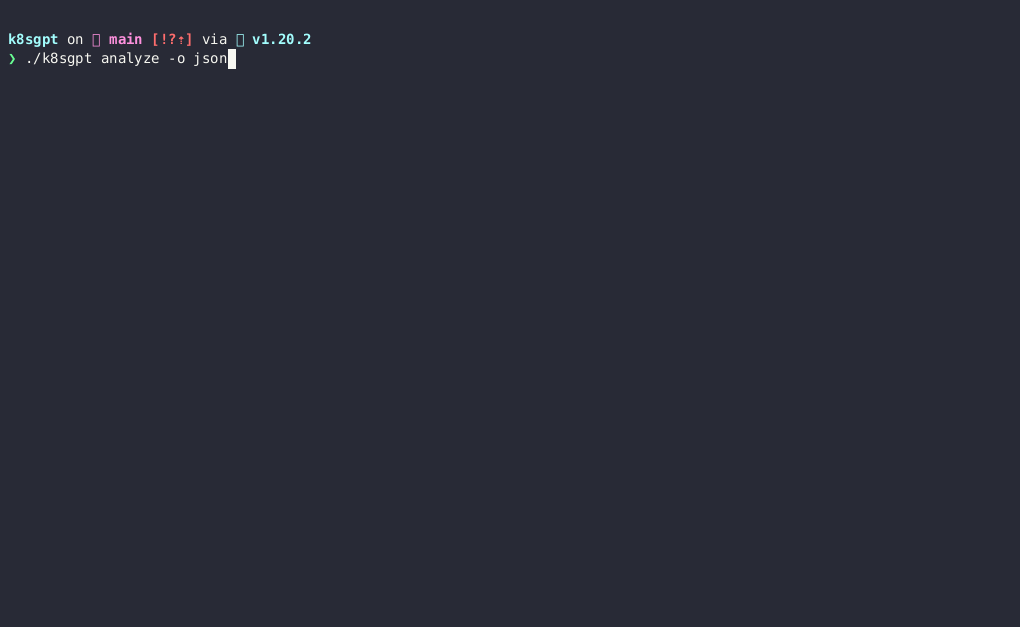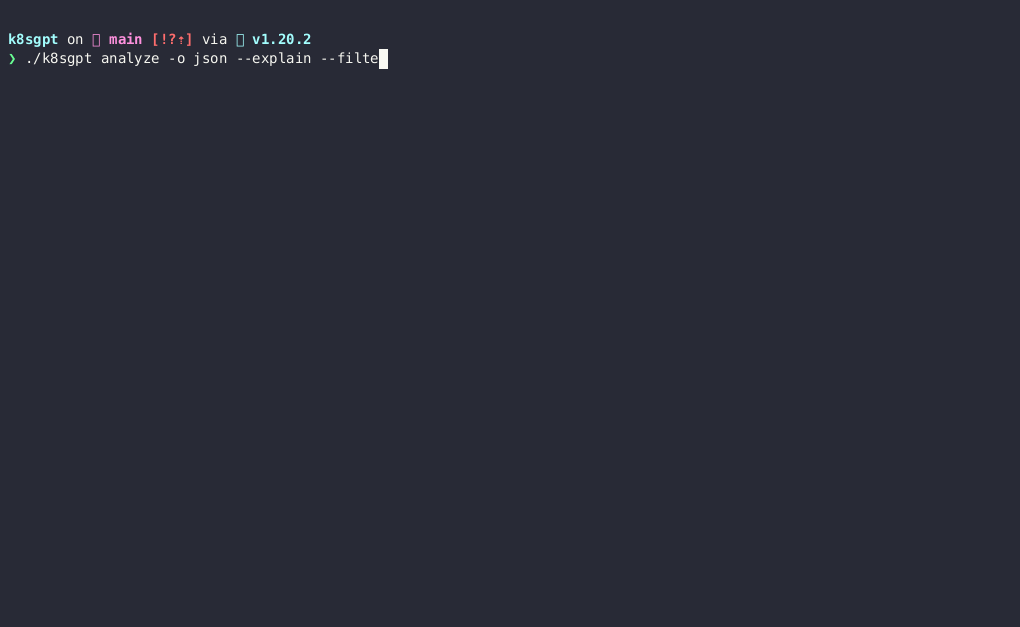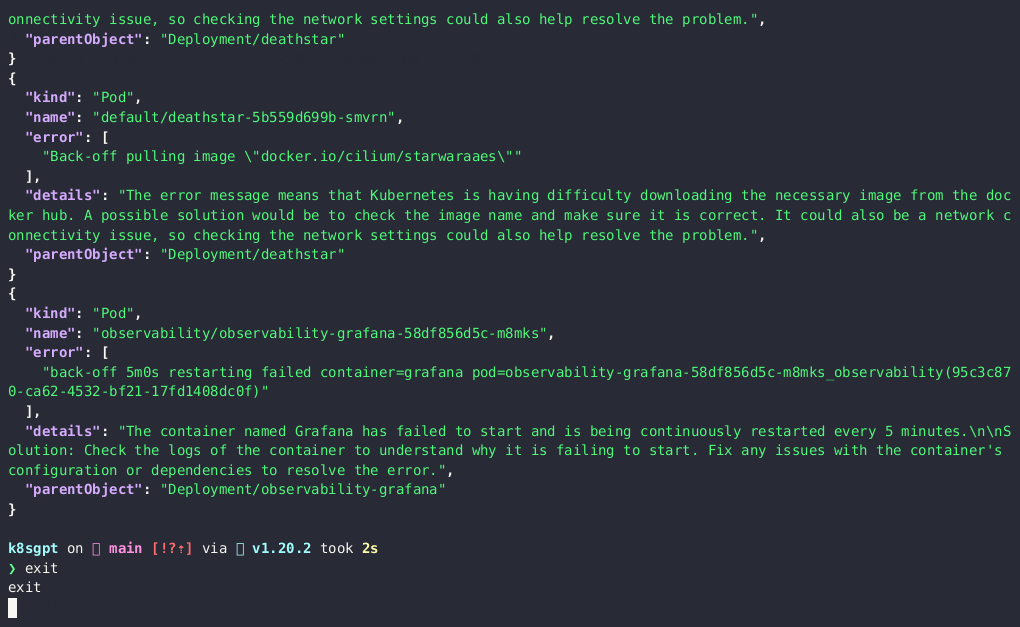
1.で取得した情報をもとに、下記の「K8sGPTが送信するプロンプト」を組み立てます。プロンプトで指定した出力内容は、エラー内容をもとにステップバイステップで最も簡単な解決策を提供することです。「出力結果(表1)」を見ると、解決策があればそれを、もう少し情報が必要なときは、次に調査すべき箇所を提示してくれます。
ここでは1往復のやり取りでしたが、最初の結果出力を元にさらに生成AIと議論・相談したい場合には、現在プレビューでinteractive debugging mode が提供されています。
このように、K8sGPTに運用の知見を溜め、なりたてのKubernetes利用者に対してデバッグのサポートをしてくれるツールになります。
CLIでPod Analyzerを実行するデモ【出典】k8sgpt/images/demo4.gif
Simplify the following Kubernetes error message delimited by triple dashes written in --- %s --- language; --- %s ---. Provide the most possible solution in a step by step style in no more than 280 characters. Write the output in the following format: Error: {Explain error here} Solution: {Step by step solution here}表1:出力結果
| 理由 | エラー文 | 解決策 |
|---|---|---|
| CrashLoopBackOff | "back-off 5m0s restarting failed container=grafana pod=observability-grafana-58df856d5c-m8mks_observability (95c3c870- ca62-4532-bf21-17fd1408dc0f) “ | The container named Grafana has failed to start and is being continuously restarted every 5 minutes.Solution: Check the logs of the container to understand why it is failing to start. Fix any issues with the container's configuration or dependencies to resolve the error. |
| ImagePullBackOff | Back-off pulling image ¥"docker. io/cilium/starwaraaes¥" | The error message means that Kubernetes is having difficulty downloading the necessary image from the doc ker hub.A possible solution would be to check the image name and make sure it is correct. It could also be a network c onnectivity issue, so checking the network settings could also help resolve the problem. |
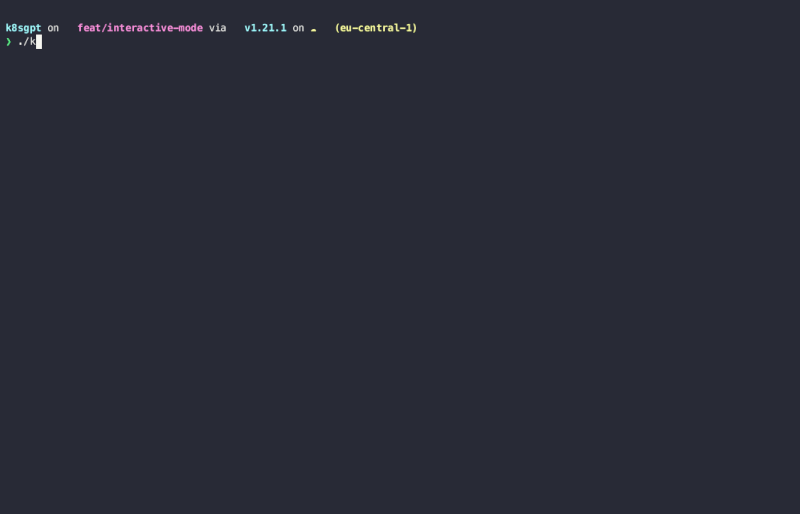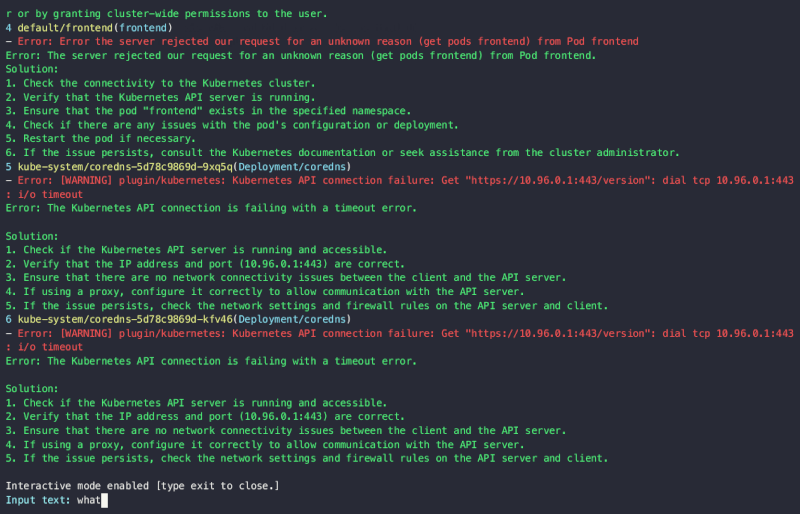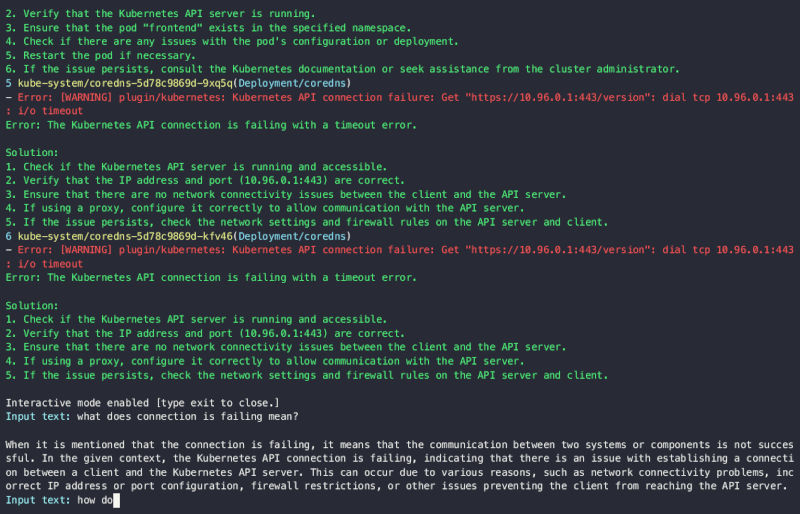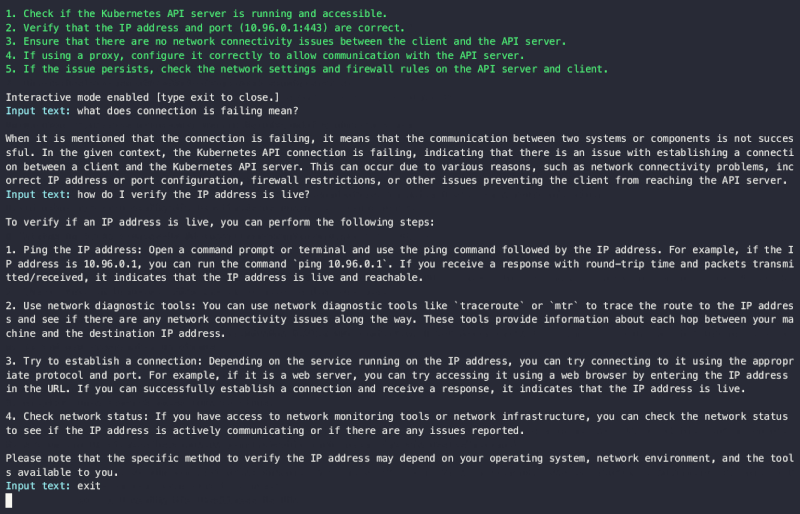
interactive debugging modeの例【出典】Alex JonesのLinkedin投稿
Analyzersの紹介
Pod Analyzerを例にK8sGPTの使われ方を確認しました。次は、他にどのようなAnalyzerが用意されているかを見ていきます。表2に在提供されているAnalyzerとその確認内容を整理しました。
Analyzerのカテゴリには「デフォルト」「オプション」「インテグレーション」の3つがあります。デフォルトとオプションはKubernetes標準リソース、インテグレーションは標準リソース以外のカスタムリソース・ミドルウェアを扱っています。
どのようなチェックをしているのかを見てみると、大きく分けて「リソースの状態が正常でないもの」「リソースの設定値が意図していないもの」「出力結果の解説」をベースとして定義されていそうです。個人的にはPod Analyzer、Log Analyzer、trivy、kyvernoあたりは使ってみたいなと思いました。
表2:Analyzer一覧
| デフォルト | Pod | [ ] Pending Pod [ ] CrashLoopBackOff Pod [ ] Waiting Reasonがエラーと判断したもの |
| PVC | [ ] ClaimPending | |
| ReplicaSets | [ ] ReplicaFailure | |
| Service | [ ] Endpointが紐づいていないService [ ] NodeReadyAddressesなEndpoint [ ] EndpointのイベントがNormalでないもの | |
| Ingress | [ ] Ingress Classに値がない [ ] 指定したIngress Classが存在しない [ ] 指定したバックエンドサービスが存在しない [ ] 指定 した TLS Secrets が存在しない | |
| StatefulSets | [ ] 指定したServiceがない [ ] VolumeClaimTemplateで指定したStorage Classがない [ ] レプリカ数が不一致 | |
| Deployment | [ ] レプリカ数が不一致 | |
| CronJob | [ ] Suspendされている [ ] Cronスケジュールのフォーマットが間違っている [ ] StartingDeadlineSecondsがマイナスの値に設定されている | |
| Node | [ ] NodeがNotReady等意図していない | |
| MutatingWebhook | [ ] Webhookサーバが存在しない | |
| ValidatingWebhook | [ ] Webhookサーバが存在しない | |
| オプション | HPA | [ ] HPAの状態がFalseである [ ] ScaleTargetRefに指定したリソースが存在しない [ ] ScaleTargetRefに指定したリソースがRequests/Limitsを設定していない |
| Pod Disruption Budget | [ ] PDBに設定するセレクターが間違えている | |
| NetworkPolicy | [ ] 全てのトラフィックを許可している [ ] セレクターを設定しているがマッチするPodが存在しない | |
| GatewayClass | [ ] GatewayClassの状態がFalseである | |
| Gateway | [ ] GatewayClassが存在しない [ ] Gatewayの状態がFalseである | |
| HTTPRoute | [ ] 親オブジェクトであるGatewayが存在しない [ ] GatewayがHTTPRouteの名前空間を許可していない [ ] バックエンドサービスが存在しない [ ] バックエンドサービスとポートが一致しない | |
| Log | [ ] エラーログの検出 | |
| Custom Analyzer | [ ] WebAPI経由で独自のAnalysisを定義可能 | |
| インテグレーション | aws | [ ] AWS APIから取得するEKSクラスタの状態が意図していない |
| keda | [ ] scaleTargetRefに指定したリソースが存在しない [ ] ScaleTargetRefに指定したリソースがRequests/Limitsを設定していない | |
| kyverno | [ ] ClusterPolicyReportの結果がCRITICAL [ ] PolicyReportの結果がfail | |
| prometheus | [ ] 設定ファイルの構文が間違っている [ ] ScrapeConfigsが設定されていない [ ] Relabel Configの解説 | |
| trivy | [ ] VulnerabilityReportの結果がCRITICAL [ ] ConfigAuditReportの結果がMEDIUM以上 |
Custom Analyzerの深掘り
ここまではK8sGPT組み込みのAnalyzerについて紹介しましたが、外付け可能なCustom Analyzerが登場しました。このCustom Analyzerを設定すると分析の実装を別のWebAPIサーバに委譲できるようになります。セットアップ方法についてはこちらを参照ください。
私個人としては、アップストリームに提案する前にPoCとして試せることやKubernetes以外のコンテキストも取り込んでしまえる点が利点と感じています。前者の使い方をする場合はインターフェースであるAnalyzerRunRequestからクラスタの情報を取得できないため、少し面倒に感じてしまうかもしれません。後者は、環境固有の情報(ex:アプリケーションの詳細なログ)、Kubernetesのスコープを超えた情報を渡せる点が嬉しいかもしれないと思いました。Custom Analyzerの開発者はNodeの情報から分析を実行するhost-analyzerを例として挙げています。
脱線しますが、Custom Analyzerが出るまではAnalyzerへの分析追加が組み込みのため、ValidatingAdmissionPolicy、Prometheus Rule等のように標準化されたAPIで誰もが簡単にAnalyzerを追加できないかという議論もありました(残念ながら当時の議論はSlackの無料枠制限で参照できませんでした)。
message AnalyzerRunRequest {
}
message AnalyzerRunResponse {
Result result = 1;
}
service AnalyzerService {
rpc Run(AnalyzerRunRequest) returns (AnalyzerRunResponse) {}
}
message Result {
string kind = 1;
string name = 2;
repeated ErrorDetail error = 3;
string details = 4;
string parent_object = 5;
}K8sGPTを試してみる
ここまでで、K8sGPTの機能をインプットしたので、実際に使ってみましょう。インストールはこちらから。
K8sGPTには「CLI」「サーバ」と2つのモードがあります。サーバモードではWebAPI経由でAnalyzeを呼び出すことができ、k8sgpt-operatorと連携することで常時監視(リコンサイルに合わせて分析を呼び出す仕組み)にすることもできます。CLIモードではK8sGPT Playgroundが提供されています。詳細はこちらをご覧ください。今回は、サーバモードについて使い方を見ていきます。
利用時の注意点
実際に利用する前に、生成AIのコストに注意が必要です。Analyzerのフィルタを行わない場合、デフォルトで設定している分析が全て実行されてしまいます。これに対しては2つのアクションを取ることができます。
1つ目はフィルターです。検知されたリソース単位(≒ Analyzer単位)で生成AIへのリクエストが送られるため、フィルタを設定することで消費するトークン数を削減します。下記のコマンドを参照することで使用したいAnalyzerのみを指定して分析を実行できます。前述した表を元に必要なものだけ有効化にすることをおすすめします。
# ① フィルタ(Analyzer)一覧
$ k8sgpt filters list
Active:
> Pod
> CronJob
…
# ② filter フラグで Analyzer を指定。複数の場合はカンマで連結
$ k8sgpt analyze --explain --filter=Pod,CronJob2つ目はキャッシュです。プロンプトの文章が同じ場合は、キャッシュから回答を取得し生成AIへの問い合わせを省略できます。デフォルトではファイルキャッシュ(ローカルキャッシュ)が有効になっています。また、AWS S3、Azure Storage、Google Cloud Storageもキャッシュの保存先として選択できます。
リモートキャッシュの設定についてはこちらを参照してください。
$ k8sgpt analyze --explain --no-cache=falseK8sGPTサーバモード
サーバモードで起動する際はK8sGPT Operatorを使うことがおすすめです。K8sGPT Operatorの役割は「分析の定期実行」「分析結果の永続化」「分析結果の通知」「メトリクスの配信」です。表3に何をしているか整理しました。K8sGPT Operatorによって、より運用のシーンでK8sGPTを活用できます。
表3:K8sGPT Operatorの役割
| 分析の定期実行 | Kubernetes ControllerのリコンサイルループでK8sGPTに分析リクエストを送る |
| 分析結果の永続化 | 分析の実行結果をResultというカスタムリソースに保存する |
| 分析結果の通知 | Slack / Mattermostに分析の実行結果を送信する |
| メトリクスの配信 | Resultの数、生成AIへのリクエスト数等をカウントとして保持する メトリクス一覧 |
サーバモードは、K8sGPT Operatorの構築と以下のカスタムリソースの適用で構築できます。
# k8sgpt.yaml
apiVersion: core.k8sgpt.ai/v1alpha1
kind: K8sGPT
metadata:
name: k8sgpt-sample
namespace: k8sgpt-operator-system
spec:
# 先ほどの使用する Analyzer の指定
filters:
- Pod
- CronJob
# S3にキャッシュを入れる設定
noCache: false
remoteCache:
credentials:
name: ''
s3:
bucketName: ''
region: ''
# 生成AI バックエンドの設定
ai:
enabled: true
model: gpt-3.5-turbo
backend: openai
secret:
name: k8sgpt-sample-secret
key: openai-api-key
# 分析結果の通知先指定
sink:
type: slack
webhook: ''
channel: ''
username: ''
icon_url: ''
secret:
name: k8sgpt-sample-secret
key: slack-key
---
# k8sgpt-sample-secret.yaml
apiVersion: v1
kind: Secret
metadata:
name: k8sgpt-sample-secret
data:
openai-api-key: <base64でエンコードされたAPIキー>
slack-key: <base64でエンコードされたAPIキー>K8sGPTのカスタムリソースでは、以下の設定を含めます。
- Analyzerの指定
- リモートキャッシュの設定
- 使用する生成AIの設定
- 分析結果の通知先設定
(より詳しくパラメータを確認したい場合はAPI定義を参照ください)
うまくいけば、分析の結果アラートが必要だった場合に下図のような通知が届くはずです。

分析結果をチャットツールへ送信する例
生成AIを使用してスケジュールするSchednexの登場
最後に、K8sGPTのオーガナイザーであるAlexsJonesがK8sGPTと連携するKubernetes Schedulerの開発をスタートしたとのことで、概要を見てみたいと思います。おそらく、まだ構想段階でアイデアを膨らませている状況だと思います。
Schednexに興味があればプロジェクトに参加して欲しいとの呼びかけ【出典】k8sgpt community slack
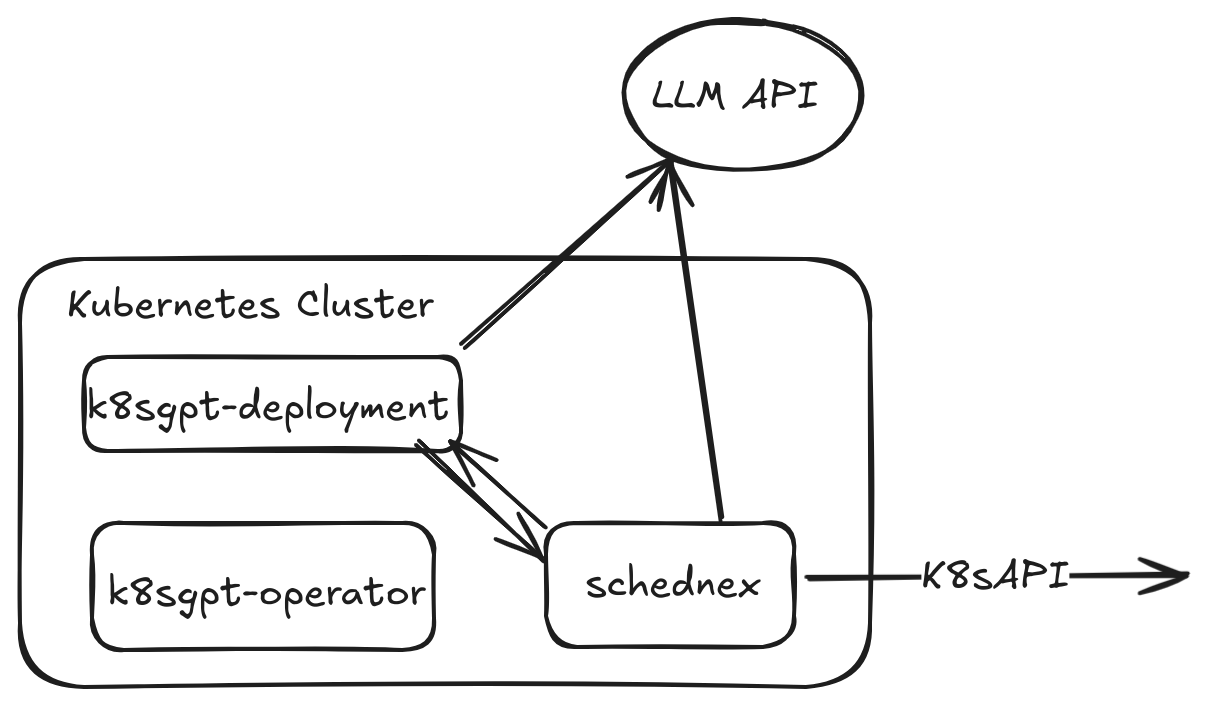
Schednexの構成図【出典】design.png
環境準備では、次の3点が気になるところでしょうか。
- K8sGPT OperatorでK8sGPTをインストールすること
- K8sGPTのバージョンがv0.3.41以上であること
- メトリクスサーバがインストールされていること
1.についてはK8sGPTをサーバモードで構築することが簡単だからだと思われます。その他は少し深掘りしてみることにします。
2.k8sgptのバージョンがv0.3.41以上であることは何故か
v0.3.41では、schednex scheduler向けにquery modeが追加されていました。changesを確認するとk8sgptのサーバモードで受け取ったプロンプトをそのまま送信し、レスポンスを返すAPIが追加されています。そのため、Schednexから生成AIへのリクエストを仲介する役割がありそうでした。
3.メトリクスサーバがインストールされているのはなぜか
メトリクスサーバ も合わせてインストールする必要がありますが、これはスケジュールの際に必要な情報を取得するためだと思われます。後にSchednexが送信するプロンプトを見るので、そこで詳しく紹介します。
Schednexはどのようなプロンプトを送っているか
プリセットは以下の通りです。ノードの情報と分析の結果を元に、Podの最適な配置先を教えてほしいという内容です。最後にno other text.とあるので、うまくいけばノードの名前だけ返してくれるのでしょうか。
プロンプトに渡しているのは、次の3つのパラメータです。
- クラスタに参加しているノードのメトリクス
- 分析結果
- OwnerReferenceが同じPodの配置先
順にパラメータの実際の値を見ていきましょう。
Given the following nodes and analysis of issues in the cluster, I want you to tell me the best node for placement, no other text.
Please find the data in two segments below:
1. Nodes in the cluster: ${nodeMetricsListJson}
2. Analysis of issues in the cluster (this may be empty): ${k8sgptAnalysis}
3. Relatives and their current placement: ${relative_placement}- クラスタに参加しているノードのメトリクス
ノード名とリソース使用量 (CPU/Memory) のセットが入ります。[{ "ObjectMeta": { "Name": "<node-name>", "Labels": { "beta.kubernetes.io/arch": "amd64", "beta.kubernetes.io/os": "linux" }, "CreationTimestamp": "2024-04-22T12:50:14Z" }, "Timestamp": "<timestamp>", "Window": "<window-duration>", "Usage": { "cpu": "<usage-quantity-1>", "memory": "<usage-quantity-2>" } }] - 分析結果
k8sgptAnalysisには、k8sgptの分析結果が入ります。{ "error":{ :"メッセージ、コードなど)" }, "errors":[ "<error-message-1>", "<error-message-2>" ], "status":"<status-string>", "problems":"<problems-count>", "results":[ { "kind":"<kind-string>", "name":"<name-string>", "error":[ { "text":"<text-string>""sensitive":[ ] } ], "details":"<details-string>", "parent_object":"<parent-object-string>" } ] } - OwnerReferenceが同じPodの配置先
relative_placementはスケジュールできていないPodを取得、そのPodのOwnerReferenceを確認し、兄弟Pod がスケジュールされているNodeを以下のフォーマットで整理します。{ "<pod-name1> is a related pod and resides on":"<node-name1>", "<pod-name2> is a related pod and resides on":"<node-name2>" }
最終的に組み立てられるプロンプトのイメージは下記のとおりです。
Given the following nodes and analysis of issues in the cluster, I want you to tell me the best node for placement, no other text.
Please find the data in two segments below:
1. Nodes in the cluster: ${nodeMetricsListJson}
[{
"ObjectMeta": {
"Name": "<node-name>",
"Labels": {
"beta.kubernetes.io/arch": "amd64",
"beta.kubernetes.io/os": "linux"
},
"CreationTimestamp": "2024-04-22T12:50:14Z"
},
"Timestamp": "<timestamp>",
"Window": "<window-duration>",
"Usage": {
"cpu": "<usage-quantity-1>",
"memory": "<usage-quantity-2>"
}
}]
2. Analysis of issues in the cluster (this may be empty):
{
"error":{
:"メッセージ、コードなど)"
},
"errors":[
"<error-message-1>",
"<error-message-2>"
],
"status":"<status-string>",
"problems":"<problems-count>",
"results":[
{
"kind":"<kind-string>",
"name":"<name-string>",
"error":[
{
"text":"<text-string>""sensitive":[
]
}
],
"details":"<details-string>",
"parent_object":"<parent-object-string>"
}
]
}
3. Relatives and their current placement:
{
"<pod-name1> is a related pod and resides on":"<node-name1>",
"<pod-name2> is a related pod and resides on":"<node-name2>"
}GeminiとChatGPTで確認しましたが、レスポンスは<node-name>のみが出力されました。この値を使ってPodをNodeにバインドしています。
Schednexを調べてみて、以下の考慮が必要だと感じました。
- 現行のプロンプトだと、クラスタの規模に合わせてNodeとPod、トークンの数が増えていくため、Context Window(1度に処理できるトークン数)やコスト面での注意、利用者としては導入可能かの検討が必要かもしれません。
- スケジュールの判断は生成AIが担うためリクエストの往復で、Podがスケジュールできるまでにかかる時間が長くなることが予想できます。また、生成AI側のレートリミットにも影響を受けるため、パフォーマンスで問題がないかの検討が必要かもしれません。
KubernetesにはTaints / Tolerations、Pod Topology Spread Constraints、Affinity、Pod Priority and Preemption等々Podのスケジューリングを調整する仕組みがありますが、現状Schednexはこれらを考慮していません。プロジェクトとしては既存の仕組みをカバーするのか、新しいスケジューリングの体験を生むのかなど今後追っていけたらなと思いました。
おわりに
今回は、K8sGPTとK8sGPT Operatorの概要と使い方、そしてSchednexというスケジューラーについて紹介しました。K8sGPTにKubernetes利用者の知見を集め、生成AIを活用してデバッグをサポートするというコンセプトは素敵だなと思っています。より高度なデバッグをこなせるようになれば、Kubernetesの運用が今以上に効率化されるかもしれません。
もし、これらのプロジェクトに興味をお持ちいただけたら、ぜひ導入を検討してみてください。Slack Communityのリンクもこちらに。
この記事をシェアしてください
関連記事
Kubernetesの基礎
2018年3月14日 6:00
Kubernetesの信頼性を高める! カオスエンジニアリングツール「Krkn」
2025年10月15日 6:30
「kind」でローカル環境にKubernetesクラスターを構築する
2024年8月28日 9:13
ASTの解析とCLIの実装によるTypeScript製Lintツール開発
2025年7月30日 6:30
「kwok」でKubernetesクラスターをシュミレーションする
2024年9月19日 6:30
Oracle Cloud Hangout Cafe Season5 #3「Kubernetes のセキュリティ」(2022年3月9日開催)
2023年4月18日 6:30
バックナンバー
この記事の筆者

Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
