高度な日本語検索を実現する技術
自然言語処理(NLP)方式の概要
自然言語処理(NLP)方式は、形態素解析や用語の正規化などの処理を行いながらインデックスを作成して、全文検索を行う手法です。N-gram方式との違いは、N-gram方式が決められた文字数でわかち書きを行うのに対し、自然言語処理(NLP)方式では形態素解析により文書を適切にわかち書きし、品詞を決定し、インデックスを作成する点です。
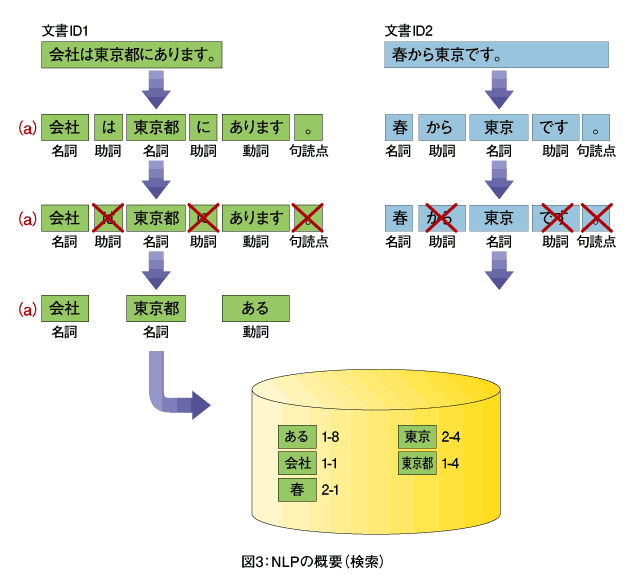
例えば、「会社は東京都にあります。」という文書(ID1)を形態素解析すると、「会社(名詞)」「は(助詞)」「東京都(名詞)」「に(助詞)」「あります(動詞)」「。(句読点)」に分割され、それぞれ品詞が決定されます。次に、設定によっても変化しますが、名詞、動詞、形容詞がインデックスに登録されます。
また形態素解析を行った後、用語の正規化が行われ、「あります」が「ある」に正規化されます。このように形態素解析を行い、用語の正規化を行った結果がインデックスに登録されます。同様に、「春から東京です。」という文書(ID2)は、「春(名詞)」と「東京(名詞)」がインデックスに登録されます。
この自然言語処理(NLP)方式によるインデックス作成では、「東京都」から「京都」というインデックスが作成されないので、「京都」というキーワードで検索しても文書(ID1)はヒットしません。また、「東京」と「東京都」が別のインデックスとして登録されているので「東京」というキーワードで検索しても「東京都」をヒットさせないことも可能です。
さらに自然言語処理(NLP)方式では、「東京にある会社」という自然言語を検索キーワードにすることで、「会社は東京都にあります。」という文書をヒットさせることが可能です(図3)。
自然言語処理(NLP)方式のメリット/デメリット
自然言語処理(NLP)方式による全文検索のメリットは、まず、ノイズが少ないことがあげられます。N-gram方式の検索では、「京都」で「東京都」がヒットしてしまいますが、自然言語処理(NLP)方式ではヒットしません。また、「ある」と「あります」を同一とみなすように活用形を同一視した検索も可能です。さらに検索に不要と思われる語句はインデックスに登録されないので、インデックスのサイズを削減することも可能になります。
一方、デメリットは、形態素解析の処理系が知らない語句を検索できない場合に、漏れが生じることです。例えば、形態素解析の処理系が「アルデヒド」という言葉を知らなければ、「ホルムアルデヒド」と「アセトアルデヒド」は、それぞれ別の語句としてインデックスに登録され、「アルデヒド」から「ホルムアルデヒド」や「アセトアルデヒド」をヒットさせることはできません。
そこで意図した結果を得るために、形態素解析の処理系に語句を教える必要があります。一般的には、辞書を利用することでこの仕組みに対応します。ただし、辞書を変更した場合には、インデックスを再作成しなければ変更は反映されず、必要な文書を検索することはできません。辞書を変更した場合に、インデックスを再作成しなければならない点も自然言語処理(NLP)方式のデメリットの1つといえます。
ConceptBase Enterprise Search(CBES)では、「NL-Vgram方式」といってN-gram方式と自然言語処理(NLP)方式のいいとこ取りをした、新しい方式を採用しています。次回は、この「NL-Vgram方式」について、ファイルサーバーにおいてよりピンポイントに、欲しい情報を検索するための機能を紹介していきます。






