MySQL Clusterにおけるレプリケーション環境構築例
MySQL Clusterにおけるレプリケーション環境構築の具体例について解説します。
2015年11月19日 7:00
本連載では、実際に「MySQL Cluster」を利用するためのチュートリアルとなるように、その特徴と基本的なアーキテクチャからインストール方法、基本的な操作などをコマンド付きで解説していきます。第8回の今回は、MySQL Clusterにおけるレプリケーション環境構築の具体例について解説します。
前提となる環境
記事中のコマンド例は、第2回でインストールした環境に第5回で紹介したサンプルデータベース(worldデータベース)を作成した状態を前提としています(追加設定としてmysqlユーザーの環境変数"PATH"に"/home/mysql/mysqlc/bin"も追加した状態を前提)。
レプリケーション環境構築の流れ
レプリケーション環境の構築は、以下の手順で行います。大まかな流れは通常のMySQL Serverでレプリケーション環境を構築する手順と同様ですが、手順6、7はMySQL Cluster固有の手順です。また、バックアップの取得/リストア方法などはMySQL Cluster用の手順で実施する必要があります。
【レプリケーション環境の構築手順】
- マスター/スレーブのMySQL Clusterをセットアップする
- マスター/スレーブにレプリケーション用の設定を行う
- マスター上にレプリケーション用のユーザーを作成する
- マスターでオンラインバックアップを取得する
- スレーブへデータをリストアする
- スレーブのndb_apply_statusteテーブルからスレーブに反映済みのEpochを確認する
- マスターのndb_binlog_indexテーブルからマスターのバイナリログ情報を確認する
- レプリケーションの設定を行う(CHANGE MASTER TOコマンドを実行)
- レプリケーションを開始する(START SLAVEを実行)
マスターとスレーブを新規でセットアップした直後にレプリケーションを構成する場合は、マスターにまだデータが入っておらず、バイナリログも記録されていないため、上記手順の4~7を省略できます。
今回はndb_apply_status、ndb_binlog_indexの確認方法を解説するため、マスターにデータが入っている状態からレプリケーション環境を構築していきます。
レプリケーション環境構築の具体例
構築する環境の説明
今回はチュートリアル目的のため、1台のサーバー内に2組のMySQL Cluster環境を構築してレプリケーションを構成します。構築済みのMySQL Cluster環境(冒頭の「前提となる環境」を参照)をマスターとし、追加で図1の構成でMySQL Cluster環境を構築してスレーブとします。
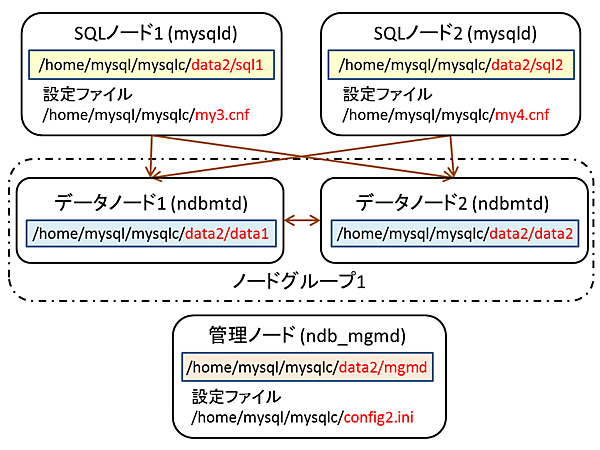
図1: スレーブのMySQL Cluster環境
それぞれの環境の配置ディレクトリ、設定ファイル名、ポート番号などを表1に示します。マスターとスレーブでノードIDが重複していますが、管理ノードが異なるため問題はありません(ノードIDをconfig.iniで指定しなかった場合はそれぞれのMySQL Clusterに自動採番で割り当てられるため、マスターとスレーブで重複する)。
表1: レプリケーションを構成するMySQL Cluster環境一覧
| 役割 | 種類 | 配置ディレクトリ /home/mysql/mysqlc配下 | 設定ファイル | ポート番号 | ノードID | server_id |
|---|---|---|---|---|---|---|
| マスター | 管理ノード | data/mgmd | config.ini | 1186 | 1 | - |
| マスター | データノード1 | data/data1 | config.ini | - | 2 | - |
| マスター | データノード2 | data/data2 | config.ini | - | 3 | - |
| マスター | SQLノード1 | data/sql1 | my1.cnf | 3306 | 4 | 1 |
| マスター | SQLノード2 | data/sql2 | my2.cnf | 3307 | 5 | 2 |
| スレーブ | 管理ノード | data2/mgmd | config2.ini | 1187 | 1 | - |
| スレーブ | データノード1 | data2/data1 | config2.ini | - | 2 | - |
| スレーブ | データノード2 | data2/data2 | config2.ini | - | 3 | - |
| スレーブ | SQLノード1 | data2/sql1 | my3.cnf | 3308 | 4 | 3 |
| スレーブ | SQLノード2 | data2/sql2 | my4.cnf | 3309 | 5 | 4 |
レプリケーション環境構築手順
1. マスター/スレーブのMySQL Clusterをセットアップする
マスターは構築済みのため、追加でスレーブのMySQL Clusterをセットアップします。第2回を参考に、図1の構成でMySQL Clusterをセットアップしてください。なお、以下のパラメータはそれぞれの環境に応じて変更する必要があります。
config.ini
- DataDir ※[ndb_mgmd]セクション、[ndbd]セクションに存在
- PortNumber ※[ndb_mgmd]セクションに存在(config2.iniに追記)
my.cnf
参考情報として、スレーブのconfig.iniおよびスレーブのmy.cnf(SQLノード1用)をそれぞれリスト1、2に示します。マスター用のconfig.iniではポート番号を明示的に指定せずにデフォルトのポート番号(1186)を使用していましたが、スレーブ用のconfig.iniでは重複を避けるため明示的にポート番号を指定する必要があります。そのため、リスト1では[ndb_mgmd]セクションにPortNumberの設定を追記しています。
リスト1・手順1:スレーブ用のconfig.ini(config2.ini)の内容
#管理ノードの設定項目 [ndb_mgmd] DataDir = /home/mysql/mysqlc/data2/mgmd/ HostName = localhost PortNumber = 1187 #データノード共通の設定項目 [ndbd default] #データの多重化の数 2-4が指定可能 NoOfReplicas = 2 #各データノードの個別設定項目 [ndbd] DataDir = /home/mysql/mysqlc/data2/data1/ [ndbd] DataDir = /home/mysql/mysqlc/data2/data2/ #各SQLノードの個別設定項目 [mysqld] [mysqld]
リスト2・手順1:スレーブ用のmy.cnf(my3.cnf)の内容
#SQLノードの設定項目 [mysqld] ndbcluster ndb-connectstring = localhost:1187 #1つのOS上で複数のSQLノードを起動するための設定項目 #別のSQLノードではそれぞれの値を変更する server_id = 3 datadir = /home/mysql/mysqlc/data2/sql1/ port = 3308 socket = /tmp/mysql3.sock #/usr/local/mysql以外にプログラムを展開した際に必要な設定 #通常のMySQLサーバーでも同様 basedir = /home/mysql/mysqlc
2. マスター/スレーブにレプリケーション用の設定を行う
レプリケーション用のバイナリログを出力するため、マスター/スレーブのSQLノードにリスト3を設定します(my1.cnf~my4.cnfにそれぞれ追記)。第7回で解説したように、混乱を避けるためにbinlog_format=ROWも明示的に設定しています。
リスト3・手順2:my.cnfへの追記内容
#レプリケーション用の設定 log-bin=binlog binlog_format=ROW
3. マスター上にレプリケーション用のユーザーを作成する
スレーブがマスターへログインするためのレプリケーション用ユーザーを作成します。マスターのSQLノードへ接続し、リスト4のSQLを実行します。この例ではレプリケーション用のユーザー名を’repl’、パスワードを’repl’としていますが、任意で変更可能です。
リスト4・手順3:レプリケーション用のユーザー作成SQL
$ # マスターのSQLノードに接続して実行 mysql> GRANT REPLICATION SLAVE ON *.* TO 'repl'@'localhost' IDENTIFIED BY 'repl';
4. マスターでオンラインバックアップを取得する
マスターでSTART BACKUPコマンドを実行し、オンラインバックアップを取得します。オンラインバックアップ取得方法の詳細は、第5回を参照してください。
5. スレーブへデータをリストアする
手順4で取得したバックアップをスレーブへリストアします。データのリストアはndb_restoreコマンドで行いますが、この方法ではSQLノードが保持するスキーマ(データベース)の情報はリストアされません。そのため、事前にスレーブのSQLノードに接続してリスト5のSQLを実行し、マスターに存在していたworldデータベースを作成しておきます。
リスト5・手順5:worldデータベースの作成(スレーブ側に作成)
$ # スレーブのSQLノードに接続して実行 mysql> CREATE DATABASE world;
その後、スレーブでndb_restoreコマンドを実行してデータをリストアします。なお、スレーブで実行するため-cオプションの指定はリスト6のように「localhost:1187」になることに注意してください。また、ndb_restoreコマンドの使用方法の詳細は第5回を参照してください。リスト6ではバックアップID 3を指定してコマンドを実行していますが、この部分には手順4を実行した際のバックアップIDを指定してください(バックアップIDはSTART BACKUP実行後の出力からも確認可能。バックアップID 3の場合の出力例「Node 2: Backup 3 started from node 1 completed」)。
リスト6・手順5:スレーブへのデータリストア例
$ # スレーブへデータをリストア(「-c localhost:1187」はスレーブの管理ノードを指定) $ ndb_restore –c localhost:1187 –n 2 –b 3 –r –m –no-binlog /home/mysql/mysqlc/data/data1/BACKUP/BACKUP-3 $ ndb_restore -c localhost:1187 -n 3 -b 3 -r -e --no-binlog /home/mysql/mysqlc/data/data2/BACKUP/BACKUP-3
6. スレーブのndb_apply_statusテーブルからスレーブに反映済みのEpochを確認する
スレーブのSQLノードに接続し、リスト7の手順でndb_apply_statusからスレーブに反映済みのEpochを確認します。リスト7の例では、反映済みのEpochが8834747727871になっています。
リスト7・手順6:スレーブへ反映済みのEpochを確認
$ # スレーブのSQLノードに接続して実行(ポート:3308はスレーブのSQLノード1) $ mysql -u root -h 127.0.0.1 -P 3308 -e "SELECT MAX(epoch) FROM mysql.ndb_apply_status;" 8834747727871
7. マスターのndb_binlog_indexテーブルからマスターのバイナリログ情報を確認する
マスターのndb_binlog_indexテーブルから、先ほどスレーブで確認したEpoch以降のバイナリログファイル名/ポジションを確認します。手順4のオンラインバックアップ取得以降にマスターでトランザクションが実行されていないと、対応するバイナリログファイル名/ポジションが確認できないため、リスト8では先にマスターでトランザクションを実行してからndb_binlog_indexテーブルを検索しています(トランザクションが実行されていない場合は、オンラインバックアップ取得以降のEpochの情報がndb_binlog_indexテーブルに追記されていないため、リスト8のSQLで対応するバイナリログファイル名/ポジションが特定できない)。
リスト8・手順7:ndb_binlog_indexテーブルから対応するバイナリログファイル名/ポジションを確認
$ # マスターのSQLノード1に接続して実行 mysql> INSERT INTO world.City VALUES(10005,'TEST','JPN','TEST',0); Query OK, 1 row affected (0.03 sec) mysql> SELECT File,Position,epoch FROM mysql.ndb_binlog_index WHERE epoch>8834747727871 ORDER BY epoch ASC LIMIT 1; +-----------------+----------+---------------+ | File | Position | epoch | +-----------------+----------+---------------+ | ./binlog.000007 | 120 | 9019431321605 | +-----------------+----------+---------------+ 1 row in set (0.00 sec)
8. レプリケーションの設定を行う(スレーブでCHANGE MASTER TOコマンドを実行)
スレーブのSQLノードに接続して、先ほど確認したマスターのSQLノードへの接続方法、バイナリログのファイル名、バイナリログポジションを指定してレプリケーションの設定を行います。リスト9では、マスターのSQLノード1のバイナリログファイルbinlog.000007、バイナリログファイルポジション120を指定してコマンドを実行しています(手順7で確認したバイナリログファイル名、ポジションを指定)。
リスト9・手順8:レプリケーションの設定(CHANGE MASTER TOコマンドを実行)
$ # スレーブのSQLノードに接続して実行 mysql> CHANGE MASTER TO MASTER_HOST='localhost', MASTER_USER='repl', MASTER_PASSWORD='repl', MASTER_PORT=3306, MASTER_LOG_FILE='binlog.000007', MASTER_LOG_POS=120;
9. レプリケーションを開始する(スレーブでSTART SLAVEを実行)
スレーブのSQLノードに接続してリスト10のようにSTART SLAVEを実行し、レプリケーションを開始します。
リスト10・手順9:レプリケーションの開始
$ # スレーブのSQLノードに接続して実行 mysql> START SLAVE;
レプリケーションの稼働確認
レプリケーション環境が構築できたら、マスターでデータを更新し、更新内容がスレーブに伝搬されることを確認してください。リスト11では、マスターのworld.Cityテーブルにデータを追加し、そのデータがスレーブでも検索できることを確認しています。
リスト11: レプリケーションの稼働確認例
$ # マスターのworld.Cityテーブルの件数を確認(ポート:3306はマスターのSQLノード1) $ mysql -u root -h 127.0.0.1 -P 3306 -e "SELECT COUNT(*) FROM world.City;"; +----------+ | COUNT(*) | +----------+ | 4079 | +----------+ $ # スレーブのworld.Cityテーブルの件数を確認(ポート:3308はスレーブのSQLノード1) $ mysql -u root -h 127.0.0.1 -P 3308 -e "SELECT COUNT(*) FROM world.City;"; +----------+ | COUNT(*) | +----------+ | 4079 | +----------+ $ # マスターのworld.CityテーブルへデータをINSERT(ポート:3306はマスターのSQLノード1) $ mysql -u root -h 127.0.0.1 -P 3306 -e "INSERT INTO world.City VALUES(10001,'TEST','JPN','TEST',0);" $ # スレーブのworld.Cityテーブルの件数を確認(ポート:3308はスレーブのSQLノード1) $ mysql -u root -h 127.0.0.1 -P 3308 -e "SELECT COUNT(*) FROM world.City;"; +----------+ | COUNT(*) | +----------+ | 4080 | +----------+ $ # スレーブのworld.CityテーブルからデータをSELECT(ポート:3308はスレーブのSQLノード1) $ mysql -u root -h 127.0.0.1 -P 3308 -e "SELECT * FROM world.City WHERE ID=10001;"; +-------+------+-------------+----------+------------+ | ID | Name | CountryCode | District | Population | +-------+------+-------------+----------+------------+ | 10001 | TEST | JPN | TEST | 0 | +-------+------+-------------+----------+------------+
おわりに
今回は、MySQL Clusterにおけるレプリケーション環境構築の具体例について解説しました。第9回では、MySQL Clusterのチューニングの基礎について解説する予定です。
※本稿において示されている見解は、私自身の見解であって、私の所属するオラクルの見解を必ずしも反映したものではありません。
- この記事のキーワード
この記事をシェアしてください
バックナンバー
この記事の筆者

筆者の人気記事
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
