Metrics / Logs / Traces & Tool
Metrics / Logs / Traces & Tool
ここからは、メトリクス、ログ、トレースについてツールと合わせて詳しく見ていきます。
Metrics
メトリクスとは「CPU使用率やメモリ使用量などを特定の時間間隔で測定し統計した数値データ」と先に説明しました。ある一時点の事実としてのデータであるため、経時的に測定する必要があります。また、よく利用される方法として閾値を設けて、その閾値を超えた場合にアラートを出して通知する方法も用いられます。メトリクスの主な例としてはCPU・メモリ使用率、リクエスト数、ネットワーク通信量です。
メトリクス監視を始める上で、収集するメトリクスを何にすべきか戸惑う場合があります。もちろん、システムによるケースバイケースもありますが、リソースをベースとした「USE」とサービスをベースとした「RED」というメトリクス取集の指標があります。また『SREサイトリライアビリティエンジニアリング』という書籍では、The Four Golden Signalsとして4つのメトリクスを挙げています。合わせて表で整理します。
| 指標 | 概要 |
|---|---|
| USE |
Utilization : リソースの単位時間あたりの使用率(例:CPU、メモリの使用率等) Saturation : リソースの飽和状況(例:実行キューの長さ等) Error : エラーイベントのカウント(例:ネットワーク、 I/O のエラーなどをカウント) |
| RED |
Rate(Request) : 秒間のリクエスト数 Error : 失敗しているリクエスト数 Duration : リクエストの処理に要した時間 |
| The Four Golden Signals |
Latency : リクエストを処理するのに要した時間。正常なレスポンスと異常なレスポンスは分けるようにする Traffic : システムに対するリクエスト量。リクエスト数やネットワーク I/O 、セッション数など Error : 処理の失敗 Saturation : リソースの飽和状況。メモリ、ディスク、CPU や I/O など |
・Prometheus
ここからは、メトリクスを取集するツールを紹介します。発表では、OSS(オープンソースソフトウェア)の1つとしてPrometheusを紹介しました。
PrometheusはPull型のメトリクス監視システムで、Kubernetesとも親和性が高く、サービスディスカバリ機能により監視対象を自動的に見つけることができます。以下、主な特徴です。
- クラスタ全体のリソース監視
- PodごとのCPU、RAM、ネットワーク使用量の監視
- ラベルを利用したメトリクス管理
- メトリクス集約に特化した独自クエリ言語(PromQL)を持つ
Prometheusのアーキテクチャは下図の通りです。
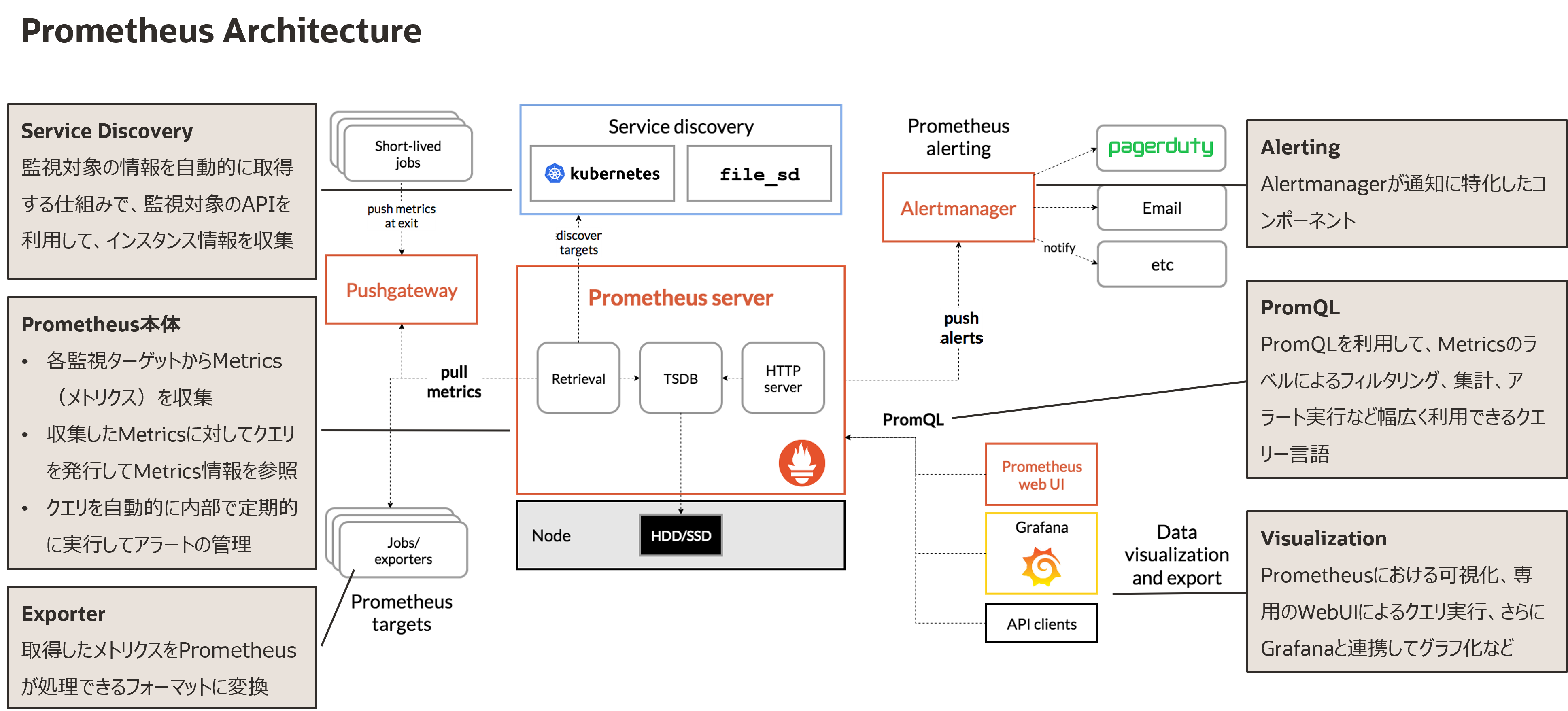
Prometheus Architecture【出典】What is Prometheus?
ここで、メトリクス収集におけるPush型とPull型を整理します。Push型は監視対象システムにエージェントをインストールして、そのエージェントから監視システムにメトリクスを送信します。Pull型は監視システムから監視対象システムのメトリクスを受信します。
PrometheusはPull型で、監視対象システムのExporterという軽量なHTTPサーバにリクエストを送信して、レスポンスを受信する仕組みです。Prometheusにはサービスディスカバリ機能が実装されているため、監視対象のリスト(IPアドレスやポート番号など)を動的に更新して運用への影響を回避できます。

Push型とPull型
・Push型とPull型
Exporterはターゲットが持つ独自形式のメトリクスをExporterが取得して、Prometheusが処理できるフォーマットに変換する役割を担います。

Exporterについて
Podデザインパターンの1つであるアダプタパターンを利用して取得することもできます。

アダプタパターン
また、PrometheusはExporter経由ではなく、アプリケーションにクライアントライブラリを実装することでアプリケーションから直接メトリクスを取得することもできます。
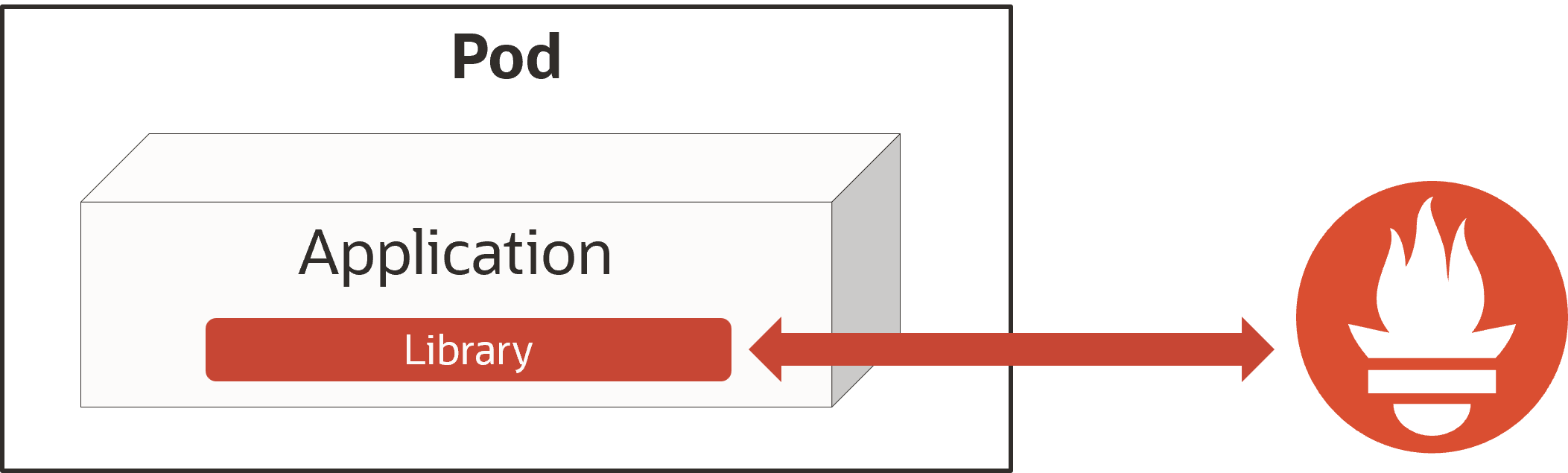
クライアントライブラリの実装
・ラベル管理
ここまで、Promehteusにおけるメトリクス収集の仕組みについて説明してきましたが、ここからは取得するメトリクスを効率的に扱うラベル管理について見ていきます。
Prometheusはメトリクスを区別するためにラベルを利用できます。ラベルは、メトリクス集約に特化した独自クエリ言語であるPromQLを利用して集約対象の絞り込みなどを行えます。ラベルはメトリクスを出力する際に付与されます。主な仕様については下図の通りです。

ラベルによるメトリクス管理
以下は、sample-web-serviceというPodが受けたリクエスト数の10分間平均を求める例です。
rate(http_requests_total{pod=”sample-web-service”}[10m])PrometheusのWeb UIを利用してフォームにPromQLを入力し、実行すると結果を表示できます。メトリクス名、ラベルフィルタリング、正規表現フィルタリングなどが行えます。
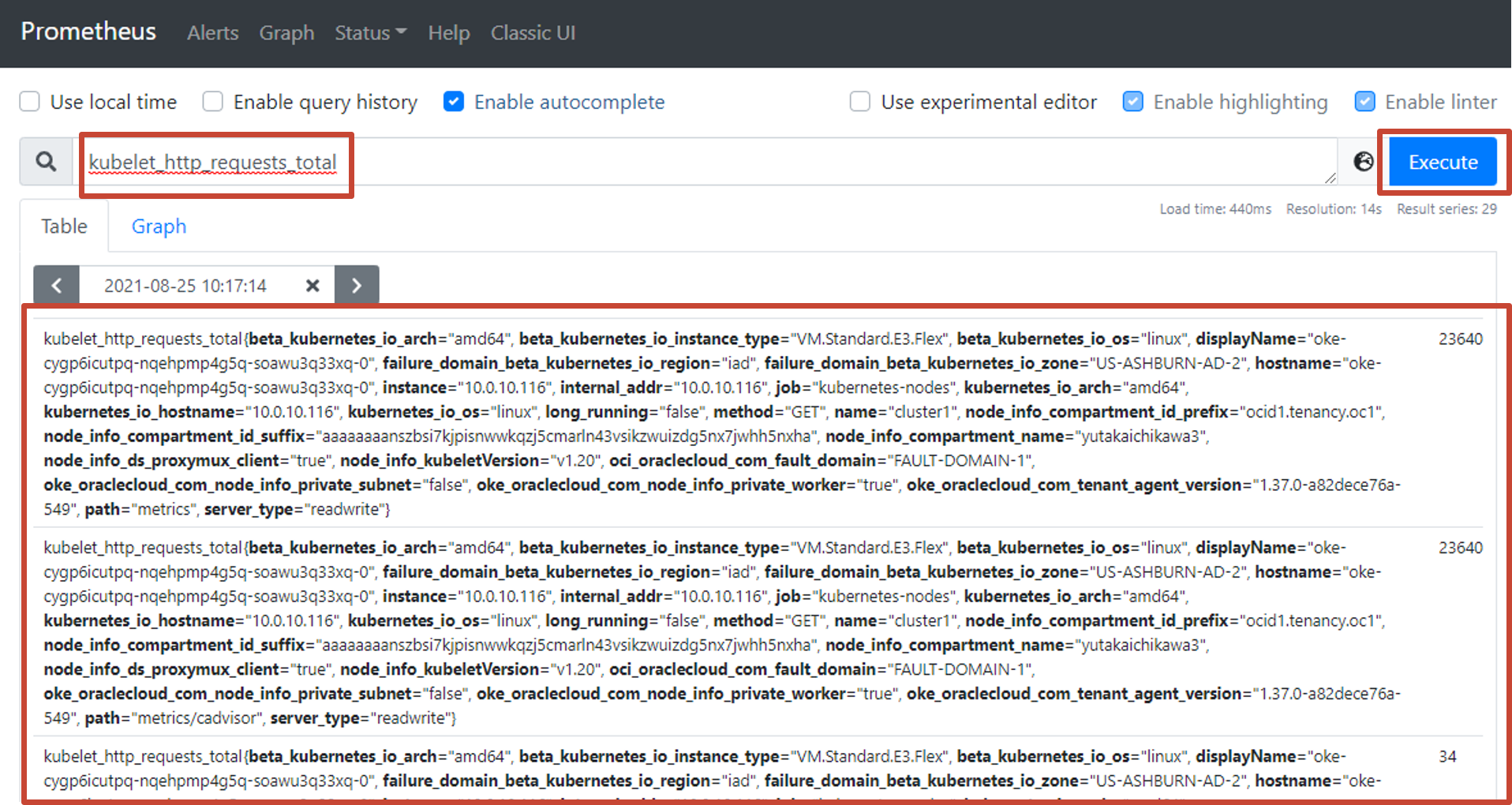
検索例
最後に、Prometheusの通知に関わるAlertmanagerコンポーネントについて見ていきます。
・Alertmanager
Prometheusには通知を実行する機能が実装されていないため、Alertmanagerコンポーネントと連携する必要があります。Alertmanagerコンポーネントの主な特徴は、以下の通りです。
- Alertmanagerは通知に特化したコンポーネント
- 収集したメトリクスにアラートとして発報するルールを設定できる
- ルールはPromQLで設定され、定期的に評価されて条件が満たされるとアラートがAlertmanagerに送信される
- アラートはメールやSlackなどへ通知できる
- 通知間隔、連続通知抑止、グルーピングなど管理できる
- アラート、通知に関するものはPrometheusでなくAlertmanagerで管理

Alertmanager
Prometheusはメトリクスの取集や管理が中心となりますが、その集約したデータを可視化する上でよく一緒に利用されるOSSがGrafanaです。Grafanaについて少し触れておきます。
・Grafana
Grafanaはデータの可視化、監視、およびアラートのためのOSSです。非常にユーザーフレンドリーで、多くのデータソースと連携できます。主な特徴は、以下の通りです。
- データの可視化: Grafanaを使用すると、様々なデータソースから収集したデータを視覚的なダッシュボードに表示できる、ダッシュボードはカスタマイズ可能でグラフ、チャート、表など、さまざまな形式でデータを表示できる
- 多様なデータソースのサポート: GrafanaはPrometheusのようなメトリクスデータだけでなく、InfluxDB、MySQL、PostgreSQLなど多くの一般的なデータベースや時系列データベースに対応
- アラート機能: Grafanaにはアラート機能があり、特定の条件を満たした場合に通知を送ることができる
- カスタマイズと拡張性: ユーザは自分のニーズに合わせてダッシュボードをカスタマイズできる、多数のプラグインを通じて機能を拡張することもできる
- この記事のキーワード
関連記事
Kubernetesアプリケーションのモニタリングことはじめ
2021年10月22日 6:30
Oracle Cloud Hangout Cafe Season5 #3「Kubernetes のセキュリティ」(2022年3月9日開催)
2023年4月18日 6:30
Oracle Cloud Hangout Cafe Season4 #3「CI/CD 最新事情」(2021年6月9日開催)
2023年1月19日 6:30
Kubernetesアプリケーションのトレーシング
2021年11月25日 6:30
Oracle Cloud Hangout Cafe Season4 #4「マイクロサービスの認証・認可とJWT」(2021年7月7日開催)
2023年2月17日 6:30
Oracle Cloud Hangout Cafe Season7 #2「IaC のベストプラクティス」(2023年7月5日開催)
2024年1月18日 6:30
バックナンバー
この記事の筆者

筆者の人気記事
Rancherってどんなもの?
2019年2月27日 6:00
RancherでKubernetesクラスタを作る
2019年3月13日 6:00
Oracle Cloud Hangout Cafe Season4 #3「CI/CD 最新事情」(2021年6月9日開催)
2023年1月19日 6:30
RancherのCatalog機能を詳細に見てみる
2019年3月27日 6:00
Oracle Cloud Hangout Cafe Season5 #3「Kubernetes のセキュリティ」(2022年3月9日開催)
2023年4月18日 6:30
Oracle Cloud Hangout Cafe Season7 #1「Kubnernetes 超入門」(2023年6月7日開催)
2023年12月14日 6:30
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
