欲しい情報をピンポイントに検索する技術
より高度な索引型検索「NL-Vgram」 第2回では、エンタープライズサーチプラットホーム(ESP)を利用してファイルサーバーを徹底活用するために必要となる、全文検索の基礎知識として「走査型(grep型)」と「索引型(インデックス型)」、そして索引型を構成するN-gram方式と自然言語処理(NLP:
2009年1月22日 20:00
より高度な索引型検索「NL-Vgram」
第2回では、エンタープライズサーチプラットホーム(ESP)を利用してファイルサーバーを徹底活用するために必要となる、全文検索の基礎知識として「走査型(grep型)」と「索引型(インデックス型)」、そして索引型を構成するN-gram方式と自然言語処理(NLP:Natural Language Processing)方式について紹介しました。
これらの検索技術には、それぞれメリット、デメリットがあります。例えば走査型は索引型に比べ検索時間はかかりますが多言語に対応でき、索引型は検索は高速ですが検索する言語ごとにチューニングが必要です。また、N-gram方式は検索漏れはありませんがノイズが多く、自然言語処理(NLP)方式はノイズは少ないものの辞書を作成する必要があり、辞書の更新時にはインデックスを更新しなければなりません。
これを解消するために、例えばジャストシステムのConceptBase Enterprise Search(CBES)では、N-gram方式と自然言語処理(NLP)のメリットを兼ね備えたインデックス作成方式である「NL-Vgram方式」を採用しています。また、「XML化フィルター」「ランキングコントロール」など、より高度な検索を実現するための技術を独自に開発して搭載しています。こうした機能を使用することで、ファイルサーバーに蓄積された情報をピンポイントに検索することが可能になるのです。今回はこの情報をピンポイントに検索する機能について、その仕組みを詳しく解説していきたいと思います。
NL-Vgram方式による文書のインデックスは、「1.形態素解析による自立語の抽出 → 2.用語正規化 → 3.代表表記正規化 → 4.大文字小文字全角半角正規化 → 5.V-gram解析 → 6.自立語統計インデックス → 7.CBインデックス」という7つのステップで作成されます。
例えば、「私は、検索エンヂンA-3456BCの使い方について書かなかった。」という例文をNL-Vgramによりインデックス化する場合の処理フローでは、まず図1のように「1.形態素解析による自立語の抽出」が行われます。
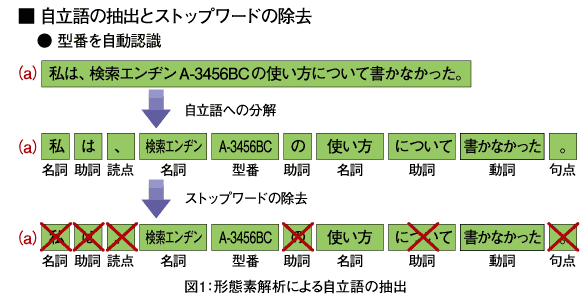
形態素解析による自立語の抽出
形態素解析による自立語の抽出では、検索対象の文書を、名詞、動詞、形容詞、副詞などの自立語に分解します。例文では、「私(名詞)」「は(助詞)」「、(読点)」「検索エンヂン(名詞)」「A-3456BC(型番)」「の(助詞)」「使い方(名詞)」「について(助詞)」「書かなかった(動詞)」「。(句点)」になります。
このとき検索ノイズになる可能性のある語句は、インデックスの作成対象から除外されます。例えば、助詞や句読点をはじめ、例文の最初に出てくる「私(名詞)」のような一般名詞もインデックス化の対象外になります。このように形態素解析によりインデックス化から除外される語句を「ストップワード」と呼びます。
例文を形態素解析した結果では、「検索エンヂン」「A-3456BC」「使い方」「書かなかった」が抽出されインデックス化されることになります。このときCBESでは、アルファベット、数詞、記号(ハイフン、スラッシュ、中黒など)で構成され、空白なしで連続している文字を、「型番」として認識します。例文では、「A-3456BC」が該当します。
- この記事のキーワード
この記事をシェアしてください
関連記事

バックナンバー
この記事の筆者

筆者の人気記事
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
