はじめに
前回でKubernetesアプリケーションのリリースまで出来るようになりました。アプリケーション開発者としての仕事はここまで……としたいところですが、リリース後にパフォーマンスが落ちた、不具合が発見された、となると、対応に当たるのは開発者であるあなたです。そこで今回と次回は、Kubernetesアプリケーションの最低限のモニタリングとロギングの仕組みと手法、さらに一歩進んでオブザーバビリティの概念と導入について解説します。
モニタリングとオブザーバビリティ
アプリケーションを運用する上でモニタリングが必要だということは、今さら言うまでもないでしょう。Kubernetesアプリケーションでも同様です。非コンテナアプリケーションを動かす場合と同じように、負荷やアクセス量、エラーレートなどのメトリクスは計測する必要がありますし、また過負荷やソフトウェア障害、通信障害、物理障害も当然発生するので、対応が必要な場合にはアラートを発報します。リリース後に大量のアラートが、だとかダッシュボードを見たらCPU利用率がものすごい値に、といった経験は多くの人がしていますね。
近年ではモニタリングに加えて、アプリケーションの内部動作に踏み込んで可視化する「オブザーバビリティ」に取り組む必要がある、と言われています。モニタリングとはすなわち、アプリケーションの状態を可視化し通知するものです。モニタリングにより異常が発生したことはわかりますが、実際に異常を解決するためには調査して問題を切り分けして、原因箇所を特定して……という作業が必要です。この調査が問題で、調査するべきログが複数行、あるいは複数ファイルに渡ってしまって突合が大変だったり、ノードやワークロードのオートスケールを導入しているとそもそも目的のログがどこにあるのかを見つけるのも一苦労だったりします。なんとか該当のログを見つけることができても、そこで手詰まりになってしまったのでログの出力を変えて再現待ち...とかいうのはよくある話です。特にマイクロサービスアーキテクチャを採用する場合には、この調査がチームの境界をまたぐ必要がありスムーズに進まない、というのもまたある話です。
オブザーバビリティとは、アプリケーションのメトリクスやログを単にモニタリングするのに留まらず、アプリケーションの動作まで踏み込んで何が起こっているのかを知るための取り組みです。なにか問題が起こったとして、もしアプリケーション内部の問題箇所の切り分けがあらかじめ出来ていれば、対処もいくらか容易ですよね。例えばリクエストを受けてからレスポンスを返すWebサービスのようなアプリケーションなら、リクエスト全体でのステータスコードやレスポンスタイムのみならず、処理の中で各サービス、関数がどう動作したのかというところまで記録、可視化して問題箇所の特定と解決を支援するようなことを目指します。Kubernetesなどのクラウドネイティブなアーキテクチャの導入でリリースが迅速化する一方でオートスケールやサービスの分割による複雑化が進んだ昨今、発生するトラブルにも迅速かつスマートに対処するべくオブザーバビリティの確保が求められてきている、というわけです。
さて、今回はKubernetesアプリケーションのモニタリングの話をします。そして次回は、オブザーバビリティを実現すべくアプリケーションにトレーシングを導入し、マイクロサービスの処理の流れを追いかけてみましょう。なお、詳細なモニタリングツールの導入や設定値の解説については最小限に留め、アプリケーション開発者として知っておくべき話題を中心に扱います。
Kubernetesメトリクスのモニタリング
まずは、Kubernetesでメトリクスを可視化するところから始めましょう。KubernetesにはPod、Nodeのメトリクスを取得するための標準の方法としてMetrics APIが定められています。Metrics APIはプラグインにより実装されるものなので、本連載のようにkubeadmを使用してクラスタを構築した場合は、そのままでは使えません。Metrics APIを利用するための最もメジャーな方法はMetrics Serverをクラスタにインストールすることです。Metrics Serverはkubeletを通してcontainerdなどのコンテナランタイムからメトリクスを取得し、kube-apiserverを通して取得できるようにします。
それでは、さっそくクラスタにインストールしてみましょう。今まで見てきたコンポーネント同様にコマンドひとつで完了します。
$ kubectl apply -f https://github.com/kubernetes-sigs/metrics-server/releases/latest/download/high-availability.yaml本来はこれで完了ですが、第2回のような手順でクラスタを構築している場合はもうひと手間必要です。metrics-serverはkubeletにアクセスしてmetricsを取得しますが、今回のようにkubeadmで構築したクラスタだと、そのままではkubeletの証明書エラーが発生します。kubeletの証明書を正しくkubernetesのCAで署名するように作り直すか、あるいは証明書エラーを無視するように設定します。今回は後者を採用します。
$ kubectl patch -n kube-system deployment/metrics-server --type='json' -p='[{"op": "add", "path": "/spec/template/spec/containers/0/args/-", "value": "--kubelet-preferred-address-types=InternalIP,ExternalIP,Hostname" },{"op": "add", "path": "/spec/template/spec/containers/0/args/-", "value": "--kubelet-insecure-tls" }]'インストールが完了するとMetrics APIが有効になります。実際にkubectl top コマンドを利用して、Node、PodのCPU使用率、メモリ使用量を表示できます。反映までに少し時間がかかります。
$ kubectl top node
NAME CPU(cores) CPU% MEMORY(bytes) MEMORY%
cocoa 371m 18% 2584Mi 67%
vanilla 128m 6% 2182Mi 56%
$ kubectl top pod -n sample-app
NAME CPU(cores) MEMORY(bytes)
accesscount-546568fbcb-882dd 1m 120Mi
accesscountdb-0 1m 21Mi
article-bd679456-7lkfs 1m 175Mi
articledb-0 1m 35Mi
rank-5c6485cb74-slsrx 1m 185Mi
rankdb-0 1m 35Mi
website-578dc78898-xntw5 1m 61Mikubernetes-dashboardなどのダッシュボードツールを利用すると、Metrics APIから取得したデータをWebUI上で可視化できます。また、このMetrics APIはKubernetesのオートスケールの仕組みであるHorizontal Pod AutoscalerやVertical Pod Autoscalerでも利用されます。Metrics Serverを導入することで、CPU利用率とメモリ使用量の2つのメトリクスを利用してPodをオートスケールできます。この連載ではこれ以上触れませんので、公式ドキュメントを参照してください。ちなみに、Metrics Server以外のプラグインを利用することで、より多くのメトリクスをMetrics APIで取得できます。実際にリクエスト数などアプリケーション固有のメトリクスでオートスケールするために、後述するPrometheusでMetrics APIを拡張することも多いです。

ただし、Metrics APIはあくまでPod、Nodeのメトリクスを取得するための仕組みです。PodをまたいだDeployment、Service単位でモニタリングする機能もなければ、アプリケーション固有のメトリクスをモニタリングするのにも適していません。Metrics APIはあくまでオートスケールのために利用し、運用のためのモニタリングには外部のモニタリングツールを並行して利用することをおすすめします。
Prometheusを利用した
メトリクスのモニタリング
では、アプリケーション固有のメトリクスをモニタリングするにはどうするべきでしょうか。非Kubernetesのシステムでも利用されていたモニタリングツール群の多くがKubernetesに対応しているので、引き続きこうしたツールを利用するのが良い方針です。ここでは、その中でも最もメジャーなPrometheusをKubernetesで使ってみたいと思います。ElasticsearchやDatadogなど、他の多くのツールもKubernetesで利用できますので、既に動かしているものがあれば調べてみてください。
実際に、Prometheusを利用したKubernetesのモニタリングを試してみましょう。Prometheus Server自体はKubernetesクラスタの内外で動作しますが、今回はHelmを利用してクラスタ内部に構築します。また簡単のため、persistentVolumeをオフにしてインストールしています。データが失われてしまうので実際に運用する場合はpersistentVolumeを用意しておきましょう。
$ kubectl create namespace monitoring
$ helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
$ helm repo add kube-state-metrics https://kubernetes.github.io/kube-state-metrics
$ helm repo update
$ helm install prometheus prometheus-community/prometheus -f - --namespace monitoring <<EOF
server:
persistentVolume:
enabled: false
alertmanager:
persistentVolume:
enabled: false
EOFPrometheusサーバが用意できたら、アプリケーションのメトリクスを公開しましょう。アプリケーションを修正し、Spring FrameworkとNuxt.jsのPrometheus Exporter Moduleを導入してイメージをビルドします。変更内容の詳細を見てみたいという方は、GitLab.comのコミットログを参照してください。
exporterが用意ができたら、Prometheus側でこれらのExporterからメトリクスを収集する設定が必要となります。PrometheusにはKubernetesクラスタのためのkubernetes_sd_configという設定値があるので、多くの場合ではこちらを利用すると便利です。この設定により、PodやServiceのAnnotationに特定の値を記述することで、Prometheusが自動的に値を収集してくれます。
# base/deployment-accesscount.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: accesscount
name: accesscount
spec:
template:
metadata:
annotations:
prometheus.io/scrape: 'true'
prometheus.io/path: '/actuator/prometheus'
prometheus.io/port: '8080'
...
# base/deployment-website.yaml
apiVersion: apps/v1
kind: Deployment
spec:
metadata:
labels:
app: website
name: website template:
metadata:
annotations:
prometheus.io/scrape: 'true'
prometheus.io/path: '/'
prometheus.io/port: '9091'
...
これらは、アプリケーション側でメトリクスを公開する設定でした。今度はPod、Nodeなど、Kubernetesリソース自体のメトリクスも見てみましょう。Metrics APIを利用したモニタリングはKubernetes固有の仕組みでPrometheusに直接対応するものではないため、PrometheusでPod、Nodeのメトリクスを収集するにはmetrics-serverではなく、別途exporterをインストールする必要があります。Nodeについてはnode-exporter、Podや他Kubernetesリソースについてはkube-state-metricsが最も広く利用されています。HelmでKubernetesクラスタにPrometheusをインストールした場合には、これらのexporterも同時にインストールされています。
$ kubectl -n monitoring get pod
NAME READY STATUS RESTARTS AGE
prometheus-alertmanager-7bbdfbf666-m5v9m 2/2 Running 0 44h
prometheus-kube-state-metrics-696cf79768-p98qw 1/1 Running 0 44h
prometheus-node-exporter-4jsnj 1/1 Running 0 44h
prometheus-node-exporter-7k8ts 1/1 Running 0 44h
prometheus-pushgateway-898d5bdb9-wr89g 1/1 Running 0 44h
prometheus-server-66f5858784-4b7rq 2/2 Running 0 44hこうして、アプリケーション固有のメトリクスとKubernetesリソースのメトリクスを同時にPrometheusで扱えるようになりました。特にオートスケールするようなアプリケーションの場合、Deploymentリソースのレプリカ数やPodのステータスなどはアプリケーションメトリクスと合わせて表示しておきたいところです。ということで、可視化ツールのGrafanaを利用してダッシュボードで表示してみましょう。図ではDeploymentリソースのレプリカ数、Podのコンディション、リクエストのDurationとガベージコレクションの所要時間を1枚のダッシュボードにサマリしています。ちなみに、このGrafanaもHelmでインストールできます。

Kubernetesのログモニタリング
メトリクスがモニタリングできるようになったところで、ログのモニタリングにも触れておきます。Kubernetesを含めて、コンテナアプリケーションではアプリケーションログの書き込み先をログファイルではなく、標準出力にするのがベストプラクティスです。Kubernetesでは、各コンテナの標準出力から出力されたログをAPIから閲覧できるようになっています。kubectl logs コマンドを実行して、実際に確認してみましょう。またtailコマンドのように、-f オプションで出力をリアルタイムに確認することもできます。
$ kubectl -n sample-app logs article-7c65b647b7-qjcjt
_ _ _ _
/ \ _ __| |_(_) ___| | ___
/ _ \ | '__| __| |/ __| |/ _ \
/ ___ \| | | |_| | (__| | __/
/_/ \_\_| \__|_|\___|_|\___|
sample1:: (v0.2.0-SNAPSHOT)
2021-09-28 05:39:34.467 INFO 6 --- [ main] c.c.k.s.article.ArticleApplication : Starting ArticleApplication v0.2.0-SNAPSHOT using Java 11.0.11 on article-7c65b647b7-qjcjt with PID 6 (/article/article.jar started by root in /article)
2021-09-28 05:39:34.473 DEBUG 6 --- [ main] c.c.k.s.article.ArticleApplication : Running with Spring Boot v2.4.2, Spring v5.3.3
2021-09-28 05:39:34.474 INFO 6 --- [ main] c.c.k.s.article.ArticleApplication : The following profiles are active: develop
2021-09-28 05:39:35.946 INFO 6 --- [ main] .s.d.r.c.RepositoryConfigurationDelegate : Bootstrapping Spring Data R2DBC repositories in DEFAULT mode.
2021-09-28 05:39:36.234 INFO 6 --- [ main] .s.d.r.c.RepositoryConfigurationDelegate : Finished Spring Data repository scanning in 281 ms. Found 1 R2DBC repository interfaces.
2021-09-28 05:39:38.569 INFO 6 --- [ main] o.s.b.a.e.web.EndpointLinksResolver : Exposing 1 endpoint(s) beneath base path '/actuator'
2021-09-28 05:39:38.963 INFO 6 --- [ main] o.s.b.web.embedded.netty.NettyWebServer : Netty started on port 8080
2021-09-28 05:39:38.993 INFO 6 --- [ main] c.c.k.s.article.ArticleApplication : Started ArticleApplication in 5.808 seconds (JVM running for 7.129)
2021-09-28 05:39:38.997 DEBUG 6 --- [ main] c.c.k.s.article.ArticleApplication : Article application started!
2021-09-28 06:10:55.071 DEBUG 6 --- [or-http-epoll-3] c.c.k.s.a.controller.ArticleController : access GET /api/articles/ dispatched
2021-09-28 06:11:01.653 DEBUG 6 --- [or-http-epoll-4] c.c.k.s.a.controller.ArticleController : access GET /api/articles/ dispatched
2021-09-28 07:49:49.729 DEBUG 6 --- [or-http-epoll-1] c.c.k.s.a.controller.ArticleController : access GET /api/articles/ dispatchedDeploymentリソースなどを利用して複数のPodを並列稼働している場合には、kubectl logs コマンドに --selector オプションを指定することで同一のラベルを持つPodのログをまとめて表示することができます。ただ少し見づらいので、sternのようなツールを利用するとPodごとに色分け表示してくれるので便利です。kubernetesのあらゆる操作は単なるkube-apiserverへのリクエストなので、こうした拡張ツールが盛んに開発されています。Krewは、こうしたkubectlコマンドのプラグインを管理する仕組みです。多くのプラグインが登録されているので、目を通しておくと使いたいものがあるかもしれません(*2021年10月現在、sternはKrewのレポジトリに登録されていません)。
$ stern -n sample-app accesscount
Lokiを利用したログモニタリング
ログにも非Kubenetesのシステムで利用されていたツール群を利用できます。代表的なログ収集ツールはfluentdやpromtail、logstash、ログサーバはElasticSearchやLoki、S3等のオブジェクトストレージなどがよく利用されます。先ほどはGrafanaを利用してメトリクスを可視化しましたので、同じくGrafana Labsが開発しているPromtailとLokiを利用してみましょう。
先ほどと同様にPromtail、LokiをHelmでデプロイします。Promtailの転送先がLokiになるように設定値を変更しています。PromtailはDaemonSetで各ノードに配置され、各コンテナが標準出力したログを自動で収集してくれるようになっています。ちなみに、各コンテナのログはノードの/var/log/pods/以下に書き込まれています。
$ helm repo add grafana https://grafana.github.io/helm-charts
$ helm repo update
$ helm install loki grafana/loki
$ helm install promtail grafana/promtail -f - <<EOF
config:
lokiAddress: http://loki:3100/loki/api/v1/push
EOFGrafanaのデータソースにLokiを設定すると、アプリケーションのログが表示できるようになっていますね。ログのラベルにはNamespaceやNode、PodのLabelが設定されています。図ではNamespaceを指定することで、アプリケーションのログに限定して表示しています。Podのラベルを適切に設定しておくことで、アプリケーション内の一部のサブシステムのみ抜き出してログを確認するなどの細かいフィルタリングがしやすくなります。
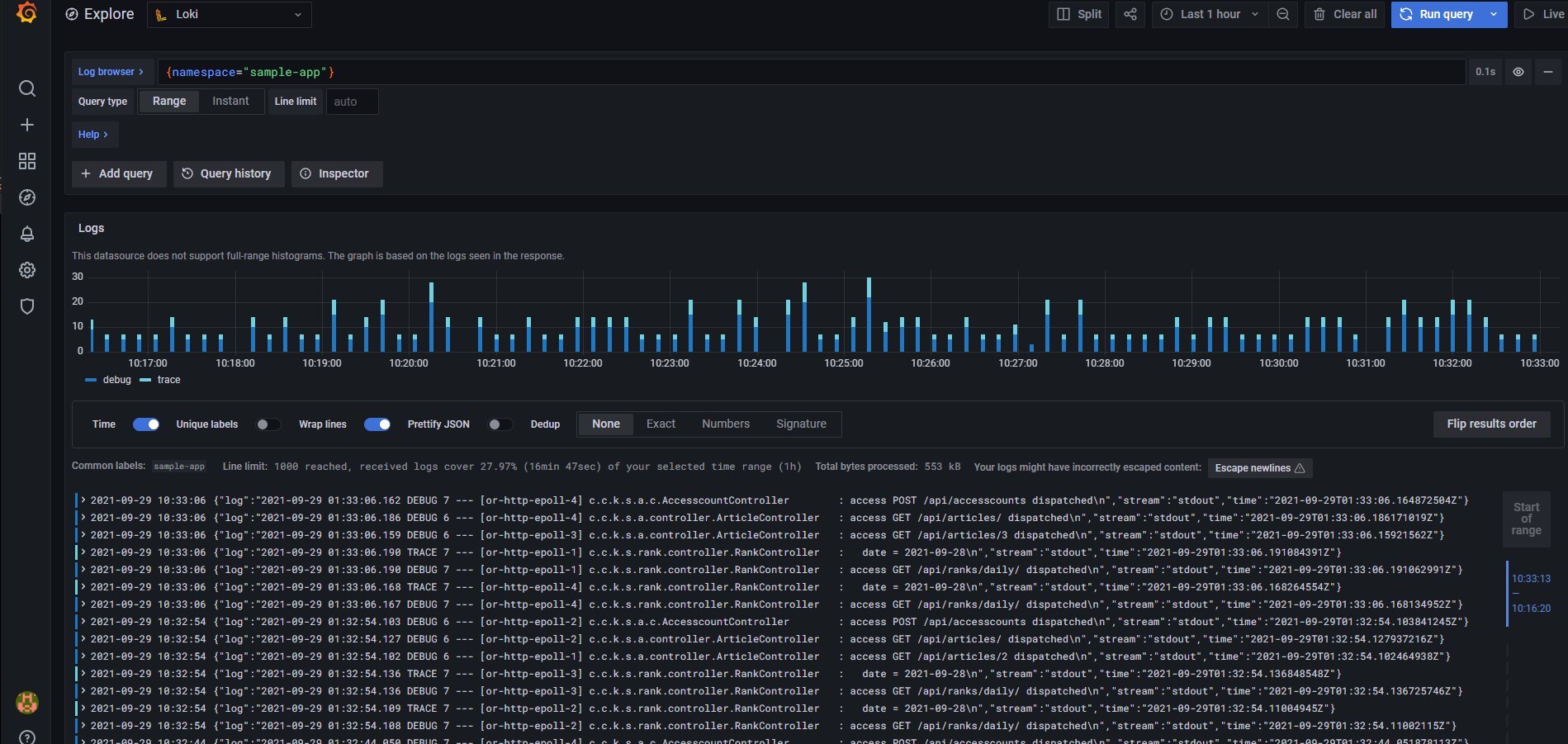
また、アプリケーションによっては、コンテナの標準出力ではなくファイルにログを書き込むものがあります。その場合は、同一Podのサイドカーコンテナとしてpromtailを動かしてLokiにログを転送するようにPodを構成しましょう。コンテナ間でVolumeを共有することで、アプリケーションコンテナが書き込んだログをpromtailコンテナで読み出して転送できます。マニフェストファイルのサンプルを抜粋して載せておきます。
apiVersion: apps/v1
kind: Deployment
spec:
template:
spec:
volumes:
- name: logs
containers:
- name: promtail-container
image: grafana/promtail
volumeMounts:
- name: logs
mountPath: /var/log/app
- name: main-container
image: main-image
volumeMounts:
- name: logs
mountPath: /var/log/appおわりに
今回は、Kubernetes環境でのアプリケーションのモニタリングについて解説しました。非Kubernetesのアプリケーション同様に、メトリクスとログがモニタリングできることをお分かりいただけたかと思います。次回は、モニタリングから一歩進んだオブザーバビリティについて、実例をお見せしながら紹介します。お楽しみに。
- この記事のキーワード
関連記事
Kubernetesの基礎
2018年3月14日 6:00
kustomizeやSecretを利用してJavaアプリケーションをデプロイする
2021年5月20日 7:38
Kubernetesアプリケーションのトレーシング
2021年11月25日 6:30
Kubernetes環境を構築して、実際にコンテナを動かしてみよう
2021年3月19日 6:35
Oracle Cloud Hangout Cafe Season5 #3「Kubernetes のセキュリティ」(2022年3月9日開催)
2023年4月18日 6:30
Kubernetesアプリケーションの快適リリースとGitOps
2021年8月20日 6:51
バックナンバー
この記事の筆者

筆者の人気記事
Kubernetes上のコンテナをIngressでインターネットに公開するまで
2021年4月16日 7:15
今からでも遅くない! Kubernetesを最速で学ぶための学習法とは
2021年2月12日 15:37
kustomizeで復数環境のマニフェストファイルを簡単整理
2021年6月18日 7:34
Kubernetesアプリケーションのモニタリングことはじめ
2021年10月22日 6:30
Visual StudioでXamarin+Realmアプリの開発環境をセットアップ
2022年2月15日 6:30
Kubernetesアプリケーションの快適リリースとGitOps
2021年8月20日 6:51
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
