コンテナ関連技術の現状を確認しておく
今回は、連載に先駆けてコンテナやオーケストレーションツールといった関連技術の概要をおさらいします。
2020年2月6日 6:00
はじめに
今回から、コンテナのセキュリティについて考えるコラムを始めます。ここで言うコンテナは、OSコンテナではなくアプリケーションコンテナです。
このコラムでは以下の用語を使用します。
- コンテナ(=アプリケーションコンテナ)
- コンテナオーケストレーションツール
コンテナおよびオーケストレーションツールにも複数の実装があります。ここでは、OSSで公開される上記のプロジェクトを対象とします。
Docker以前のコンテナ技術
アプリケーションコンテナの歴史は、いわゆる汎用機の仮想化機能まで遡ります。その後UNIX(およびUNIX like OS)では、概ね以下の順でsystem callや準仮想化(Para-Virtualization)の技術を使ってきました。
- chroot(UNIXおよびUNIX like OS)
- System Call chroot()を使用
- ファイルシステムを分離
- Jail(FreeBSD)
- OSレベルの準仮想化実装
- プロセス空間を分離
- ファイルシステムを分離
- OpenVZ/Virtuozzo(Red Hat Enterprise Linux)
- OSレベルの準仮想化実装
- プロセス空間を分離
- ユーザグループを分離
- ファイルシステムを分離
- ネットワークを分離
- 親OSのデバイスを使用可能
- Solaris Zone(Solaris 10/11、OpenSolaris派生OS)
- OSレベルの準仮想化実装
- プロセス空間を分離
- ユーザグループを分離
- ファイルシステムを分離
- ネットワークを分離
- 親OSのデバイスを使用可能
chroot以外は、OSの準仮想化としてのリソース分離です。これらの技術には、以下の共通点が挙げられます。
- カーネルは親OSのカーネルを使用する
- 親OSから子OSのリソースはアクセス可能
- 子OSから親OS、子供OSから子供OSからのリソースは分離されている
- 作成が難しい
- ディレクトリに実行ファイルおよび関連ファイルを集める必要がある(chroot/jail)
- ベースOSの構築が基本(OpenVZ/Solaris Zone)
- 子OSの自由なコピーや、別マシンでの動作は難しい
- ネットワークは親のリソースを使うか、仮想化する必要がある
Docker
Dockerはアプリケーションコンテナです。そのため、以下の特徴を持ちます。
- cgroup/Linux User Namespaceで、リソース(CPU/メモリ/ストレージ/ネットワーク)を分離する
- コンテナはカーネルを持たない
- コンテナ内の処理は、Dockerホスト上のカーネルで(system callを使用)で実施する
- コンテナのプロセス・ストレージは、他コンテナから見ることができない
- ネットワークはブリッジを通して接続する
- コンテナ自体に恒久性がある
Dockerを利用したシステムの構造は、以下の図のようになります。
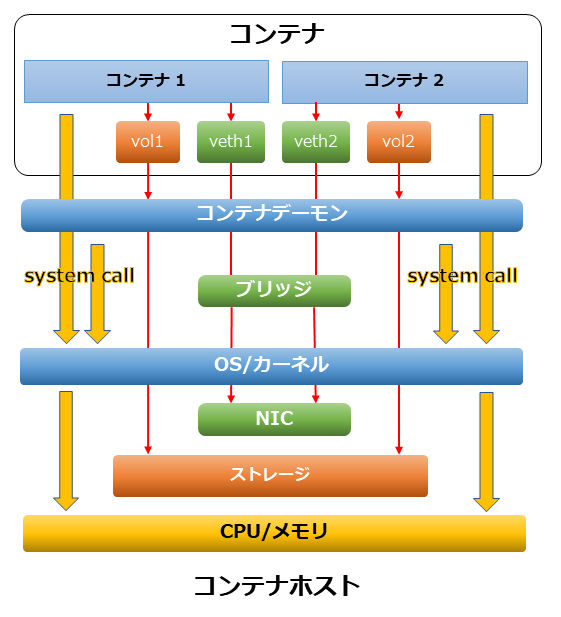
Dockerを利用したシステムの構成図
コンテナの成り立ち
アプリケーションコンテナであるDockerは、概ね以下の手順でコンテナを生成します。
- Dockerグループ権限のIDで「docker run Dockerイメージ」コマンドを実行
- dockerコマンドは、コンテナ生成をコンテナデーモン(containerd)に依頼
- コンテナデーモンはDockerイメージが手元にない場合、Docker RegistryからDockerイメージを取得(pull)
- コンテナデーモンはLinux User Namespaceを作成
- 仮想NICとDockerイメージを展開するためのボリュームを作成し、上記Namespaceに追加
- 同じLinux User Namespace内で、Dockerイメージを展開
- 仮想NICを、コンテナデーモンで作成済みのブリッジ経由で物理NICに接続
- コンテナイメージで指定されたコマンドを実行
- Linux User Namespaceをcgroupで制限する
イメージ
Docker はDockerイメージで配布されます。Docker CEでは、DockerHubがデフォルトで設定されています。このDockerHubなどのDockerイメージを配布しているサイトを、「Docker registry」と呼びます。Docker registryには多数のDockerイメージが登録されています。ただし、Docker registryに登録されているDockerイメージを不用意に使用するのは危険です。Dockerが提供する公式イメージや、Dockerイメージを作成するためのDockerfileを確認できるものを使用しましょう。
Dockerイメージは、Dockerfileを使用してdocker buildコマンドで作成できます。このとき、コンテナホストにDockerイメージが作成されます。また既存のDockerイメージを基に、新たなDockerイメージを作成することも可能です。これは、Dockerイメージがレイヤ構造を持つからです。以下は、ある言語で書かれたアプリケーションをDockerイメージにする例です。

Dockerイメージの簡単な構成図
Dockerイメージは、上にレイヤを積んでいきます。このレイヤは、docker inspectコマンドで確認できます。Dockerイメージ内で使用しているレイヤは、「sha256 checksum」で確認できます。
- ベース
- コンテナのベースになるレイヤ(なくても構いません)
- UNIX likeな環境の場合、上位のレイヤで使用する最低限のコマンドが必要になる
- Busybox、Alpine Linux、Debian GNU/Linuxなどをベースにすることが多い
- 言語
- スクリプトを含む、言語で書かれた実行形式を実行する
- 実行形式に必要な実行形式・ライブラリ・設定ファイルなどが置かれる
- 言語ライブラリ
- アプリケーションに必要な言語ライブラリ・設定ファイルが置かれる
- アプリケーション
- 実際に実行したい実行形式
言語、言語アプリケーションのレイヤは、ミドルウェアである場合もあります。例えば、ベース+言語を積み重ねたDockerイメージを作成・配布することができます。そして、それをベースにしたアプリケーション+言語ライブラリのDockerイメージを作成できます。
ベース+言語のイメージは、Docker公式イメージとして配布されていることがありますので、それをベースに必要なアプリケーションを作ることができます。一方、イメージ構築時のみ必要なファイルは、他のレイヤを追加する前に消しておかないと、後で消すことができません。これはDockerイメージ肥大化の、主要原因になります(Dockerイメージは再配布することが前提なので、小さいサイズであることが求められます)。
作成したDockerイメージは、Docker registryに配信(push)できます。また、独自にDocker registryを作成できます。
プロセス
コンテナ内プロセスは、カーネル上の機能(cgroup/Linux User Namespace)で他コンテナから分離されます。
cgroup
cgroupはControl Groupの略で、プロセスなどをグループ化します。このグループ化されたプロセスをcgroupと呼びます。cgroupでは、ホストOSが持つリソース(CPU/メモリなど)を制限できます。
cgroupを使用するためには、cgroupfsという仮想ファイルシステムが必要です。仮想ファイルシステムはカーネルやソフトウェアの情報をファイルとして扱う仕組みで、「/proc」がよく使用されます。通常cgroupは、/sys/fs/cgroup以下にマウントされます。Ubuntu 18.04 LTSでは、以下のようにマウントされています。
リスト1:cgroupの例(Ubuntu 18.04 LTS)
$ mount | grep cgroup
tmpfs on /sys/fs/cgroup type tmpfs (ro,nosuid,nodev,noexec,mode=755)
cgroup on /sys/fs/cgroup/unified type cgroup2 (rw,nosuid,nodev,noexec,relatime,nsdelegate)
cgroup on /sys/fs/cgroup/systemd type cgroup (rw,nosuid,nodev,noexec,relatime,xattr,release_agent=/usr/lib/systemd/systemd-cgroups-agent,name=systemd)
cgroup on /sys/fs/cgroup/rdma type cgroup (rw,nosuid,nodev,noexec,relatime,rdma)
cgroup on /sys/fs/cgroup/net_cls,net_prio type cgroup (rw,nosuid,nodev,noexec,relatime,net_cls,net_prio)
cgroup on /sys/fs/cgroup/devices type cgroup (rw,nosuid,nodev,noexec,relatime,devices)
cgroup on /sys/fs/cgroup/cpuset type cgroup (rw,nosuid,nodev,noexec,relatime,cpuset)
cgroup on /sys/fs/cgroup/memory type cgroup (rw,nosuid,nodev,noexec,relatime,memory)
cgroup on /sys/fs/cgroup/blkio type cgroup (rw,nosuid,nodev,noexec,relatime,blkio)
cgroup on /sys/fs/cgroup/cpu,cpuacct type cgroup (rw,nosuid,nodev,noexec,relatime,cpu,cpuacct)
cgroup on /sys/fs/cgroup/perf_event type cgroup (rw,nosuid,nodev,noexec,relatime,perf_event)
cgroup on /sys/fs/cgroup/hugetlb type cgroup (rw,nosuid,nodev,noexec,relatime,hugetlb)
cgroup on /sys/fs/cgroup/freezer type cgroup (rw,nosuid,nodev,noexec,relatime,freezer)
cgroup on /sys/fs/cgroup/pids type cgroup (rw,nosuid,nodev,noexec,relatime,pids)
cgroupは、生成されたコンテナ上のプロセスを1つのcgroupとして扱います。そのため、コンテナ単位でPID/CPU/メモリ使用量/ネットワークを制限できます。
Linux User Namespace
コンテナ内のプロセスは、Linux User Namespaceの機能によりプロセス空間が分離されます。そのため、コンテナ内から見た場合、プロセスIDは1から始まるように見えます。しかし、コンテナホストから見ると、別のプロセスIDがついています。
以下のようにコンテナを起動した場合、root権限でshというプロセスが起動します。以下のとおりコンテナ内でコンテナホストのプロセスは見えません。
リスト2:コンテナ内ではコンテナホストのプロセスを見ることはできない
$ docker run -it --rm alpine sh
Unable to find image 'alpine:latest' locally
latest: Pulling from library/alpine
Digest: sha256:2171658620155679240babee0a7714f6509fae66898db422ad803b951257db78
Status: Downloaded newer image for alpine:latest
/ # ps -aef
PID USER TIME COMMAND
1 root 0:00 sh
6 root 0:00 ps -aef
ホスト側でshのプロセスを探すと、shがrootプロセスで起動しています。
リスト3:ホスト側からの見え方
$ ps -aef | grep -w sh | grep -v -e docker -e grep
root 7865 7841 0 19:10 pts/0 00:00:00 sh
プロセスのUIDは、コンテナ起動時に指定することも可能です。以下の例では、UIDを2000に指定して起動させています。
リスト4:UIDを指定してコンテナを起動
$ docker run -it --rm -u 2000 alpine sh
/ $ ps -aef
PID USER TIME COMMAND
1 2000 0:00 sh
6 2000 0:00 ps -aef
リスト5:ホスト側からの見え方
$ ps -aef | grep -w sh | grep -v -e docker -e grep
2000 10051 10028 0 19:16 pts/0 00:00:00 sh
同時に複数のコンテナを起動した場合、あるコンテナから他のコンテナのプロセスは見えません。
リスト6:2つめのコンテナを起動
$ docker run -it --rm -u 3000 alpine sh
/ $ ps -aef
PID USER TIME COMMAND
1 3000 0:00 sh
6 3000 0:00 ps -aef
リスト7:1つめのコンテナを確認
$ ps -aef
PID USER TIME COMMAND
1 2000 0:00 sh
7 2000 0:00 ps -aef
ホストからは、2つのコンテナ上のプロセスが両方とも見えます。
リスト8:ホストからは2つのコンテナ上のプロセスが見える
$ ps -aef | grep -w sh | grep -v -e docker -e grep
2000 10051 10028 0 19:16 pts/0 00:00:00 sh
3000 11290 11265 0 19:19 pts/0 00:00:00 sh
コンテナで動作するアプリケーションは、dockerコマンドが起動しているわけではありません。dockerコマンドはcontainerdなどのコンテナデーモンに依頼して、コンテナを作成しているだけです。
リスト9:dockerコマンドはコンテナの作成までを実施
$ pstree -psu 10051
systemd(1)───containerd(1853)───containerd-shim(10028)───sh(10051,2000)
$ pstree -psu 11290
systemd(1)───containerd(1853)───containerd-shim(11265)───sh(11290,3000)
$ ps -ael | awk 'NR==1 {print} /containerd/ { print }'
F S UID PID PPID C PRI NI ADDR SZ WCHAN TTY TIME CMD
4 S 0 1853 1 0 80 0 - 448645 - ? 00:39:55 containerd
0 S 0 10028 1853 0 80 0 - 27275 - ? 00:00:00 containerd-shim
0 S 0 11265 1853 0 80 0 - 26923 - ? 00:00:00 containerd-shim
このように、コンテナ内のプロセスはcontainerdの子プロセス(containerd-shim)によって生成され、UIDを変更して動作しています。
アプリケーション
コンテナ内で動作するアプリケーションは、1つだけ起動することが推奨されています。アプリケーションがfork()/multi-threadで動作することや、アプリケーションからコマンドを動かすことは許容されます(著者の見解が含まれます)。これは、コンテナイメージに不要なものを持ち込まないために必要です。
アプリケーションのプロセスは非特権ユーザ、つまりroot権限以外で動作させることが推奨されています。コンテナ内で動作するプロセスのUIDは、コンテナホストでも同じUIDとして見えます。これは、Linux User Namespaceにも書いたとおりです。コンテナホスト内のroot権限で動くプロセスは、セキュアとは言えません。
ストレージ
Dockerイメージが必要とするストレージを、ボリューム(Volume)と呼びます。Dockerイメージで使用するボリュームは、コンテナデーモンがコンテナホスト上に用意します。そしてコンテナは、そのボリュームをoverlayマウントします。
リスト10:ボリュームのマウントのされ方
$ mount
overlay on / type overlay (rw,relatime,lowerdir=/var/lib/docker/overlay2/l/4LVLPLLJLBCIBFSRXQU2IKI7VH:/var/lib/docker/overlay2/l/5V6BJWMIMVO43JTUJPDJFGXFLZ,upperdir=/var/lib/docker/overlay2/2ad47f18290ae8fe4953cb2ecbac56b648cb745bcaae77505bf99a1b7650cc0b/diff,workdir=/var/lib/docker/overlay2/2ad47f18290ae8fe4953cb2ecbac56b648cb745bcaae77505bf99a1b7650cc0b/work,xino=off)
proc on /proc type proc (rw,nosuid,nodev,noexec,relatime)
(中略)
tmpfs on /sys/fs/cgroup type tmpfs (ro,nosuid,nodev,noexec,relatime,mode=755)
cgroup on /sys/fs/cgroup/systemd type cgroup (ro,nosuid,nodev,noexec,relatime,xattr,release_agent=/usr/lib/systemd/systemd-cgroups-agent,name=systemd)
(中略)
cgroup on /sys/fs/cgroup/pids type cgroup (ro,nosuid,nodev,noexec,relatime,pids)
mqueue on /dev/mqueue type mqueue (rw,nosuid,nodev,noexec,relatime)
shm on /dev/shm type tmpfs (rw,nosuid,nodev,noexec,relatime,size=65536k)
/dev/mapper/ubuntu--vg-root on /etc/resolv.conf type xfs (rw,relatime,attr2,inode64,noquota)
/dev/mapper/ubuntu--vg-root on /etc/hostname type xfs (rw,relatime,attr2,inode64,noquota)
/dev/mapper/ubuntu--vg-root on /etc/hosts type xfs (rw,relatime,attr2,inode64,noquota)
devpts on /dev/console type devpts (rw,nosuid,noexec,relatime,gid=5,mode=620,ptmxmode=666)
proc on /proc/bus type proc (ro,relatime)
(中略)
tmpfs on /proc/scsi type tmpfs (ro,relatime)
tmpfs on /sys/firmware type tmpfs (ro,relatime)
以下のファイルは、コンテナホスト側のファイルをマウントします。
- resolv.confなど一部の設定ファイル
- /proc
- /cgroup
この特徴のため、コンテナ上のファイルはコンテナ終了時に消えてしまいます。消えてはいけないファイルは、恒久的ボリューム(以下PV)に配置します。PVには通常「コンテナボリューム」という仕組みを利用します。これはコンテナホスト上に作成したディレクトリを使用します。ファイル名がハッシュ化されているので、探すのは大変です。また、コンテナボリュームの特定ディレクトリをマウントすることもできます。これらのPVは、ブロックストレージと言うよりファイルストレージとして使われます。
ネットワーク
containerdでは、「docker0」というブリッジが作成されます。コンテナ起動時に仮想NIC(Virtual Network Interface Card)が生成され、ブリッジdocker0に繋がります。実際にコンテナ上のネットワーク設定を見ると、コンテナ側のNICはコンテナ上でしか見えず、そのIPアドレスはdocker0と同じネットワーク帯です。
コンテナ側ネットワーク:
リスト11:コンテナ側から見たネットワーク
# ip addr show
43264: eth0@if43265: <BROADCAST,MULTICAST,UP,LOWER_UP,M-DOWN> mtu 1500 qdisc noqueue state UP
link/ether 02:42:ac:11:00:02 brd ff:ff:ff:ff:ff:ff
inet 172.17.0.2/16 brd 172.17.255.255 scope global eth0
valid_lft forever preferred_lft forever
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
コンテナホスト側ネットワーク:
リスト12:コンテナホスト側から見たネットワーク
# ip addr show | grep 172.17.
inet 172.17.0.1/16 brd 172.17.255.255 scope global docker0
何も指定しない限り、コンテナホストからコンテナへ接続することはできません。しかし、コンテナ内からコンテナ外への接続は可能です。
リスト13:コンテナ内から外への接続は可能
/ # nslookup thinkit.co.jp
Server: 192.168.10.64
Address: 192.168.10.64#53
Non-authoritative answer:
Name: thinkit.co.jp
Address: 202.218.13.185
/ # ping -c3 thinkit.co.jp
PING thinkit.co.jp (202.218.13.185): 56 data bytes
64 bytes from 202.218.13.185: seq=0 ttl=53 time=23.078 ms
64 bytes from 202.218.13.185: seq=1 ttl=53 time=21.062 ms
64 bytes from 202.218.13.185: seq=2 ttl=53 time=21.077 ms
--- thinkit.co.jp ping statistics ---
コンテナ内へネットワーク接続をするには、コンテナホストにポートフォワードによりポートを割り当てるしかありません。コマンドdocker run -p 80:80 nginxでは、コンテナ内でLISTENしている80番ポートをコンテナホストの80番ポートにポートフォワードします。
Dockerの優位性
Dockerの優位性をまとめると以下のとおりです。
- コンテナホストのカーネルを使用する
- 完全仮想化(Full Virtualization)で使用されるハイパーバイザの分のリソースを消費しない
- Dockerイメージを使用することによる可搬性の高さ
- Dockerイメージを自由にpush/pullできる
- 動作させるために必要なものは、Dockerイメージに入っている
- DockerfileによりDockerイメージを使用することによる再現性、安全性の高さ
- コンテナに含まれているものは、Dockerfileで確認できる
- この記事のキーワード
この記事をシェアしてください
関連記事
バックナンバー
この記事の筆者

筆者の人気記事
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
