KubernetesのWorkloadsリソース(その2)
前回に引き続き、ユーザーが利用できるWorkloadsリソース8種類のうち4種類を紹介する。
2018年4月4日 6:00
前回に引き続き、KubernetesのWorkloadsリソースについて解説します。
- Pod
- ReplicationController
- ReplicaSet
- Deployment(前回はここまで解説しました)
- DaemonSet(今回はここから解説します)
- StatefulSet
- Job
- CronJob
DaemonSet
DaemonSetは、前回説明したReplicaSetの特殊な形ともいえるリソースです。ReplicaSetは、各Kubernetes Node上に合計でx個のPodをNodeのリソース状況に合わせて配置していきます。そのため、各Node上のPodの数が必ず等しいとも限りませんし、各Node上に確実に配置されるとも限りません。一方DaemonSetは、全nodeに1 podずつ配置するリソースとなっています。そのため、レプリカ数などは指定できませんし、2 podずつ配置するといったこともできません。
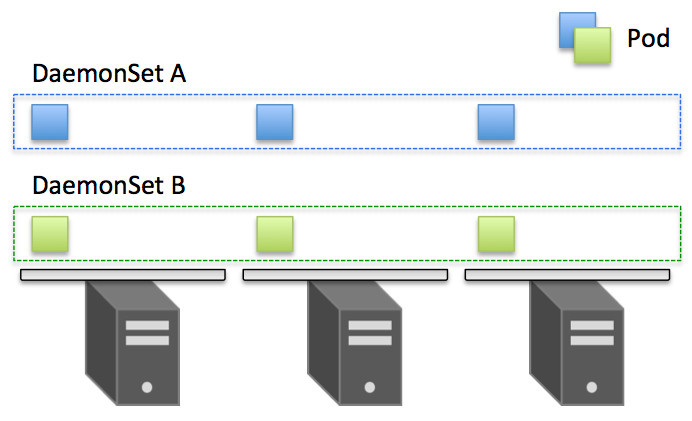
DaemonSet
DaemonSetのユースケースとしては、各Podが出すログを収集するFluentdや、各Podのリソース使用状況やノードの状態をモニタリングするDatadogなど、全Node上で必ず動作している必要のあるプロセスのために利用されることが多くなっています。
DaemonSetの作成
簡単なDaemonSetのサンプルを動作させてみます。まず設定ファイルですが、下記のようなファイルから、sample-dsを作成します。先ほどの単体で作成したPodを使ってDaemonSetを作成します。ReplicaSetなどと異なり、レプリカ数などを指定する項目はありません。
リスト1:サンプルのDaemonSetを作成するds_sample.yml
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: sample-ds
spec:
selector:
matchLabels:
app: sample-app
template:
metadata:
labels:
app: sample-app
spec:
containers:
- name: nginx-container
image: nginx:1.12
ports:
- containerPort: 80
設定ファイルを元にDaemonSetを作成します。
リスト2:ds_sample.ymlからDaemonSetを作成
$ kubectl apply -f ./ds_sample.yml
daemonset "sample-ds" created
DaemonSetを確認してみると、各Nodeに1 Podずつ起動していることが確認できます。
リスト3:起動したDaemonSetの情報を確認
$ kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE
sample-ds-7kwlc 1/1 Running 0 1m 10.8.2.12 gke-k8s-default-pool-9c2aa160-v5v4
sample-ds-9lkpz 1/1 Running 0 1m 10.8.0.19 gke-k8s-default-pool-9c2aa160-d2pl
sample-ds-tnnfk 1/1 Running 0 1m 10.8.1.13 gke-k8s-default-pool-9c2aa160-9f6b
StatefulSet
StatefulSetもReplicaSetの特殊な形とも言えるリソースです。その名の通り、データベースなどstatefulなワークロードに対応するためのリソースとなります。
ReplicaSetとの主な違いは下記のようなものが挙げられます。
- 生成されるPod名が数字でindexingされたものになる
- sample-statefulset-1、sample-statefulset-2、…… sample-statefulset-N
- 永続化するための仕組みを有している
- PersistentVolumeを使っている場合は同じディスクを利用して再作成される
- Pod名が変わらない
StatefulSetの作成
簡単なStatefulSetのサンプルを動作させてみます。まず設定ファイルですが、下記のようなファイルからsample-statefulsetを作成します。こちらも、前回の記事で単体で作成したPodを使ってStatefulSetを作成します。ReplicaSetの定義に比べてspec.volumeClaimTemplatesを指定することができ、永続データ領域を使いまわし、Podの復帰時に同じデータを保持した状態でコンテナが作成されるようになります。
リスト4:サンプルのStatefulSetを作成するstatefulset_sample.yml
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: sample-statefulset
spec:
replicas: 3
selector:
matchLabels:
app: sample-app
template:
metadata:
labels:
app: sample-app
spec:
containers:
- name: nginx-container
image: nginx:1.12
ports:
- containerPort: 80
volumeMounts:
- name: www
mountPath: /usr/share/nginx/html
volumeClaimTemplates:
- metadata:
name: www
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 1Gi
設定ファイルを元にStatefulSetを作成します。
リスト5:statefulset_sample.ymlからStatefulSetを作成
$ kubectl apply -f ./statefulset_sample.yml
statefulset "sample-statefulset" created
StatefulSetを確認してみると、ほとんどReplicaSetと同じような情報が表示されます。
リスト6:起動したStatefulSetの情報を確認
$ kubectl get statefulset
NAME DESIRED CURRENT AGE
sample-statefulset 3 3 7m
Podを確認してみると、StatefulSetで作られたPodは名前に連番のindexがsuffixとして付いていることが確認できます。また、レプリカ数の変更によるPodの作成/削除が発生した場合には、ReplicaSetやDaemonSetなどと異なり、Podを1つ1つ作成/削除するため、ほんの少しだけ時間がかかる傾向にあります(詳細は後述します)。
リスト7:詳細な情報を出力する
$ kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE
sample-statefulset-0 1/1 Running 0 2m 10.8.0.20 gke-k8s-default-pool-9c2aa160-d2pl
sample-statefulset-1 1/1 Running 0 2m 10.8.0.21 gke-k8s-default-pool-9c2aa160-d2pl
sample-statefulset-2 1/1 Running 0 1m 10.8.1.14 gke-k8s-default-pool-9c2aa160-9f6b
今回の例だと、スケールアウトさせていく際にはsample-statefulset-0、sample-statefulset-1、sample-statefulset-2の順に作られていきます。
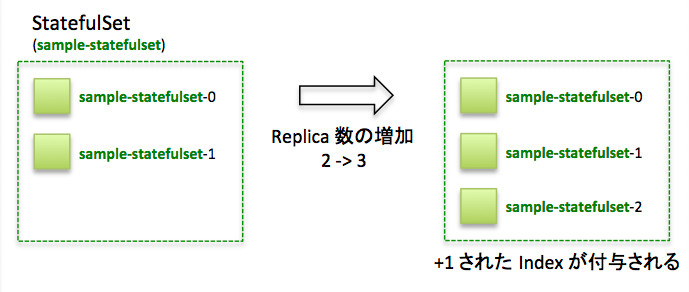
StatefulSetのスケールアウト
一方でスケールインの場合には、sample-statefulset-2、sample-statefulset-1、sample-statefulset-0の順に削除されていきます。
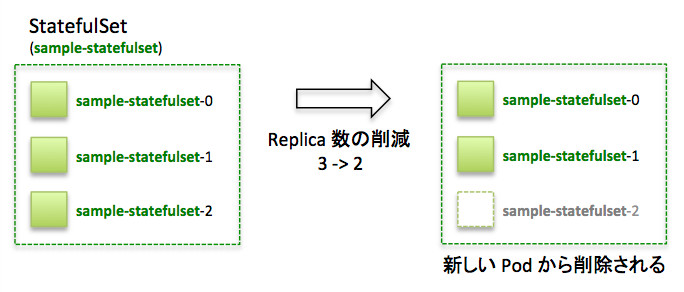
StatefulSetのスケールイン
ReplicaSetの場合にはランダムに削除されていくため、最初のPodがマスターとなるようなアプリケーションには向きませんが、StatefulSetではこうしたワークロードにも対応することが可能です。
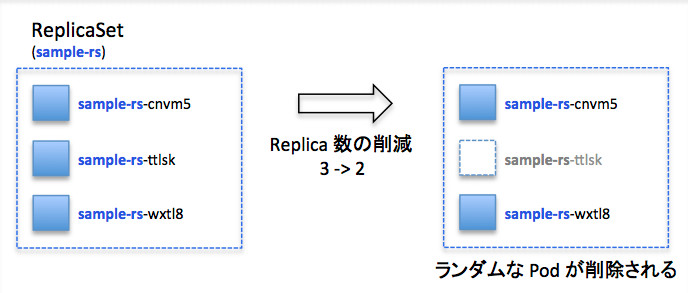
ReplicaSetのスケールイン
StatefulSetのスケーリング
ReplicaSetsと同様の方法で「kubectl scale」または「kubectl apply -f」を使ってスケールさせることが可能です。
永続化領域のデータ保持の確認
マウントしたデータ領域に同名のファイルがないことを確認してから、サンプルファイルを作成します。
リスト8:永続化領域のデータが保持されることを確認
$ kubectl exec -it sample-statefulset-0 ls /usr/share/nginx/html/sample.html
ls: cannot access /usr/share/nginx/html/sample.html: No such file or directory
$ kubectl exec -it sample-statefulset-0 touch /usr/share/nginx/html/sample.html
$ kubectl exec -it sample-statefulset-0 ls /usr/share/nginx/html/sample.html
/usr/share/nginx/html/sample.html
kubectlからPodの削除を行った場合や、コンテナ内でExceptionが発生し、コンテナが停止した場合などでも、復帰後にファイルが失われることはありません。
リスト9:Podを削除
$ kubectl delete pod sample-statefulset-0
pod "sample-statefulset-1" deleted
リスト10:Exceptionを発生させコンテナを停止
$ kubectl exec -it sample-statefulset-0 bash
root@sample-statefulset-0:/# kill 0
リスト11:作成したファイルは保持されている
$ kubectl exec -it sample-statefulset-0 ls /usr/share/nginx/html/sample.html
/usr/share/nginx/html/sample.html
復帰後のStatefulSetの状態を確認してみると、IP Addressは変わっているもののPod名に変更がないことが確認できます。
リスト12:復帰後もPod名は変更がない
$ kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE
sample-statefulset-0 1/1 Running 0 2m 10.8.0.23 gke-k8s-default-pool-9c2aa160-d2pl
sample-statefulset-1 1/1 Running 0 2m 10.8.0.21 gke-k8s-default-pool-9c2aa160-d2pl
sample-statefulset-2 1/1 Running 0 1m 10.8.1.14 gke-k8s-default-pool-9c2aa160-9f6b
StatefulSetのライフサイクル
StatefulSetはReplicaSetなどとは異なり、複数のPodを並行して立てることはしません。1つずつPodを作成し、Ready状態になってから次のPodを作成し始めます。また、削除時にはIndexが一番大きいもの(一番新しいコンテナ)から削除します。そのため、冗長化構成を行う場合には、常にindex:0がMasterとなるような構成を取ることが可能です。
Job
Jobとは、コンテナを利用して一度限りの処理を実行させるリソースです。より具体的には、並列実行なども行いながら、指定した回数までコンテナの実行(正常終了)が保証されるリソースです。
Jobの使い所とPodとの違い
JobとPodやReplicaSetとの大きな違いは、「Pod が停止することを前提にして作られているかどうか」です。PodやReplicaSetなどでは基本的には停止=予期せぬエラーですが、Jobの場合は停止=正常終了となるようなものに向いています。また、PodやReplicaSetなどでは正常終了の数などをカウントしているわけではないので、バッチ的な処理の場合にはJobを積極的に利用しましょう。
Jobの作成
簡単なJobのサンプルを動作させてみます。まず設定ファイルですが、下記のようなファイルから、sample-job を作成します。今回は 60 秒 sleep するだけの Job を作成します。ReplicaSets 同様、label と selector は自分でつけることもできますが、kubernetes が自動で衝突しない uuid を自動生成するため、自分でつけるのは推奨されていません。
リスト13:サンプルのJobを作成するjob_sample.yml
apiVersion: batch/v1
kind: Job
metadata:
name: sample-job
spec:
completions: 1
parallelism: 1
backoffLimit: 10
template:
spec:
containers:
- name: sleep-container
image: centos:latest
command: ["sleep"]
args: ["60"]
restartPolicy: Never
設定ファイルを元にJobを作成します。
リスト14:job_sample.ymlからJobを作成
$ kubectl apply -f job_sample.yml
job "sample-job" created
Jobを確認してみると、ReplicaSetなどとは異なりREADYなコンテナ数を表示するのではなく、正常に終了しているカウント数を表示しています。
リスト15:Jobの動作を確認
$ kubectl get jobs
NAME DESIRED SUCCESSFUL AGE
sample-job 1 0 28s
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
sample-job-bhzs7 1/1 Running 0 31s
restartPolicyによる挙動の違い
spec.template.spec.restartPolicyにはOnFailureまたはNeverが指定可能です。Neverを指定した場合、Podが障害時には新規のPodが作成されます。一方でOnFailureの場合には、再度同一のPodを利用してJobを再開します。
restartPolicy: Neverの場合
Job用に生成されたPod内のプロセスが停止すると、新規のPodが生成してJobを遂行しようとします。
リスト16:新規のPodが生成してJobを遂行
$ kubectl exec -it sample-job-70v3t -- kill -9 1
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
sample-job-bhzs7 1/1 Terminating 0 2m
sample-job-prb57 1/1 Running 0 3s
restartPolicy: OnFailureの場合
Job用に生成されたPod内のプロセスが停止すると、RESTARTSのカウントが増加し、使用していたPodを再利用してJobを遂行しようとします。
リスト17:Podを再利用してJobを遂行
$ kubectl exec -it sample-job-70v3t -- kill -9 1
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
sample-job-70v3t 1/1 Running 1 10s
並列Jobとワークキュー型の実行
上記のJobでは、実行の回数を指定するcompletionsと並列度を指定するparallelismという設定項目にはそれぞれ1を指定していました。デフォルトでも1が指定されるため、明示的に指定しなくても動作は変わりません。この2つのパラメータは、Jobを並列化して実行する際に利用するオプションとなります。下記のような例では、2並列で実行し、10回成功したら終了するJobとなっています。またbackoffLimitは、失敗を許容する回数です。
リスト18:2並列で、10回成功したら終了するJobの設定ファイル
apiVersion: batch/v1
kind: Job
metadata:
name: sample-paralleljob
spec:
completions: 10
parallelism: 2
backoffLimit: 10
template:
metadata:
name: sleep-job
spec:
containers:
- name: sleep-container
image: centos:latest
command: ["sleep"]
args: ["30"]
restartPolicy: Never
completionsとparallelismとbackoffLimitの3つは非常に重要なパラメータであり、Jobのワークロードに応じて適切に設定する必要があります。
ワークロード別パラメータの使い分け
| ワークロード | completions | parallelism | backoffLimit |
|---|---|---|---|
| 1回だけ実行するタスク | 1 | 1 | 1 |
| N並列で実行させるタスク | M | N | P |
| 1個ずつ実行するワークキュー | 未指定 | 1 | P |
| N並列で実行するワークキュー | 未指定 | N | P |
1回だけ実行したいタスクの場合には、例にあったようにcompletions=1、parallelism=1、backoffLimit=1を指定します。
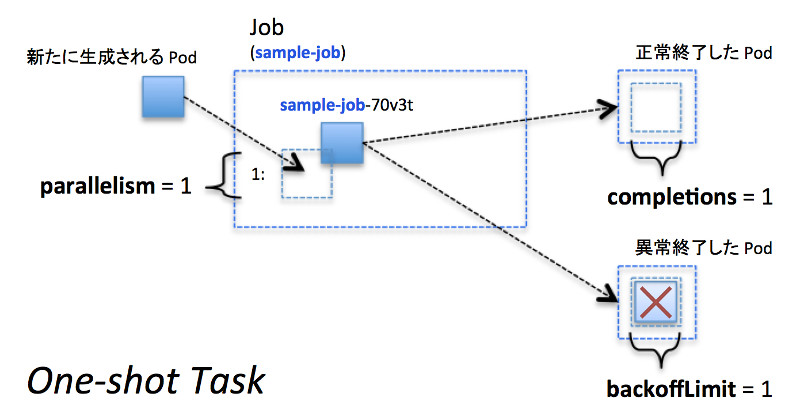
1回だけ実行したいタスク
一方で並列数と完了数を変えることで、並列ジョブを作成することが可能です。例えばcompletions=5、parallelism=3でJobを実行した場合、最初に3つのPodが作成され、上記の例では30秒後に3つのJobが終了します。その後は残り2つのJobを完了すれば良い状態ため、2 Podだけ生成される点に注意して下さい。
成功率が低いJobなどの場合では、「3並列で走らせて成功するPodが出たら終了する」といったことを行いたい場合もありますが、現状では提供されていません。
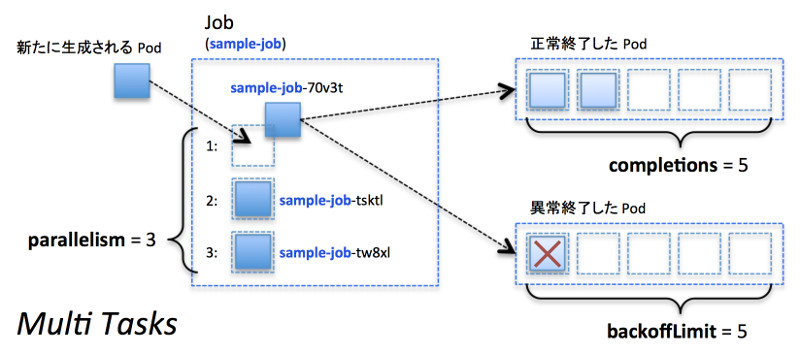
並列実行タスク
さらに、completionsを指定しなかった場合、コンテナを起動しては特定のタスクを実行し続ける状態になります。つまりJobを完遂するまでの成功数が指定されていない場合には、ワークキューとして動作するような形になります。backoffLimitは未指定の場合、デフォルト値の6となる点だけには注意して下さい。
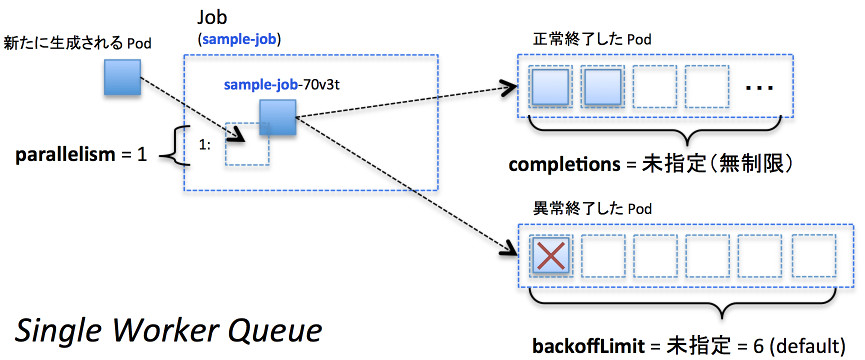
1個ずつ実行するワークキュー
並列数のみ決まっており、永続的に実行したいJobを作成する場合にはparallelismのみ指定して下さい。また、Parallel Jobの並列度(parallelism)はDeploymentなどと同様に「kubectl scale job ...」コマンドを使って後から制御することも可能です。
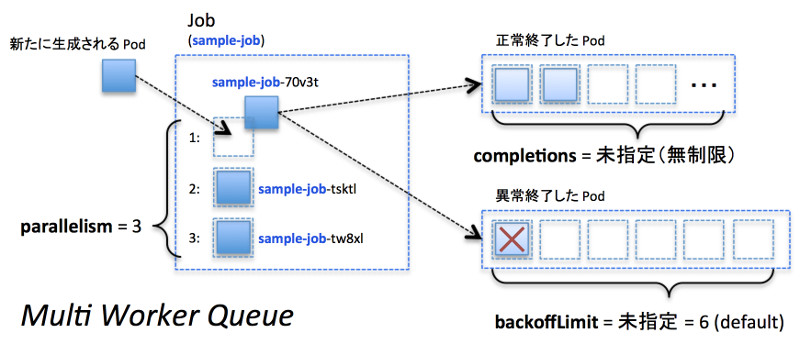
並列実行するワークキュー
この記事をシェアしてください
関連記事
Kubernetesの基礎
2018年3月14日 6:00
KubernetesのConfig&Storageリソース(その1)
2018年5月31日 6:00
KubernetesのConfig&Storageリソース(その2)
2018年6月6日 6:00
Oracle Cloud Hangout Cafe Season5 #3「Kubernetes のセキュリティ」(2022年3月9日開催)
2023年4月18日 6:30
Kubernetes上のコンテナをIngressでインターネットに公開するまで
2021年4月16日 7:15
Kubernetesの信頼性を高める! カオスエンジニアリングツール「Krkn」
2025年10月15日 6:30
バックナンバー
この記事の筆者

筆者の人気記事
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
