クラウドの力を引き出す分散データベース
はじめに本記事では、プライベート・クラウドなどで実際に利用可能な分散型データベースの一例として、Apache Cassandraを紹介します。機能的な特徴やアーキテクチャの概要だけでなく、運用する上で必要となるクラスタとノードの操作方法(ノードの追加/削除、バックアップなど)についても説明します。A
2010年6月17日 20:00
はじめに
本記事では、プライベート・クラウドなどで実際に利用可能な分散型データベースの一例として、Apache Cassandraを紹介します。
機能的な特徴やアーキテクチャの概要だけでなく、運用する上で必要となるクラスタとノードの操作方法(ノードの追加/削除、バックアップなど)についても説明します。
Apache Cassandraは、Amazon Dynamoと Google BigTableの特徴を統合した分散型データベースと言われています。クラウド向け分散データベースの事例を参照していただければ、より特徴を理解しやすくなると思います。
Apache Cassandraとは
Apache Cassandraは、Amazon Dynamoの特徴である“耐障害性の高さやデータの分散保持を考慮した分散特性”と、 Google BigTableの特徴である“ColumnFamilyをベースとしたリッチ・データ・モデルや柔軟性の高さ”などを統合した、第2世代の分散型データベースです。
もともとは米Facebookが自社開発した技術であり、2008年にオープン・ソース化され、2009年にApache Software Foundation(ASF)に寄贈されました。
現在では、Apacheのトップ・レベル・プロジェクト(http://cassandra.apache.org/)として、Apacheのコミッタや、さまざまな企業から参加しているコントリビュータによって、開発が進められています。
2010年6月現在のバージョンは0.6.1です。すでに、米Facebook、米Digg、米Twitter、米Rackspace Hostingなど、大量のデータを扱っている多くの企業で使われています。最大規模の商用クラスタでは、150台以上のノードで100TB(テラバイト)以上のデータを扱っています。
Cassandraの特徴
Cassandraは、Amazon DynamoとGoogle BigTableから、以下のような機能を引き継いでいます。
|
| 図1: Apache Cassandraの特徴 |
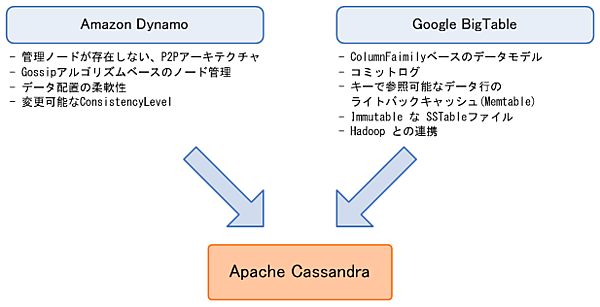
こうした背景があり、Cassandraは、以下の特徴を持っています。
- 耐障害性
- 耐障害性を高めるため、データは自動的に複数のノードへとレプリケーションされます。異なるデータ・センターをまたいだレプリケーションもサポートしています。
サービスの提供が不可能となったノードは、システムを停止することなく入れ替えることができます。 - 分散特性
- クラスタ上の全ノードが同一の扱いとなっており、管理ノードが必要ありません。このため、ネットワークのボトルネックやSPOF(Single Point Of Failure)が存在しません。
- 一貫性
- 可用性を確保するため、結果整合性(Eventual Consistency)モデルを採用しています。
結果整合性モデルは、誰かがデータを更新し、更新データが複製されるのに十分な時間が過ぎた後、更新が行われていなければ、必ず最新のデータにアクセスできる、というモデルです。 - リッチ・データ・モデル
- Key/Valueのデータだけでなく、カラム型のデータ構造を持っています。これにより、単純なKVS(Key Value Store)では実現できない、複雑なデータを管理できます。
- 高可用性、柔軟性
- Read/Writeスループットは、新しいノードを追加することで線形(リニア)に増加します。
ノードの追加・削除の際に、システム停止やクライアント・アプリケーションへの割り込みは発生しません。
また、Read/Write処理は、書き込みを保障しない(とりあえず書き込んだ)レベルから、書き込みが保障されている(全レプリカ・データが読み込み可能な状態になった)レベルの間で、Consistency Level(整合性レベル)を設定できます。
- この記事のキーワード
この記事をシェアしてください
関連記事
バックナンバー
この記事の筆者

Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
