高度な日本語検索を実現する技術
2つの全文検索--走査型と索引型 「第1回:正確に、確実に情報を検索する!」では、エンタープライズサーチプラットホーム(ESP)を利用することで、企業に分散しているファイルサーバーに蓄積された情報を有効活用できる、ということをお話しました。今回は、ファイルサーバーを徹底活用するために必要不可欠な、高
2009年1月15日 20:00
2つの全文検索--走査型と索引型
「第1回:正確に、確実に情報を検索する!」では、エンタープライズサーチプラットホーム(ESP)を利用することで、企業に分散しているファイルサーバーに蓄積された情報を有効活用できる、ということをお話しました。今回は、ファイルサーバーを徹底活用するために必要不可欠な、高度な日本語検索を実現する技術について紹介します。
全文検索は、検索文字列(キーワード)を指定して、本文はもちろん、タイトルや著者名、スタイルなど、文書を構成するすべての情報を利用して、複数の文書の中からキーワードが含まれる文書を検索するための機能です。論理演算子(AND検索/OR検索/NOT検索)を利用することで、複数のキーワードを指定した検索を行うことができます。
例えば、「カレー AND インド NOT サモサ」というキーワードを指定することで、「カレー」と「インド」を含み、「サモサ」という語句を含まない文書を検索することができます。
また、キーワードの前後にワイルドカードを指定することで、指定したキーワードで始まる文字列を含む文書の検索(前方一致検索)や、指定したキーワードで終わる文書を含む文書の検索(後方一致検索)も可能になります。
この全文検索の方法には、「走査型(grep型)」と「索引型(インデックス型)」の大きく2種類の方法があります。走査型は、検索を実行したときに文書の中身を走査し、目的の文書を見つけ出す検索方法です。代表的な走査型検索ツールとして「grep」があるためにgrep型とも呼ばれます。
一方、索引型(インデックス型)は、検索対象となる文書をあらかじめ走査して文書の索引(インデックス)を作成しておき、検索時には索引を使用して必要とする文書を見つけ出す検索方法です。索引型全文検索は、検索時に文書のすべてを走査する走査型に比べ、必要な文書を高速に検索できるのが特長です。
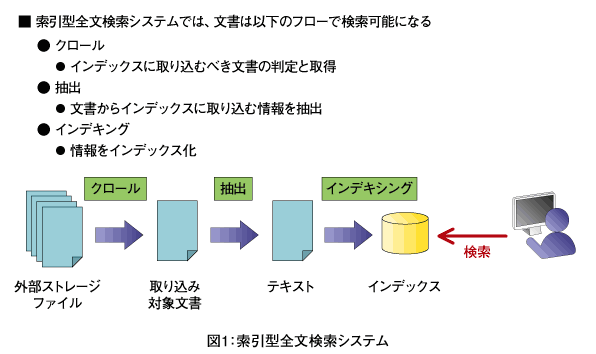
索引型全文検索のインデックス作成
索引型全文検索では、「クロール」「抽出」「インデキシング」と呼ばれる3つのステップで構成されるフローに基づき、検索対象文書のインデックスが作成され、検索が可能になります(図1)。具体的な処理の流れとしては、まずクロール処理が外部ストレージファイルからインデックスに取り込むべき文書を判断し、その文書を抽出処理に引き継ぎます。
次に抽出処理は、一太郎やMicrosoft Word/Excelなど、ファイル形式ごとに提供される抽出プログラムを使用して、インデックスに取り込むべき情報を抽出します。このとき、テキスト以外にも、スタイルや制作者など、文書に格納されているさまざまな情報を利用します。
最後のインデキシング処理は、抽出された情報をインデックスに登録する仕組みです。インデックスに登録されることで、その文書は検索対象となり、検索が可能になります。情報をインデックス化するときの主な仕組みとして、N-gram方式と自然言語処理(NLP:Natural Language Processing)方式の2つの技術があります。
- この記事のキーワード
この記事をシェアしてください
関連記事
バックナンバー
この記事の筆者

筆者の人気記事
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
