はじめに
前回に引き続き、今回もコンテナマネジメントのデファクトスタンダードといわれる「Kubernetes」について、Kubernetesで用いる様々なタイプのリソースを紹介します。
Manifest
Kubernetesでは各種リソース構成や実行するコンテナイメージなどをYAML形式で記述します。それが“Manifest”と呼ばれるファイルです。ManifestにKubernetesクラスタの「望ましい状態」を事前に定義し、マスターノードに登録して管理することで、インフラのコード化とも言われる「Infrastructure as Code」を実現しています(図1)。
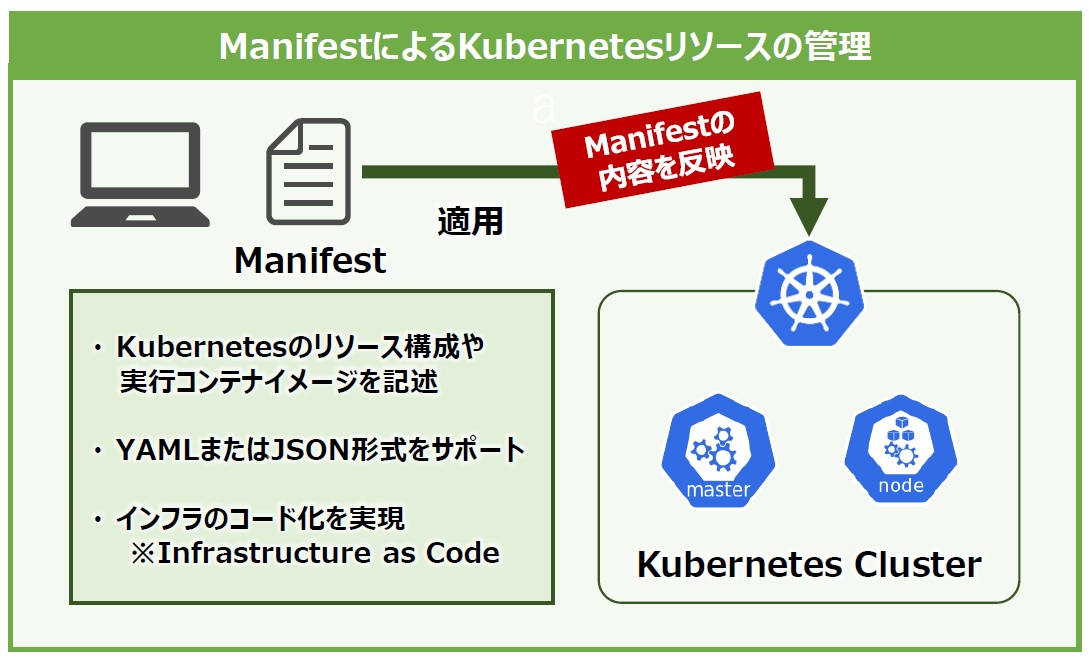
図1:Manifestを用いたKubernetesリソースの管理
Kubernetesの中で働くリソース
Kubernetesのリソースとは、Kubernetesの中にコンテナを作り、アプリケーションを動かすための部品です。外部のネットワークへコンテナを公開するまでには、様々な種類のリソースを駆使することになります。
ここで、リソースを大きく特徴ごとに分類して紹介していきます。前回も登場したPodを中心にコンテナの配置や動かし方により異なる「コンピュート」、データの永続的化に欠かせないデータを保管する「ストレージ」、外部からのアクセスに欠かせないIngressをはじめとする「ネットワーク」があります(図2)。
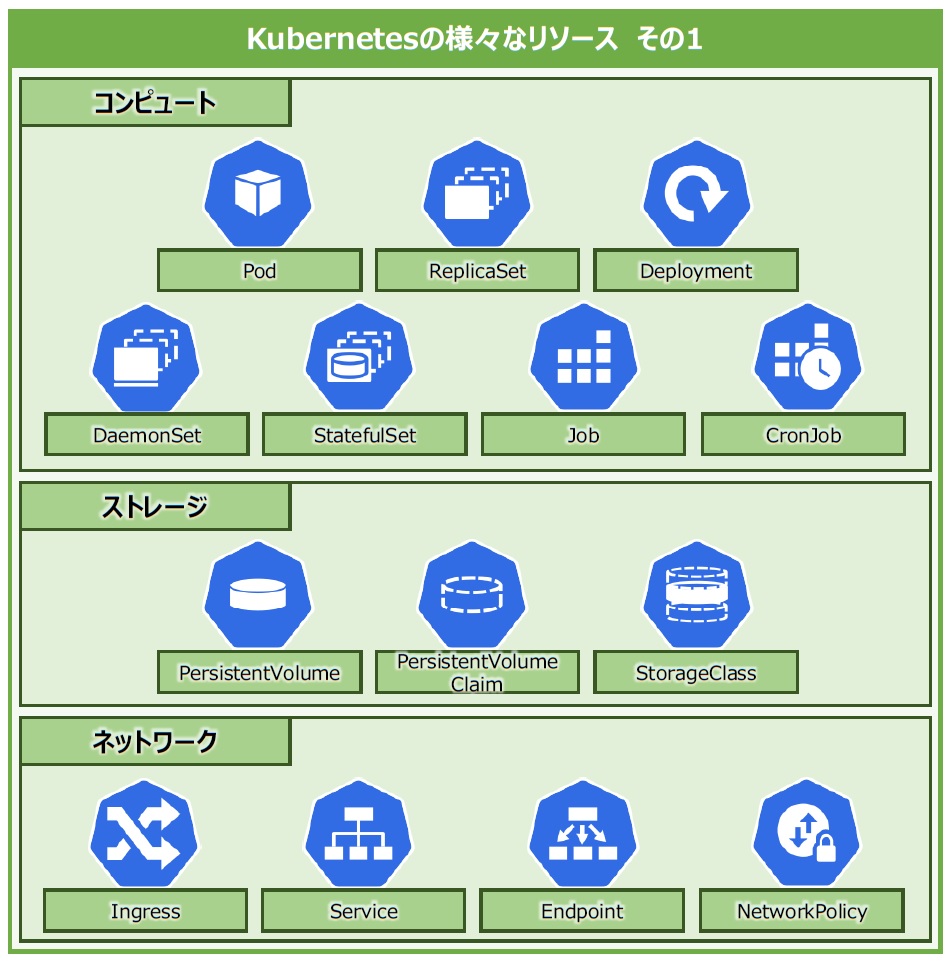
図2:Kubernetesの様々なリソースその1
他にも、Kubernetesクラスタ上のリソースへのアクセスを制御し、セキュリティの堅牢性を担保する「アクセス制御」、Podの中で用いる情報の一部を外部へ出力する「Pod設定」、Kubernetesクラスタを安全に扱うための「クラスタ設定」、上記に分類されない特殊な「その他」など、数多くのリソースを活用できます(図3)。リソースには分類できませんが、多種多様なリソースの管理を容易にするため、名前を付けることもできます。
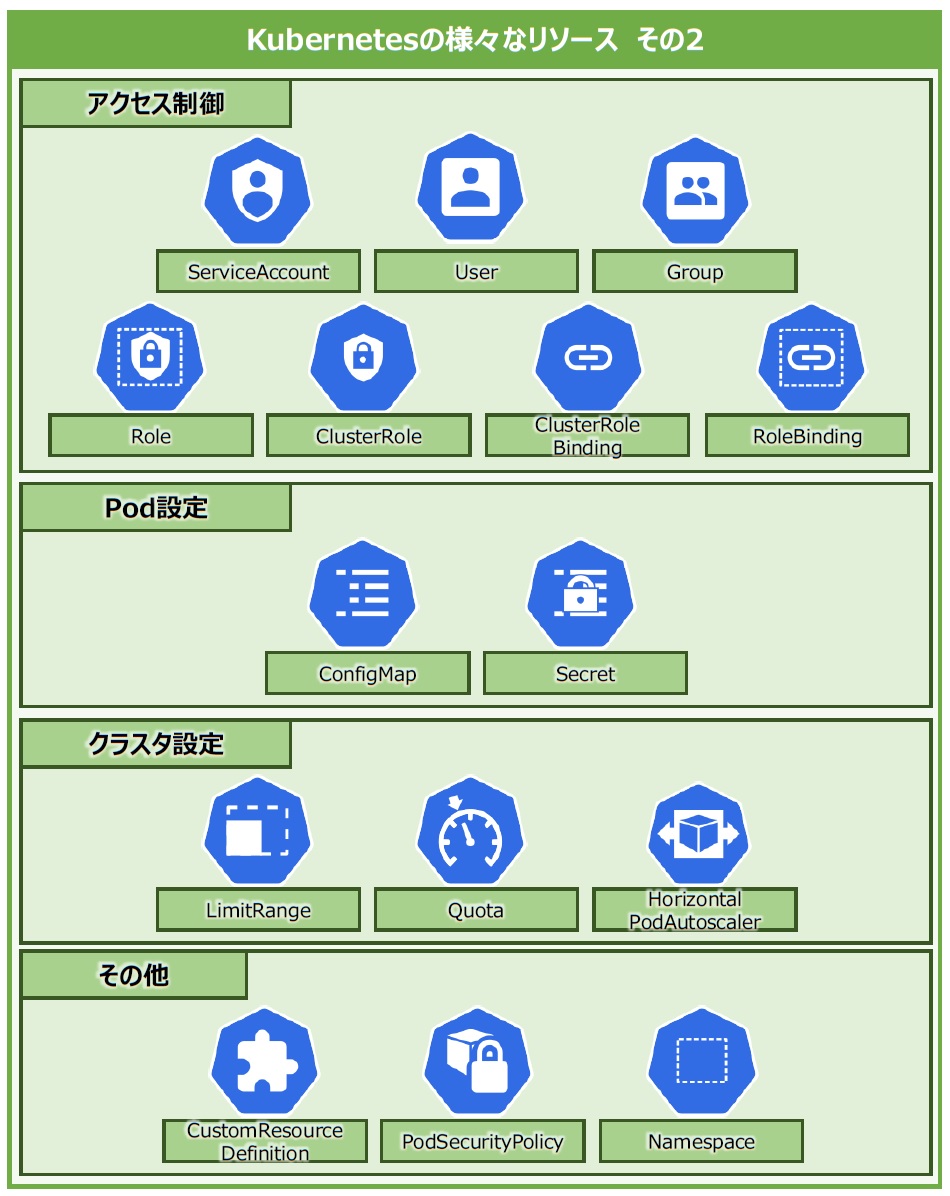
図3:Kubernetesの様々なリソースその2
LabelとSelector
KubernetesではPodやService、Deployment(後述)など様々なリソースを多数作成して管理できますが、数が増えれば増えるほど、どのリソースがどのような用途を想定したものかを把握することは困難になります。そこで用いられるのが「Label」と「Selector」です。
LabelはPodなどのリソースをグループ化します。Selectorはグループ化された特定のリソースを使用する際に指定します。少し分かり辛いと思いますので、ここで1つ例え話をしましょう。
スーパーマーケットの食料品売り場を思い浮かべてみてください。人参や玉ねぎ、じゃがいもは”青果”、鶏肉・牛肉・豚肉は”精肉”、アジやサケは”鮮魚”など、それぞれ売り場が分かれていますよね。このように、種別などでグループ化することがLabelの役割です。
もちろん、グループ分けは食材の種別に限らず、人参・じゃがいも・玉ねぎ・牛肉を”カレー”グループにするなど、用途で分けるような使い方もあります。もし”カレー”グループの食材を必要としているならば、Selectorを使用すると良いでしょう。”カレー”グループをSelectorで指定すれば、様々な食材の中から簡単に目的の食材を選択・購入できます(図4)。

図4:Labelによるリソースのグループ化とSelectorによるLabel選択
Kubernetesでは、リソースの種類やアプリケーションの用途などに応じてLabelとSelectorでグループ化することで、複雑化していく環境をシンプルにできます。
ここからは、特に重要なリソースを紹介していきます。
Namespace
Namespace(第2回でも紹介)は、様々なコンピュータリソースを分離・独立し、お互いの干渉を防ぐためのLinuxカーネルの機能です。
同様に、KubernetesのNamespaceも複数のワーカーノードを横断して「kubernetesリソース」の分離と独立を制御できます(図5)。
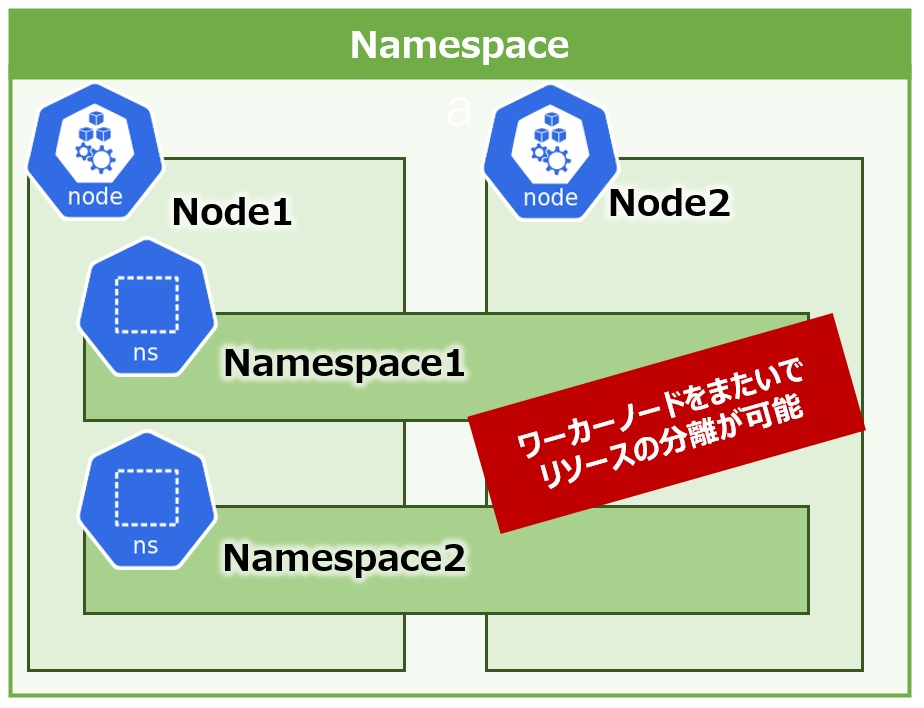
図5:Namespaceによるリソース分離
他のリソースに干渉されず安全にコンテナを動かすためには、まず独自のNamespaceを作り、コンテナを配置するところからはじまるのです。
また、Kubernetesには環境を作成した時点で3つのNamespaceが用意されています。
- default:特にどのNamespaceに配置するかを決めていないリソースのためのデフォルト用
- kube-system:Kubernetesが作成したコンポーネント(前回で紹介)や管理用のリソース用
- kube-public:Kubernetesにアクセスする全ユーザーが利用できるように意図的に配置したリソース用
特にkube-systemは重要です。Kubernetesを管理するための管理用のコンテナはここに配置していきます(管理用のコンテナにはkubeletやkube-proxyなどを含む)。
Pod
Kubernetesでは、各ノードに直接コンテナを起動するのではなく、Podという単位で(アプリケーションの)コンテナを実行していきます。
Podには固有の仮想IPアドレスが割り当てられ、Pod内のコンテナはIPアドレスやポート、ネットワーク名前空間をそれぞれ共有するという特徴があります。そのため、Pod内に複数のコンテナが存在する場合、コンテナは自身を指定することで(localhost指定)お互いに通信できるのです。
Podのもう1つの特徴はボリュームも共有できることです(後述)。より正確には、Podに共有化されたストレージボリュームを指定することで、Pod内の全てのコンテナがそのストレージにアクセスできるようになるというものです(図6)。
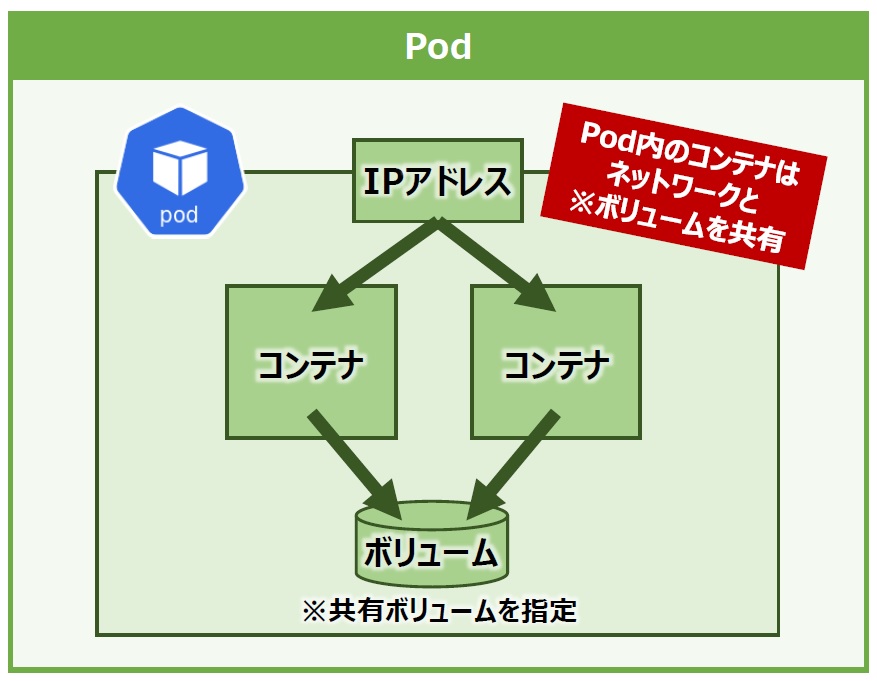
図6:Pod内コンテナのリソース共有
Podの使い方で特に意識しておきたい点があります。第3回で「1コンテナ1プロセス」の考え方を紹介しましたが、Podとその中のコンテナに対しても同様に「1Pod1コンテナ」構成が一般的とされています。
しかし、1Pod1コンテナではないパターンもあります。IPアドレスやボリュームなどを同一Pod内のコンテナで共有しコンテナ間で密に連携するようなアプリケーションの場合は、1つのPodに複数のコンテナを収めたほうが良いでしょう(図7)。一部のPodが別のノードに配置された場合にコンテナが連携できなくなるなどの影響を抑止できます。
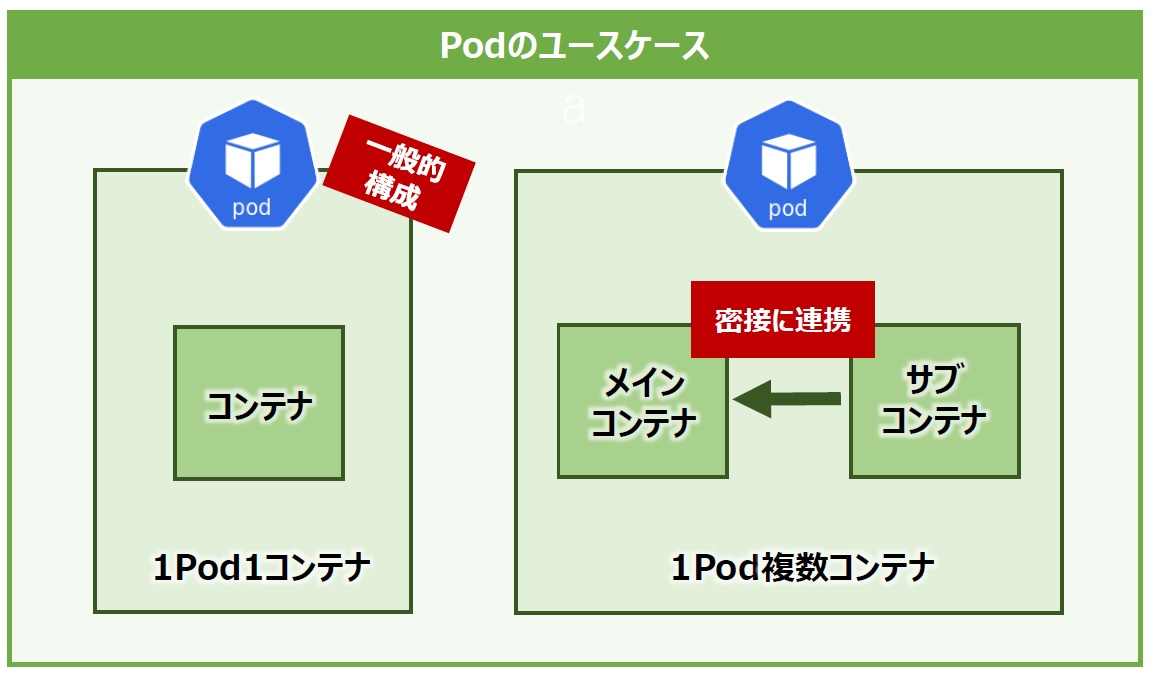
図7:Podの様々なユースケース

ReplicaSet
KubernetesクラスタではノードやPodに障害が発生しても、Podを他のノードに自動で配置し直すなど、事前に定義した状態をできると解説しました。これをKubernetesの世界では「セルフヒーリング(Self-Healing)」と言います。
セルフヒーリングを最もイメージしやすいのが”ReplicaSet”です。ReplicaSetはどのような時でも事前に指定した数のPodを維持します。例えば、あるアプリケーションを動作させるPodがあり、管理者はReplicaSetで常に同じPodを2つ維持してほしいと定義します。稼動中、何らかの障害で片方が停止すると、ReplicaSetはすかさず同じPodを新規に作成します(図8)。また、ノードに障害が発生し両方のPodが停止した場合でも、事前に定義した数を満たすため、新規で別のノードにPodを作成します。
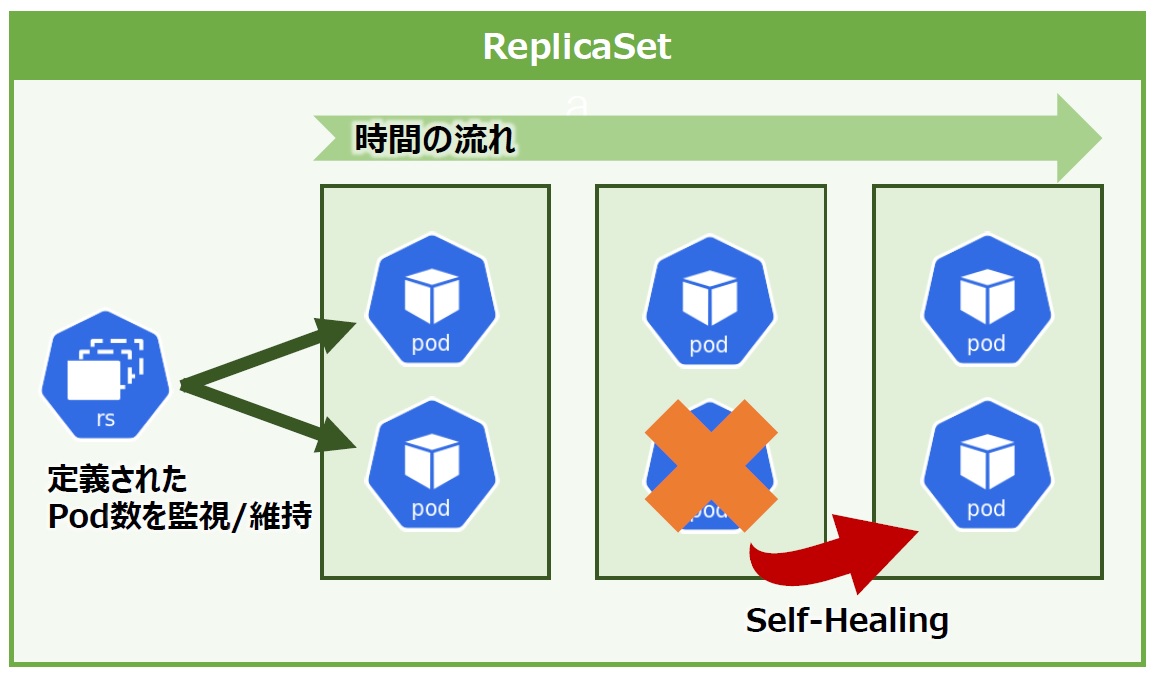
図8:ReplicaSetによるSelf-Healing
このように、ReplicaSetはPod数を監視することで、障害が発生しても事前に定義した必要数を満たしてくれます。また、事前に定義するPod数を後から増減することもできます。例えば、必要なPod数を2つから4つに変更すると2つのPodが追加作成され、以後は4つの状態を維持します。
Deployment
DeploymentはReplicaSetを管理して、ローリングアップデートやロールバックを実現します。DeploymentとReplicaSetの関係性を整理すると、ReplicaSetはPod数を管理し、DeploymentはそのReplicaSetを管理します。ちなみに、ローリングアップデートとは、簡単に言うと少しずつ(全体ではなく1台ずつのイメージ)新しい物に入れ替えるアップデート方法です。
先のスーパーマーケットの例で言うと、ある商品のパッケージが新しくなり、棚にある古い商品を新しい商品に入れ替える必要性があるとしましょう。その際に、古い商品を一度に全て入れ替えるのがReplicaSet単体でPodを管理した場合の挙動です。一方で、古い商品の奥に新しい商品を置き、古い商品が陳列棚から1つ消えたら新しい商品の補充を繰り返し、最終的に全て新しい商品に入れ替えるのがDeploymentによるローリングアップデートです(図9)。なお、ロールバックはその逆で、少しずつ元に戻す方法です。
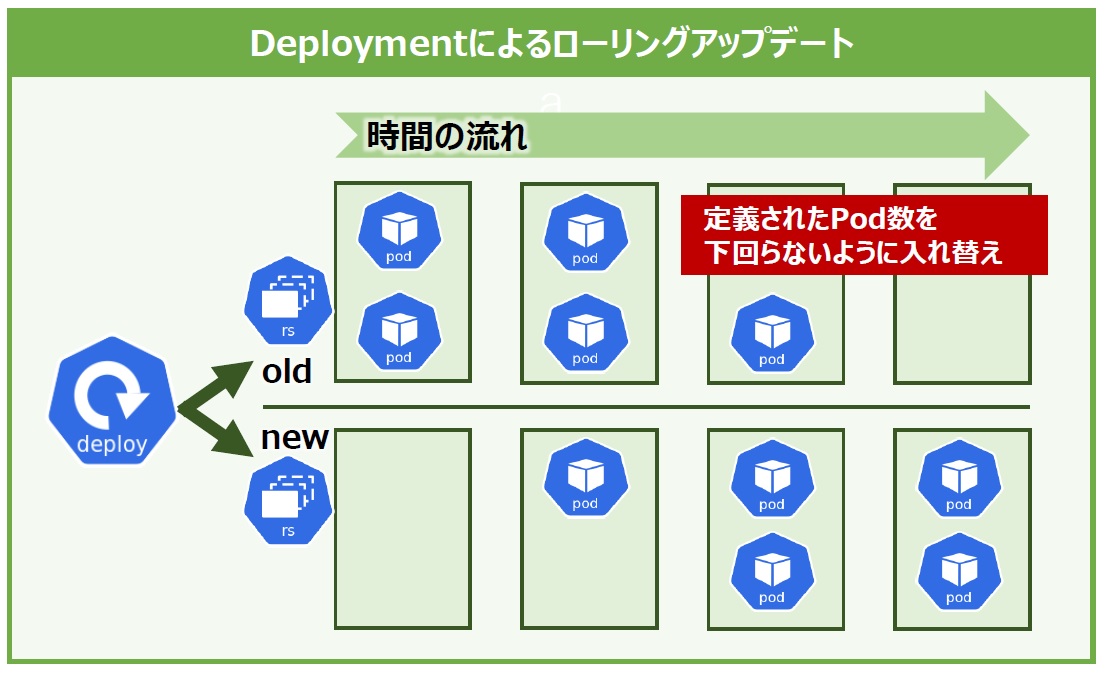
図9:DeploymentによるPodのローリングアップデート
ReplicaSetの入れ替えでは一時的に棚が空になりますが、Deploymentのローリングアップデートでは商品が少しずつ入れ替わるため棚が空にならないというメリットがあります。つまり、アプリケーションに接続できない状態が発生しないということになります。

Service
前回でも少し触れましたが、ServiceはKubernetesのクラスタ内外からのPod宛の通信を仮想IPアドレスで振り分けてくれるリソースです。この仮想IPアドレスには、Kubernetesクラスタ内の通信を振り分けできる”ClusterIP”、クラスタ外のロードバランサーに仮想IPアドレスを紐付けできる”LoadBalancer”、特定のKubernetesノードのIPアドレスとポートからの通信を振り分ける”ExternalIP”など、複数の種類があります。
そもそも、なぜServiceが必要なのでしょうか。何かしらの障害でPodが停止するとReplicaSetなどによりSelf-Healingされて稼動を継続できるようになっていますが、復活した後のPodに割り振られたIPアドレスが変わってしまい、稼動を停止したPodのIPアドレスにたどり着けず通信が途絶えてしまう問題があります。この問題を解決してくれるのがServiceです。Podの論理セットの前段にServiceというプロダクションを構え、Podへアクセスするためのポリシーを定義し、リクエストを受け付けるロードバランサーの役割を担います。
ターゲットとなるPodは、Serviceで定義するLabelとSelectorにより決められます。”カレー”の話を思い出してください。シーフードカレーとビーフカレーがあるとして、シーフードカレーの気分ならManifestというおしゃれなメニューに書いてServiceに伝えることで、魚介の旨味たっぷりなシーフードカレーを提供してくれます(図10)。
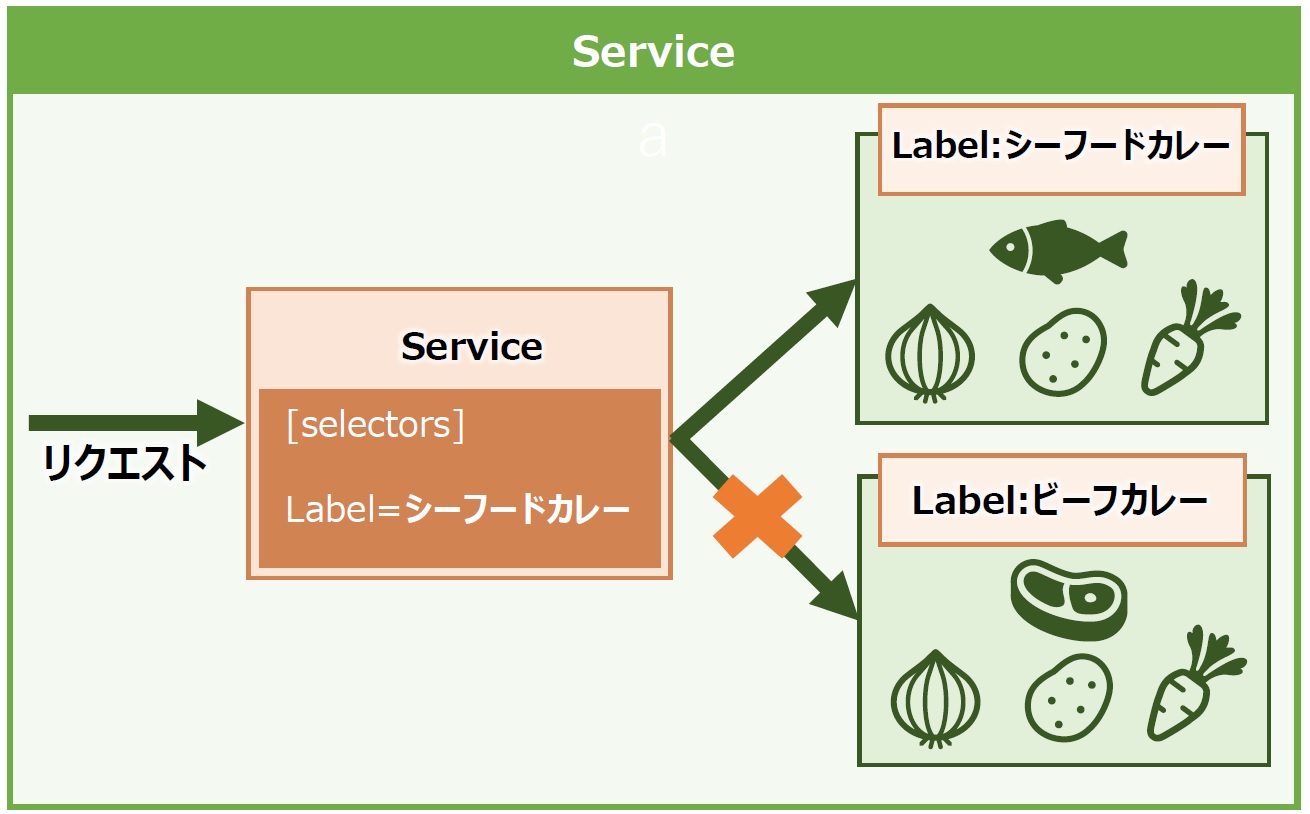
図10:ServiceによるLabel選択
Manifestファイルで定義するServiceには4種類あります。デフォルトの「ClusterIP」はクラスタ内にServiceを公開する場合に使用します。クラスタ外からアクセスできるようにしたい場合は「Nodeport」を使用します。AWSやGCPなどのクラウドサービスと連携する場合は「LoadBalancer」、外部のサービスにエイリアスを提供する「ExternalName」という特殊なServiceもあります。
Serviceには”サービスディスカバリ”機能があるのも特徴の1つです。Kubernetesにおけるサービスディスカバリは、例えばServiceとLabelで紐付いたPodが別のノードに再配置されても、通信の振り分け先のPodを検索・判別してくれる機能です。判別方法にも複数ありますが、代表的なのがDNSを利用した名前解決方法です。また、Serviceの仮想IPアドレスとポートとIngress(前回で紹介)が払い出すURLとを紐付けることで、レイヤーの違うロードバランシングをそれぞれ実現できます。
PersistentVolume(PV)とPersistentVolumeClaim(PVC)
Podが停止・再配置されてもアプリケーションの状態を維持するため、Podからマウントする永続なストレージボリュームが必要になります。Kubernetesではそれを確保するために「PersistentVolume(PV)」と「PersistentVolumeClaim(PVC)」というリソースを提供しています。
PVはPodのデータを保存する永続ストレージの本体で、PVCは必要なストレージ容量を動的に確保する抽象化したストレージです。
ConfigMap
ConfigMapはPodやコンテナの設定値と設定ファイルを保存するためのリソースです。Podの実行時に必要な環境変数、ポート番号などの構成要素をConfigMapによりPodから分離して保存することでワークロードの移植性が向上し、構成の管理や変更が楽になります(図11)。

図11:ConfigMapを用いたPodの設定情報の分離および保存

おわりに
今回は、Kubernetesの論理的な構成に関する要素を紹介しました。Kubernetesクラスタを管理する上では、豊富にあるリソースの特徴を理解し、その用途を把握する必要があることを覚えておきましょう。クラスタ内で稼動させるアプリケーションによってはStatefulSetによる実行順番を管理したり、今後の更新に備えてDeploymentのローリングアップデート機能を使用したりなど、ユースケースにより利用するリソースの組み合わせは様々です。リソースの特徴と用途を把握しておけば、解決するべき課題に対して利用するリソースを適切に選択できるようになります。
次回もKubernetesについて解説します。全3回に渡り紹介している「コンテナおじさん Kubernetes編」。次回は、Kubernetesの周辺で活躍する各種製品を紹介します。次回もお楽しみに!

この記事をシェアしてください
バックナンバー
この記事の筆者

Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
