なぜKubernetesが必要なのか?
連載の第1回目は、概観やKubernetesによって、何が実現できるのかを解説する。
2018年2月7日 6:00
はじめに
Kubernetesはコンテナ化されたアプリケーションの展開、スケーリング、および管理を自動化するためのプラットフォーム(コンテナオーケストレーションエンジン)です。本連載では、Kubernetesを触ったことがない方でもKubernetesのコンセプトを理解し、実際にアプリケーションをコンテナ化して実行することが出来るようになることを目標としています。
ここ数年でDockerを皮切りにコンテナ技術への注目度が非常に高まり、実際にプロダクションでのコンテナ利用事例も増えてきました。プロダクション利用に耐えうるシステムを構築するにはDockerだけでは難しいため、Kubernetesに代表されるコンテナオーケストレーションエンジンとよばれるプラットフォームを利用することが一般的です。Kubernetesの他にもDocker SwarmやDC/OSなどもありますが、執筆時(2018年1月)ではKubernetesがデファクトスタンダードとなっています。

Kubernetesのロゴ
Kubernetesの歴史
Kubernetesは、Googleの社内で利用されていたコンテナクラスタマネージャの「Borg」をアイデアの元にして作られたOSSです。2014年6月にローンチされ、2015年7月にバージョン1.0となったタイミングでLinux Foundation傘下のCloud Native Computing Foundation(CNCF)に移管されました。CNCFには著名な開発者、エンドユーザ、大手クラウドプロバイダなどのベンダーが参加しており、現在はCNCFが主体となり中立的な立場で開発が進められています。執筆時点での最新バージョンは1.9となっておりますが、1.7の時点でProduction-Readyと宣言されています。
Kubernetesがデファクトスタンダードとなったと言える背景として、大手クラウドプロバイダーの対応があります。2014年11月頃にGoogle Cloud Platform(GCP)がいち早くGoogle Container Engine(GKE、後のGoogle Kubernetes Engine)の提供を開始しました。マネージドKubernetesを利用するにはGKE一択でしたが、2017年2月にはMicrosoft AzureもAzure Container Service(AKS)をリリース、2017年11月にはAmazon Web Service(AWS)もAmazon Elastic Container Service for Kubernetes(Amazon EKS)をリリースし、大手クラウドプロバイダのマネージドKubernetesが出揃いました。
Kubernetesを使うと何が出来るのか
Dockerを利用することでホスト上にコンテナを立ち上げることができますが、プロダクションで利用しようとすると下記のようなことを考えなければなりません。
- 複数のDockerホストの管理
- コンテナのスケジューリング
- ローリングアップデート
- スケーリング / オートスケーリング
- コンテナの死活監視
- 障害時のセルフヒーリング
- サービスディスカバリ
- ロードバランシング
- データの管理
- ワークロードの管理
- ログの管理
- Infrastructure as Code
- その他エコシステムとの連携や拡張
コンテナオーケストレーションエンジンであるKubernetesを利用することで、これらの課題を解決することができます。もしKubernetesを利用しない場合には、これらの自動化の仕組みをゼロから作り上げる必要があり、現実的ではありません。従来の仮想マシンの場合には、AWS CloudFormationやOpenStack Heatなどを使って自動化などを行っていた部分に通ずるものもあります。KubernetesでもYAMLでマニフェストを書くことで、実行するコンテナなどを宣言的なコードにより管理します。
リスト1:Kubernetesのマニフェストの例
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: sample-deployment
spec:
replicas: 3
selector:
matchLabels:
app: sample-app
template:
metadata:
labels:
app: sample-app
spec:
containers:
- name: nginx-container
image: nginx:latest
ports:
- containerPort: 80
Kubernetesは、複数のDockerホストを管理してコンテナクラスタを構築します。また、コンテナをKubernetes上で実行する際には、同じコンテナのレプリカとして展開することで負荷分散や耐障害性の確保をすることが可能です。さらに負荷に応じて、コンテナのレプリカ数を増減(オートスケーリング)することもできます。
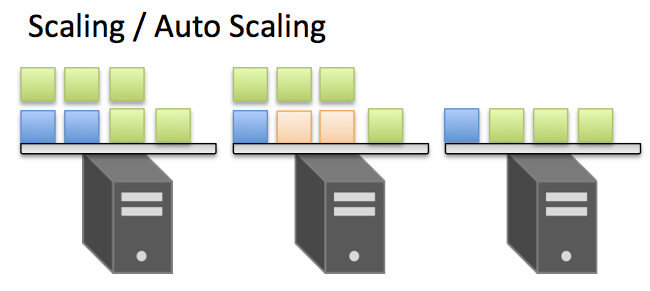
スケーリングのイメージ
コンテナを配置する際には、「ディスクI/Oが多い」「特定のコンテナとの通信が多い」といったようなワークロードの種類や、「ディスクがSSD」「CPUのクロック数が高い」といったような Dockerホストの種類によって、affinityやanti-affinityを意識したスケジューリングを行うことも可能です。また、GCP/AWS/OpenStack上などに構築している場合には、Dockerホストにアベイラビリティーゾーンなどの付加情報が付与されているため、簡単にマルチリージョンにコンテナを配置することが可能です。
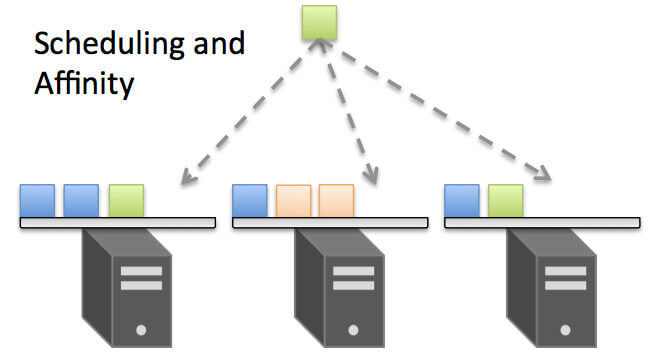
スケジューリングのイメージ
特別な指定がない場合には、CPUやメモリの空きリソースの状況に従ってスケジューリングが行われるため、ユーザはどのDockerホストに配置するかなどを管理する必要がありません。さらにリソースが不足している場合には、Kubernetesクラスタのオートスケーリングなども行うことも可能です。
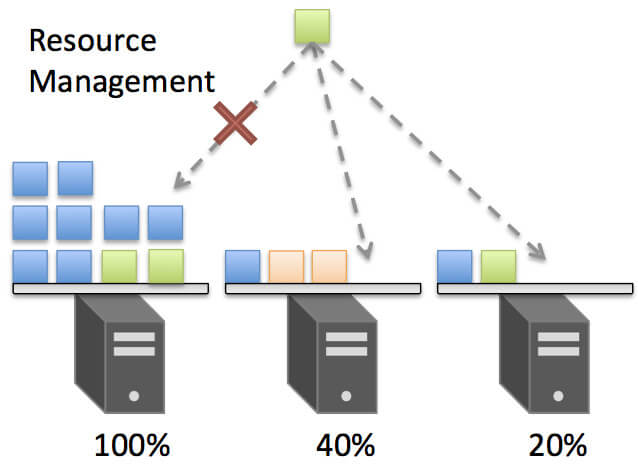
リソース管理のイメージ
耐障害性という観点では、Kubernetesは標準でコンテナのプロセス監視を行います。万が一コンテナのプロセスが停止した際には、再度コンテナのスケジューリングを実施することでセルフヒーリングを行います。セルフヒーリングはKubernetesにとって重要なコンセプトの一つであり、クラスタのノード障害やノード退避などを行った際にも、サービスに影響なく自動復旧させるように作られています。さらにプロセス監視以外にも、HTTP/TCP・シェルスクリプトによるヘルスチェックを設定することも可能です。
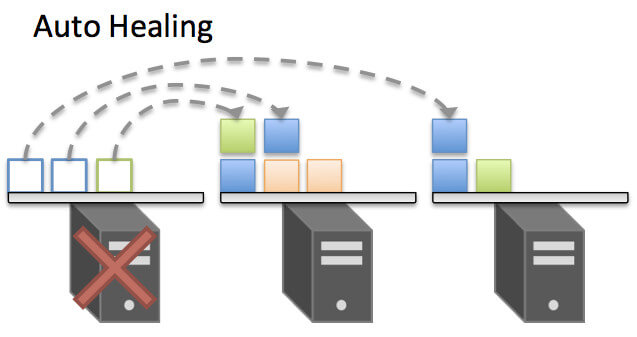
オートヒーリングのイメージ
コンテナをスケーリングさせた場合、コンテナへのエンドポイントの問題が発生します。仮想マシンの場合には、ロードバランサを設定することでVIPとしてエンドポイントを払い出していました。Kubernetesも同等の機能(Service)を有しており、特定のコンテナ群に対するロードバランシング機能を提供します。スケール時の自動追加や削除はもちろんのこと、コンテナ障害時には自動で切り離したり、コンテナのローリングアップデート時にも事前に自動で切り離してくれるため、SLAの高いエンドポイントの管理をKubernetesに任せることが可能です。
また、Dockerを使ってシステムを構築する場合には、各機能を細分化して実装するマイクロサービスアーキテクチャにすることが多いかと思います。マイクロサービスアーキテクチャでは、機能ごとに作成されたコンテナイメージを使ってデプロイするため、サービスディスカバリの機能も必要となってきます。先ほど説明したServiceの機能を利用することで、サービスディスカバリを行うことも可能となっています。
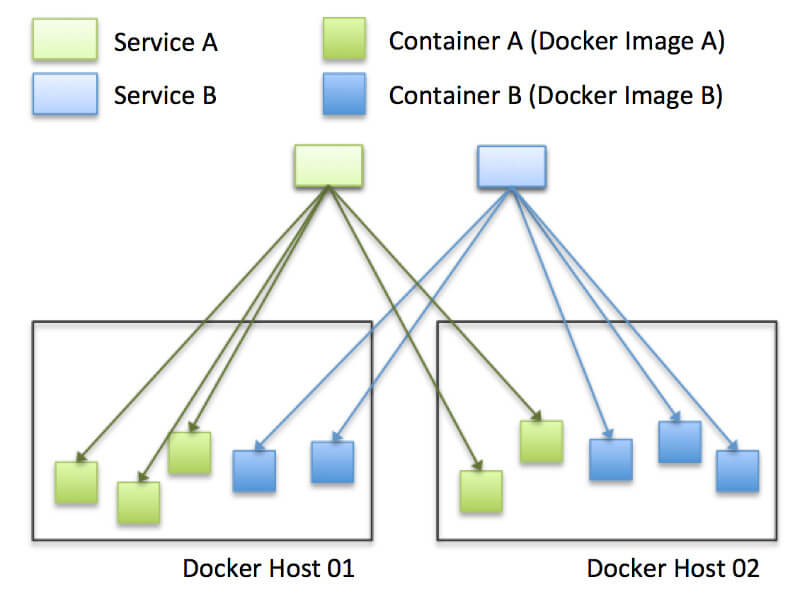
Serviceのイメージ
Kubernetesでは保有するコンテナやServiceのデータは、バックエンドのetcdに保存されるアーキテクチャとなっています。このetcdを利用して、設定ファイルや認証情報などのデータを安全かつ冗長化された状態で保存する仕組みも用意されています。そのため、コンテナで共通の設定や様々なアプリケーションから利用されるデータベースのパスワードなどの情報をKubernetesクラスタに集中管理することが可能です。
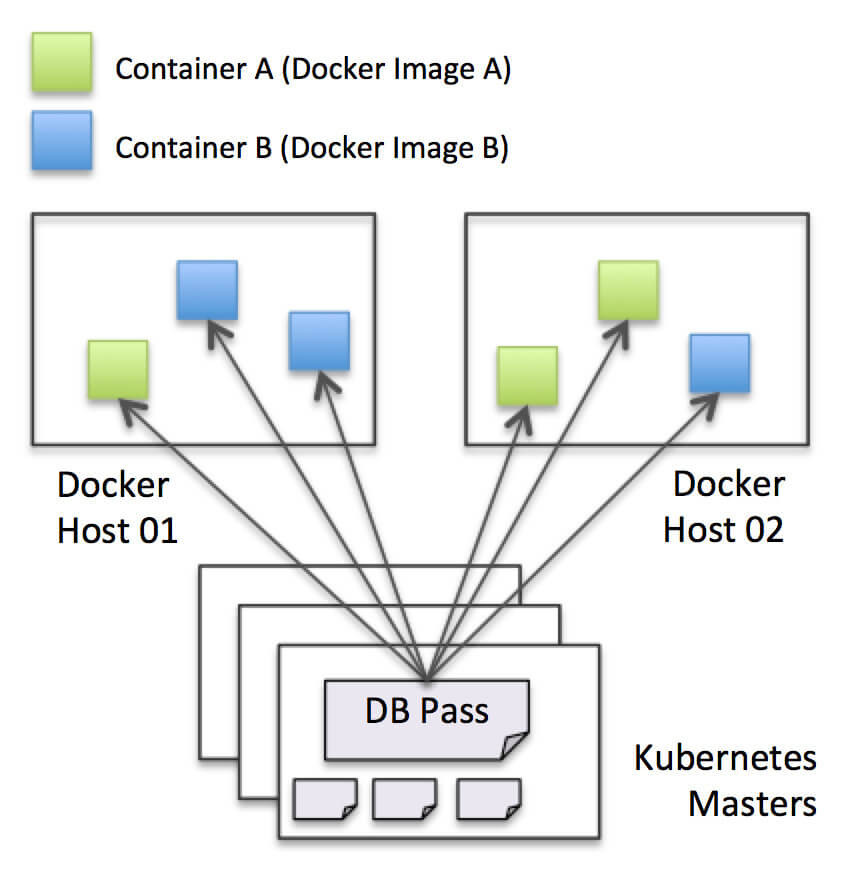
データ保存のイメージ
Kubernetesは一つのプラットフォームですが、外部のエコシステムとの連携も盛んに行われています。多くのミドルウェアがKubernetesをサポートする流れとなっており、今後も加速していくでしょう。
- Ansible:Kubernetesへのコンテナのデプロイ
- Apache Ignite:KubernetesのService Discoveryを利用して自動でクラスタ形成とスケーリング
- Fluentd:Kubernetes上のコンテナのログを転送
- Jenkins:Kubernetesへのコンテナのデプロイ
- OpenStack:クラウド連携したKubernetesを構築
- Prometheus:Kubernetesの監視を行う
- Spark:jobをKubernetes上でNative実行(YARN代替)
- Spinnaker:Kubernetesへのコンテナのデプロイ
- その他多数
また、Kubernetesには機能の拡張を行う仕組みがいくつか用意されており、独自の機能などを実装したり、プラットフォーム自体をフレームワークとして利用することも可能となっています。拡張性を利用することで、Kubernetesで扱うことが出来るReplicaSetなどのリソースを独自実装することも可能です。
まとめ
今回はKubernetesの概要を紹介しましたが、いかがでしょうか?
Kubernetesなどのオーケストレーションエンジンを使わずにDockerをプロダクション環境で利用するには、ここまで説明したような機能を自分たちで作り込む必要が出てきてしまいます。しかしKubernetesを利用すれば、Borgを生み出した先人たちが考えた自動化の仕組みを利用できます。従来のVMでこういった自動化を行う場合には、CloudFormationを使ったり、ロードバランサを操作するような仕組みを作ったり、アプリケーションのアップデートの仕組みを整備する必要がありましたが、Kubernetesを使うことでコンテナのポータビリティや軽量さを活かしながら高サイクルな開発を実現可能です。
次回は「Kubernetes環境の選択肢」についてご説明する予定です。
- この記事のキーワード
この記事をシェアしてください
バックナンバー
この記事の筆者

筆者の人気記事
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
