クラスタおよびノードの運用・監視について
クラスタおよびノードの運用・監視について
Cassandraクラスタを構成して利用する際に必要となる、オペレーションのコマンドを紹介します。
利用環境例
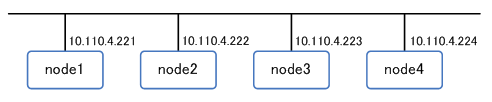
コマンドの実行例を紹介するため、バージョン0.6.1を使用して、以下のような4ノード構成のCassandraクラスタを構築しています。
|
|
| 図9: クラスタ構成 |
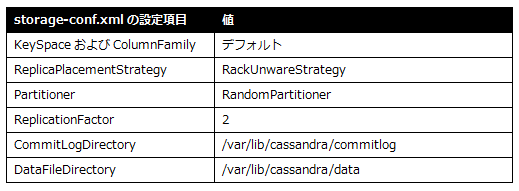
各ノードの設定は、図10のようになっています(図に記載されていない設定はすべてデフォルト値)。
|
|
| 図10: クラスタ構成 |
クラスタおよびノードの管理コマンド
Cassandraにおける、クラスタやノードの操作、状態の確認などには、nodetoolコマンドとcrustertoolコマンドを使用します。
コマンドの書式は、
nodetool もしくは crustertool -h -p サブコマンド
となります。
クラスタの確認
接続されているノードの一覧と現在の状態を確認する場合は、nodetool ringコマンドを使用します。
<code>
<span style="font-size: 12px;">
# bin/nodetool -h 10.110.4.221 ring
Address Status Load Range Ring
137038178554849158017053582131615885699
10.110.4.223 Up 23.49 MB 95059186747344716726005247331391356656 |<--|
10.110.4.221 Up 32.55 MB 115527929609126303064539078030967411505 | |
10.110.4.224 Up 11.3 MB 126347406049707412975602958107717352863 | |
10.110.4.222 Up 18.59 MB 137038178554849158017053582131615885699 |-->|
</span>
</code>
ノードがダウンしている場合は、StatusにDownと表示されますが、Downした情報が伝播するまでに多少時間がかかる場合があります。
<code>
<span style="font-size: 12px;">
# bin/nodetool -h 10.110.4.224 ring
Address Status Load Range Ring
126347406049707412975602958107717352863
10.110.4.222 Up 34.72 MB 25200789318114567458232456293497692552 |<--|
10.110.4.223 Down 39.89 MB 95059186747344716726005247331391356656 | |
10.110.4.221 Up 24.57 MB 115527929609126303064539078030967411505 | |
10.110.4.224 Up 7.88 MB 126347406049707412975602958107717352863 |-->|
</span>
</code>
ノードの追加
Cassandraでは、ノードの新規追加をBootstrappingと呼んでいます。
追加を行うノードの設定ファイルの1つ、strage-conf.xml内にあるAutoBootstrapの値をTrueに変更して起動することで、新規登録の処理が行われます。
ノードの削除
ノードの削除には、nodetool decommissionコマンドを使用します。
<code>
<span style="font-size: 12px;">
# bin/nodetool -h 10.110.4.222 decommission
***削除までに時間がかかります***
# bin/nodetool -h 10.110.4.221 ring
Address Status Load Range Ring
126347406049707412975602958107717352863
10.110.4.223 Up 39.89 MB 95059186747344716726005247331391356656 |<--|
10.110.4.221 Up 24.57 MB 115527929609126303064539078030967411505 | |
10.110.4.224 Up 7.88 MB 126347406049707412975602958107717352863 |-->|
</span>
</code>
コマンドを実行すると、それまで担当していたレンジが、削除されるノードからほかのノードに割り当てられ、データのレプリケーションが行われます。
破棄されたノードに保存されているデータは、自動では削除されません。このため、ほかの異なるトークン・リングにノードを再配置する場合には、以前の情報を手動で削除する必要があります。
バックアップとリストア
Cassandraでは、nodetool snapshotコマンドを使用して、保存されているデータのsnapshot(スナップ・ショット)を取得することができます。
しかし、snapshotコマンドは、SSTableに書き込まれたデータしか取得できません。このため、snapshotの取得前にnodetool flushコマンドを使用し、memtableに登録されているデータをSSTableに書き込む必要があります。
<code> <span style="font-size: 12px;"> # bin/nodetool -h 10.110.4.224 flush Keyspace1 # bin/nodetool -h 10.110.4.221 snapshot 20100527 # ls /var/lib/cassandra/data/Keyspace1/snapshots/1274924116249-20100527 Standard1-18-Data.db Standard1-18-Index.db Standard1-19-Filter.db .... </span> </code>
snapshotからデータを復旧する場合は、ノードを停止してcommitlogとSSTableのデータを削除した後、snapshotが格納されているディレクトリからファイルをコピーします。
nodetoolでは、ノードごとにsnapshotを取得する必要があるため、ノードが増えると作業量が大幅に増加します。これへの対策として、Cassandraでは、clustertoolというコマンドを用意しています。このコマンドを使えば、全ノードのsnapshotを取得できます。
<code> <span style="font-size: 12px;"> # bin/clustertool -h 10.110.4.224 global_snapshot 20100527 10.110.4.224 snapshot taken 10.110.4.223 snapshot taken 10.110.4.222 snapshot taken 10.110.4.221 snapshot taken </span> </code>
ノード情報の取得
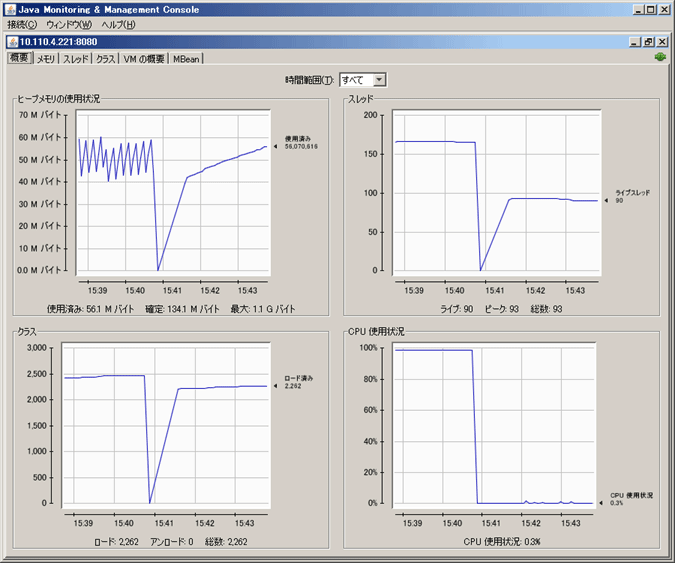
Cassandraは、JMX (Java Management eXtensions)を使用してパフォーマンスやリソースの消費情報を提供しています。このため、JconsoleやOpenNMSといった運用監視ツールを使った監視が可能です。
|
|
| 図11: Jconsoleを使用した情報の取得(クリックで拡大) |
また、nodetoolコマンドにも、KeyspaceごとのRead/Writeレイテンシなどを確認できるcfstatsオプションや、Thread Poolの現在の状態を表示するtpstatsオプションが用意されています。
<code>
<span style="font-size: 12px;">
# bin/nodetool -h 10.110.4.221 cfstats
Keyspace: Keyspace1
Read Count: 10257
Read Latency: 0.5517311104611484 ms.
Write Count: 10250
Write Latency: 0.047163707317073165 ms.
Pending Tasks: 0
Column Family: Standard1
SSTable count: 2
Space used (live): 8721703
........
Compacted row mean size: 368
# bin/nodetool -h 10.110.4.221 tpstats
Pool Name Active Pending Completed
STREAM-STAGE 0 0 0
RESPONSE-STAGE 0 0 6963
ROW-READ-STAGE 0 0 10257
....
HINTED-HANDOFF-POOL 0 0 9
</span>
</code>
まとめ
本記事では、Apache Cassandraの特徴とアーキテクチャの概要を示すとともに、クラスタとノードの運用管理に役立つツールを紹介しました。
結果整合性モデルの採用やマスター・ノードが存在しないアーキテクチャなど、クライアント・アプリケーション側で考慮しなければいけない部分が多いですが、スケールしやすい特性や耐障害性の高さなどは、大量のデータを処理するアプリケーションにとって非常に魅力的な機能だと思います。
今後は、RDBMS(リレーショナル・データベース管理システム)の一部の処理を受け持ち、RDBMSの負荷を軽減するような形での利用が広がると考えられます。RDBMSとの違いを把握しつつ、使い分けていく必要があります。
- この記事のキーワード
バックナンバー
この記事の筆者

Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
