Observability Conference 2022開催、Kubernetesにおける観測の基本を解説
Observability Conference 2022から、Kubernetesにおける観測の基本をGrafana Labsのソフトウェアを中心に解説したセッションを紹介。
2022年4月21日 6:00
コンピュータシステムの動きを可視化するためのツールやユースケースに関するオンラインカンファレンス、Observability Conference 2022が2022年3月11日に開催された。Think ITでは、このカンファレンスのセッションをシリーズとして紹介する。初回はYahoo! Japanのクラウドテクノロジーを支えるゼットラボ株式会社のエンジニアによる「Kubernetes Observability入門」というセッションを紹介する。

セッションタイトルは「Kubernetes Observability入門」
セッションを担当したのは吉村翔太氏。ゼットラボでYahoo! Japanが利用するKubernetes-as-a-Serviceの開発に従事しているという。

セッションを行った吉村氏の自己紹介
このセッションでは「KubernetesのObservabilityとは何か?」を理解し、そのために5つの主要な要素について解説することをゴールとしている。5つの要素とはMetrics、Logs、Traces、ProfilesそしてDumpsだ。

このセッションのゴールを説明
ここからCNCFによるObservabilityの定義、ホワイトペーパーなどの紹介から、Observabilityが近年注目されてきた傾向に対して、実際には1960年代から制御工学の一部として研究されてきたことを紹介し、「制御」と「観測」は機械や設備を効果的に運用するための必須の考え方であることを解説した。
ここではエアコンを例に挙げ、20℃に設定したら20℃の温風を出し続けるタイプと、20℃に設定したら室温を観測して室温を20℃に保つように運転するタイプがあることを紹介した。
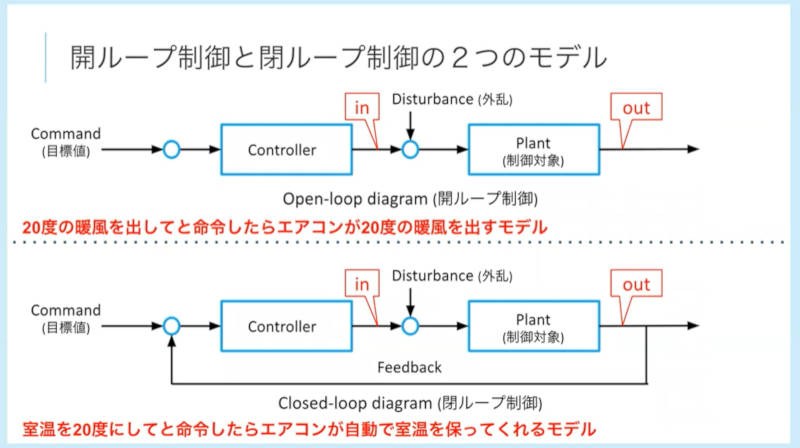
閉ループと開ループによる制御モデルの解説
ここでざっくりと観測(Observe)することで必要とする制御(Control)が実現できるという基本を解説した上で、これをKubernetesに置き換えて解説している。

ここではPodの数を制御するためにCPU使用率を使う例を説明
ただこのスライドで「観測可能であること(Observability)は制御可能であること(Controllability)の必須要件」と説明しているが、これでは具体的に何をどうするのかは理解できないだろうとして、ここからは具体的にKubernetesとそのエコシステムに属するソフトウェアを使って「KubernetesにおいてObservabilityを実装する」具体例を解説するフェーズとなった。

Observability Signalsの紹介
ここで5つのObservabilityのための要素、Metrics、Logs、Traces、Profiles、Dumpsをざっくりと説明した。特にMetrics、Logs、Tracesについては主要なシグナルとして、2019年頃は3つの柱として紹介されてきたが、今は主要なシグナル(Primary Signals)と呼ばれているという。この3つが必ずしも必須というわけではなく、用途においては1つだけを使う場合もあり得ると説明した。またシグナル自体も今後追加される可能性についてもコメントを行った。

Primary Signalsとは
最初に説明したのはメトリクス(Metrics)で、この例ではPrometheusを使ってKubernetes上のPodで実行されるアプリケーション、Kubernetes自体の状況を確認するためのControl Plane、Kubeletなどが出力するメトリクスデータを使って観測を行う例を示した。
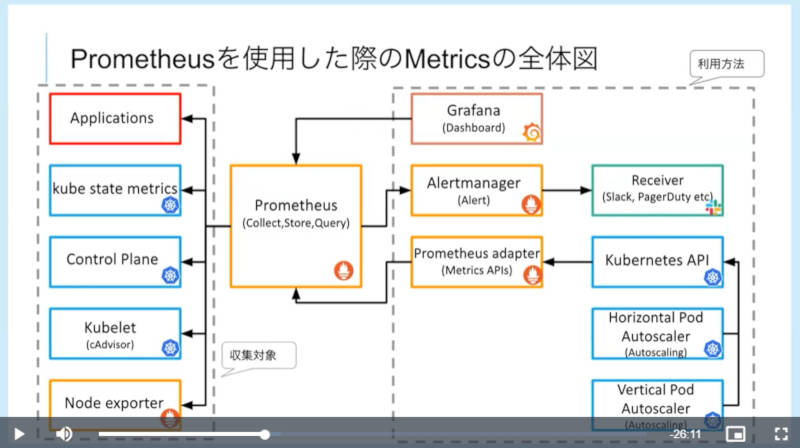
Prometheusを使ったメトリクス収集と利用の構成例
ここではKubernetesにPrometheusを使ったメトリクス収集と利用の概要を解説。単にダッシュボードであるGrafanaから監視するだけではなく、メトリクスの値を使ってオートスケーリングなどにも応用できるという例を示した。
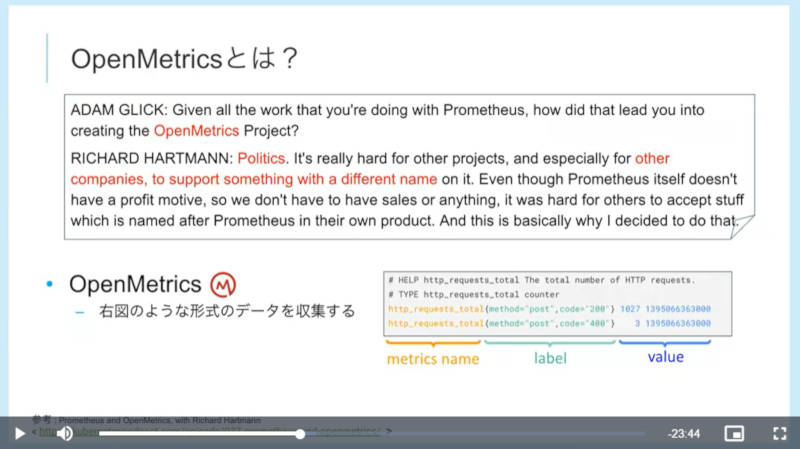
OpenMetricsの説明
ここでPrometheusに説明が及んだ流れから、Prometheusから派生したOpenMetricsについても簡単に紹介を行った。このスライドではOpenMetricsを作った理由について、Prometheusという名前が付いていると他の企業による利用やサポートが難しくなることが主な理由であるとして、OpenMetricsというプロジェクトの成立は多分に政治的な理由であることが書かれている。ちなみにここで引用されているRichard Hartmann氏は、Grafana Labのコミュニティディレクターだ。ただしセッションの解説としてはデータ形式について触れただけだったのは興味深い。
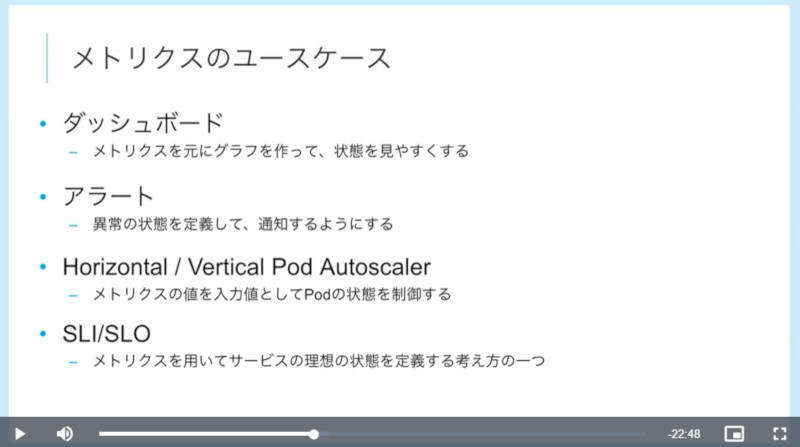
メトリクスのユースケースを紹介
次に紹介したのはログだ。ここではGrafana Lokiをログのバックエンドとして使った例を紹介した。
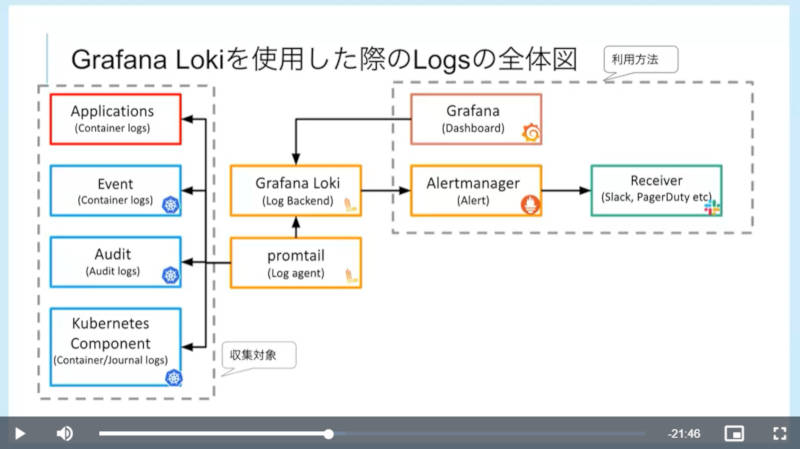
Grafana Lokiを使ったログ収集の構成例
ここからKubernetesにおけるログの解説、ログ収集の3つの方式、主なログの種類などについて説明を行った。
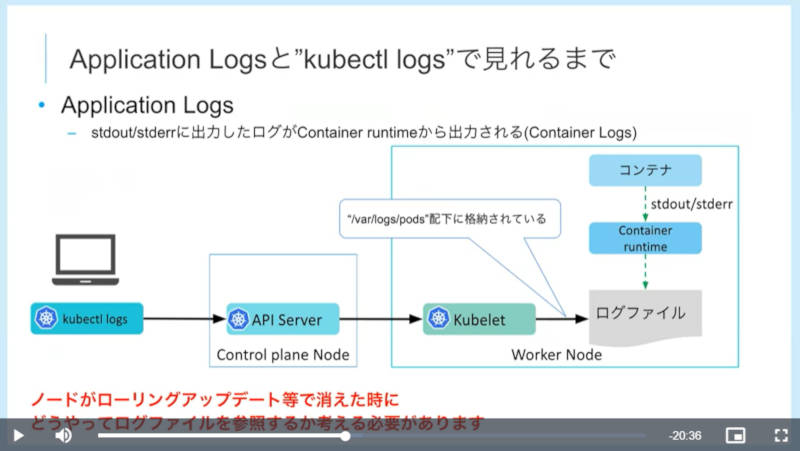
Kubernetes上のコンテナが出すログの解説
またDockershimがKubernetesから廃止されるという状況を踏まえて、DockerとContainerdにおけるログの違いなどについても解説を行った。
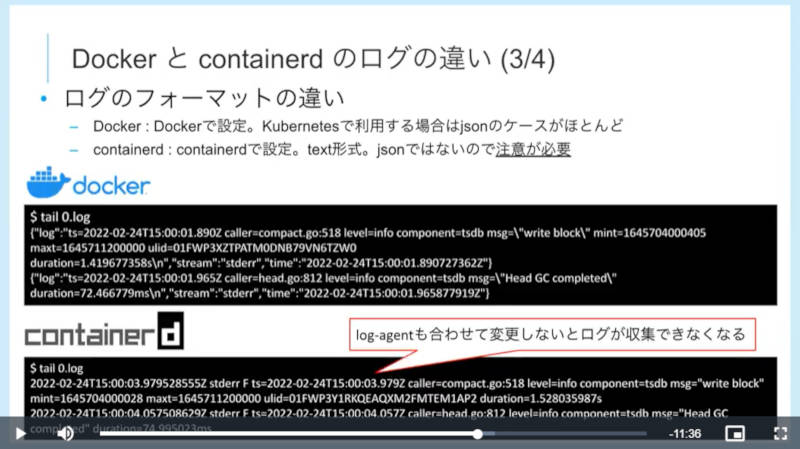
DockerとContainerdのログフォーマットの違いを説明
構成例では主にPrometheusやGrafana Labsが開発しているソフトウェアが使われている。実際のログの利用という意味ではトレジャーデータが開発をリードするFluentdや、Elasticが開発するElasticsearch、Kibana、Logstashを使うELK Stackが有名だが、ここでは割愛されている。
Grafana LokiとFluentdの比較については以下の記事が参考になるだろう。
参考:Loki compared to other log systems
またいわゆるELK Stack(Erasticsearch+Logstash+Kibana)、つまりElasticとGrafana Labsの違いについては、以下のブログを参考にされたい。
参考:Grafana vs. Kibana | What are the differences?
またログのひとつであるEvet Logsについては、VMwareが買収したHeptioが公開しているEventrouterを紹介した。
Eventrouter公式GitHub:https://github.com/vmware-archive/eventrouter
3つ目のシグナルであるトレーシングについては、OpenTelemetryを使った構成例を紹介した。
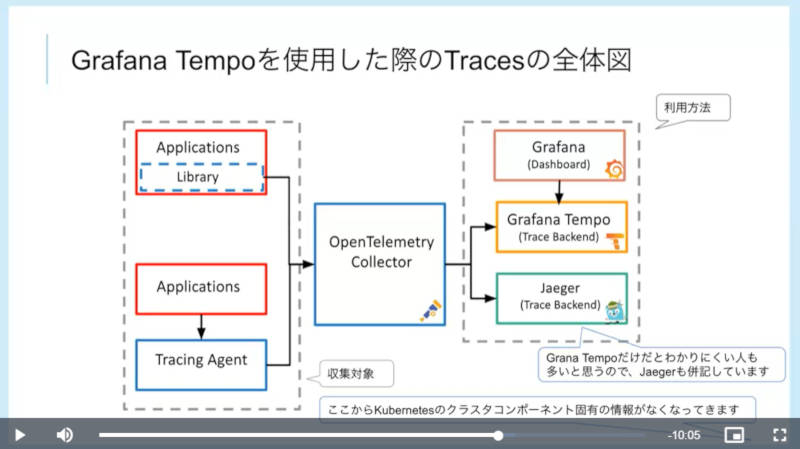
OpenTelemetryを使った構成例
Kubernetes環境下では分散トレーシングを考慮する必要があるとして、複数のPodが連携して稼働する場合にユニークなトレースIDを付与して複数のPodを追跡する必要があることを説明した。
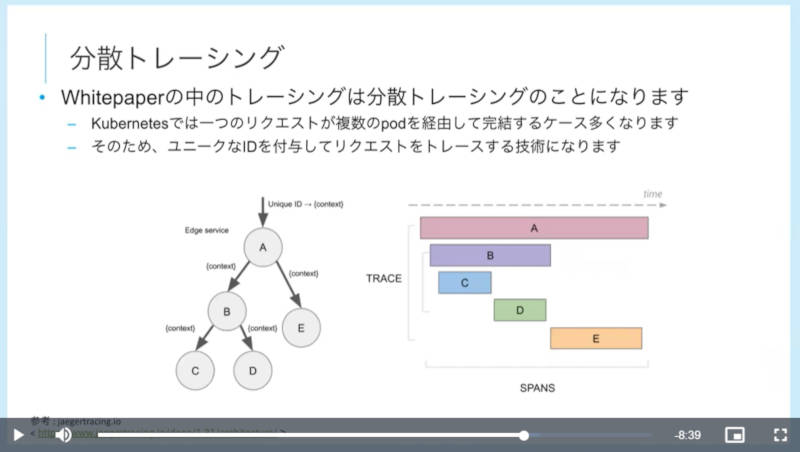
分散トレーシングの説明
ここでOpenTelemetryについても簡単に紹介。元々はOpenCensusとOpenTracingという別々のプロジェクトをマージしたものがOpenTelemetryだ。OpenTelemetryについては2021年3月の記事を参照されたい。単にトレーシングのためのプラットフォームから、ログやメトリクスまでを包含する包括的なプラットフォームを目指していると語ったが、実際にどれくらい実現されているのかについては別のセッションに譲るとして詳しい説明は行われなかった。
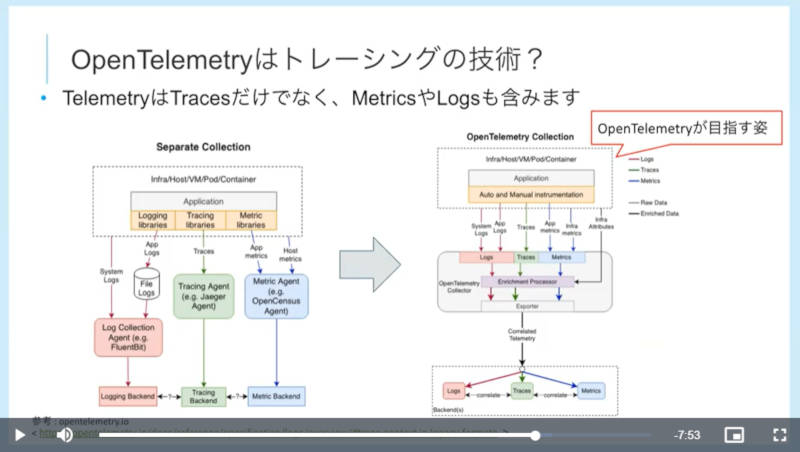
OpenTelemetryの目指す姿を紹介
OpenTelemetryの状況(2021年3月時点):ベンダーニュートラルな可視化ツールOpenTelemetryの最新情報を紹介
ここからProfiles及びDumpsについては、Kubernetes固有の技術でなくLinuxの基本的なテクノロジーをそのまま応用することになると解説した。
実際にこれまでのシグナルを使って運用する場合のフローについても解説を行い、エラーなどのアラートメッセージから始まってダッシュボードでの確認、必要な情報を獲得するためのクエリーなどを行った上でログの確認、分散トレーシングによって原因の特定を行い、最終的に不具合を修正するという流れを説明した。
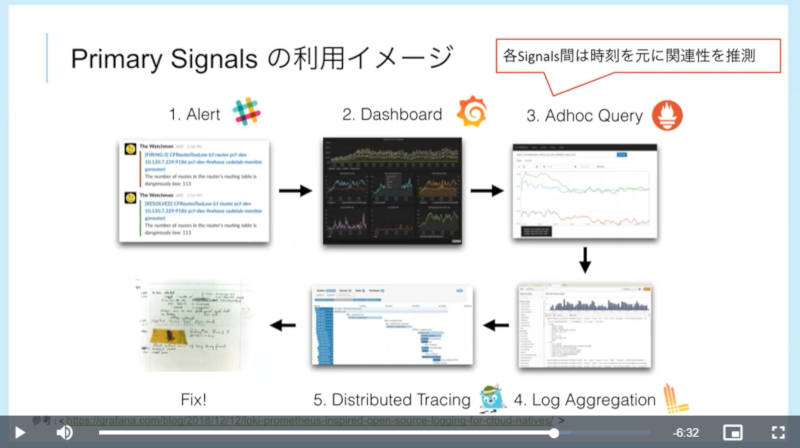
Observabilityのための一連の流れを紹介
このセッションではKubernetesにおける観測性(Observability)について一通りの解説を行ったことになるが、実際に観測性を実装するためのソフトウェア、企業はCNCFのランドスケープに数多く存在している。
参考:CNCF Cloud Native Interactive Landscape
数ある中の一例としてGrafana Labsが関わっているソフトウェアを中心に紹介を行ったというのが、今回のセッションだろう。New RelicやDatadogなど商用サービスを提供している企業も多く存在する領域であることから、今後の状況について注目するには上記のランドスケープも参考にされたい。
この記事をシェアしてください
関連記事
Obervability Conference 2022、OpenTelemetryの概要をGoogleのアドボケイトが解説
2022年5月24日 6:00
Observability Conference 2022、Splunkのエンジニアが説明するOpenTelemetryの入門編
2022年6月15日 6:00
Observability Conference 2022、日本ユニシスのエンジニアが解説するデベロッパーにとってのオブザーバビリティ
2022年6月2日 6:00
3/11「Observability Conference 2022」開催せまる! 実行委員オススメのみどころを紹介
2022年3月4日 12:34
Observability Conference 2022、TVerによるNew Relic One導入事例を紹介
2022年7月6日 6:00
GrafanaCON 2025から、スキポール空港のキオスク端末のオブザーバビリティを解説したセッションを紹介
2025年8月4日 6:01
バックナンバー
この記事の筆者

筆者の人気記事
SASEのCato Networks、CEOによるセミナーとインタビューを紹介
2020年4月16日 6:00
Rustのエコシステムの拡がりを感じるデスクトップアプリのためのツールキットTauriを紹介
2022年12月16日 6:00
Zabbix式オープンソースの秘密に迫る
2025年1月31日 6:00
WebAssemblyとRustが作るサーバーレスの未来
2020年4月21日 6:00
三菱電機が設立したOSPOのメンバーにインタビュー。「インナーソース」を戦略的に使う背景とは?
2025年10月3日 6:00
エンタープライズLinuxを目指すSUSE、Red Hatとの違いを強調
2015年2月3日 19:00
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
