| ||||||||||
| 前のページ 1 2 3 | ||||||||||
| データ圧縮 | ||||||||||
データ容量が増えてくるとディスク容量も増大し、それに伴って必要なメモリ容量も増えていきます。大規模なデータベースシステムでは、構成の中でストレージの占める割合というのが増えますが、昨今、HDD1台あたりのディスク容量は増えているので、同じデータ容量でもディスク数が少なくても構成できるようになってきました。さらにCPUの処理能力の技術革新スピードも速いので、一昔前では困難だった長期保存期間のシステムも構築できるようになっています。 ディスク数が少ない構成というのは安価ですがI/Oの処理能力は落ちてしまいます。つまりCPUの処理能力とI/Oの処理能力のバランスが悪い構成になりがちだということです。ディスク制御装置にもキャッシュが多く搭載できるようになってきましたので、オンライン・トランザクション処理のようなヒット率の高いシステムでは問題にはなりません。 しかし大量データを検索するような場合は、メモリ上のキャッシュだけではデータの処理ができないものです。するとディスクへのI/Oがボトルネックになって性能上の問題が浮上します。このようなアンバランスなシステムでは、チューニングが困難なケースも多く見受けられるでしょう。 DB2 9ではデータ圧縮機能により、ディスク容量の大幅削減を実現して圧縮されたままメモリ上のキャッシュであるバッファープールにデータを格納するので、メモリを節約することができます。データが圧縮されることにより、同じページ数を読んでもデータ件数が2倍、3倍と格納できるので、I/O Waitの時間が減って効率的にCPUを活用し、処理時間を短縮することも可能です。 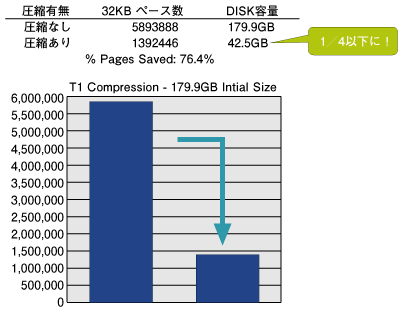 図5:あるお客様での圧縮例 図5のようにデータ容量を1/4まで圧縮できたケースでは、1,600ページ読まなければならないところ、わずか400ページのリクエストだけで済みますので、処理時間のほとんどがI/O Waitのような処理では処理時間短縮も望めます。 つまりデータ圧縮は単にDISK容量を削減してストレージコストを低減させるだけでなく、昨今のCPUの処理能力とI/Oの処理能力のアンバランスさを解消してくれる可能性を持っているのです。 | ||||||||||
| まとめ | ||||||||||
このようにDB2 9では、大規模データベースでもデータ圧縮を利用することでコストパフォーマンスのよいハードウェア構成になり、さらに各種パーティショニング機能を使うことで運用の容易性と性能維持向上をはかることが可能です。そして前回紹介したオートノミックの機能である自動ストレージと組み合わせることによって、要件に合わせた環境を簡単に構築することができることもDB2 9の大きな利点だといえるでしょう。 | ||||||||||
| 前のページ 1 2 3 | ||||||||||
| ||||||||||
| ||||||||||
| ||||||||||
-
人気記事ランキング
-
-
連載


新着記事
NVIDIAら37社が「Open Secure AI Alliance」設立――AIエージェントのセキュリティは重みの非公開では守れない 6:20 【クラウドネイティブ会議】厳格な統制と開発者体験を両立する、Wiz Baseにおけるゴールデンパスの実践 6:00 その「ソーシャルログイン」は大丈夫? OAuth/OIDC実装の3つの落とし穴 7月29日 6:30 KubeCon Europe 2026、新興のオブザーバビリティ企業Hygroundの製品責任者にインタビュー。生成AIの使用を前提にした新世代オブザーバビリティとは 7月29日 6:00 障害発生時でも継続運用を実現する「MySQL」と「PostgreSQL」の「高可用性構成」を理解する 7月28日 6:30